Reinforcement Learning: Teaching Computers to Make Optimal Decisions
Reinforcement learning basics to get your feet wet. Learn the components and key concepts in the reinforcement learning framework: from agents and rewards to value functions, policy, and more.
What Is Reinforcement Learning?
Reinforcement learning is a branch of machine learning that deals with an agent learning—through experience—how to interact with a complex environment.
From AI agents that play and surpass human performance in complex board games such as chess and Go to autonomous navigation, reinforcement learning has a suite of interesting and diverse applications.
Remarkable breakthroughs in the field of reinforcement learning include DeepMind’s agent AlphaGo Zero that can defeat even human champions in the game of Go and AlphaFold that can predict complex 3D protein structure.
This guide will introduce you to the reinforcement learning paradigm. We’ll take a simple yet motivating real-world example to understand the reinforcement learning framework.
The Reinforcement Learning Framework
Let's start by defining the components of a reinforcement learning framework.
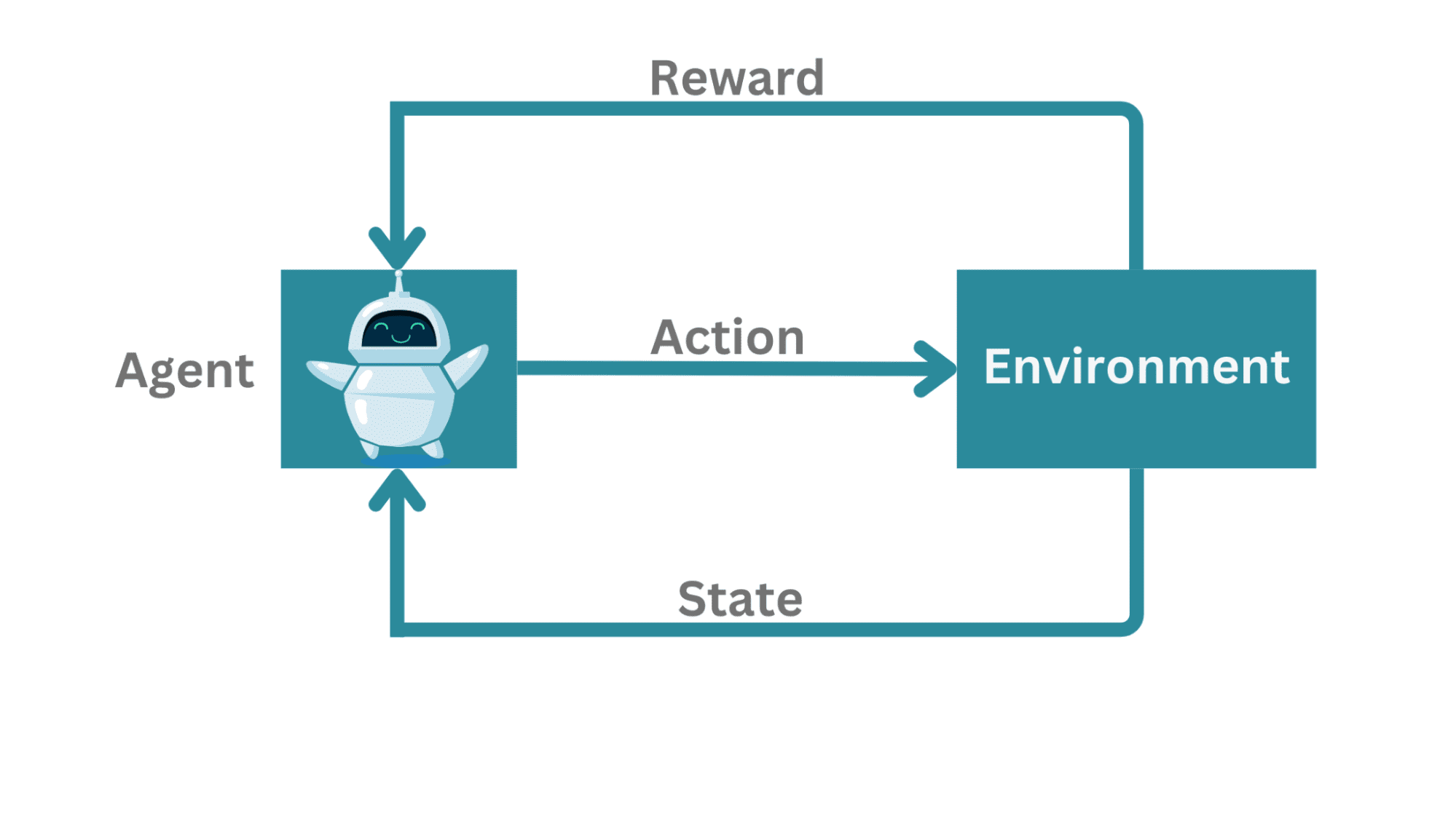
Reinforcement Learning Framework | Image by Author
In a typical reinforcement learning framework:
- There is an agent learning to interact with the environment.
- The agent can measure its state, take actions, and occasionally gets a reward.
Practical examples of this setting: the agent can play against an opponent (say, a game of chess) or try to navigate a complex environment.
As a super simplified example, consider a mouse in a maze. Here, the agent is not playing against an opponent but rather trying to figure out a path to the exit. If there are more than one paths leading to the exit, we may prefer the shortest path out of the maze.

Mouse in a Maze | Image by Author
In this example, the mouse is the agent trying to navigate the environment which is the maze. The action here is the movement of the mouse within the maze. When it successfully navigates the maze to the exit—it gets a piece of cheese as a reward.
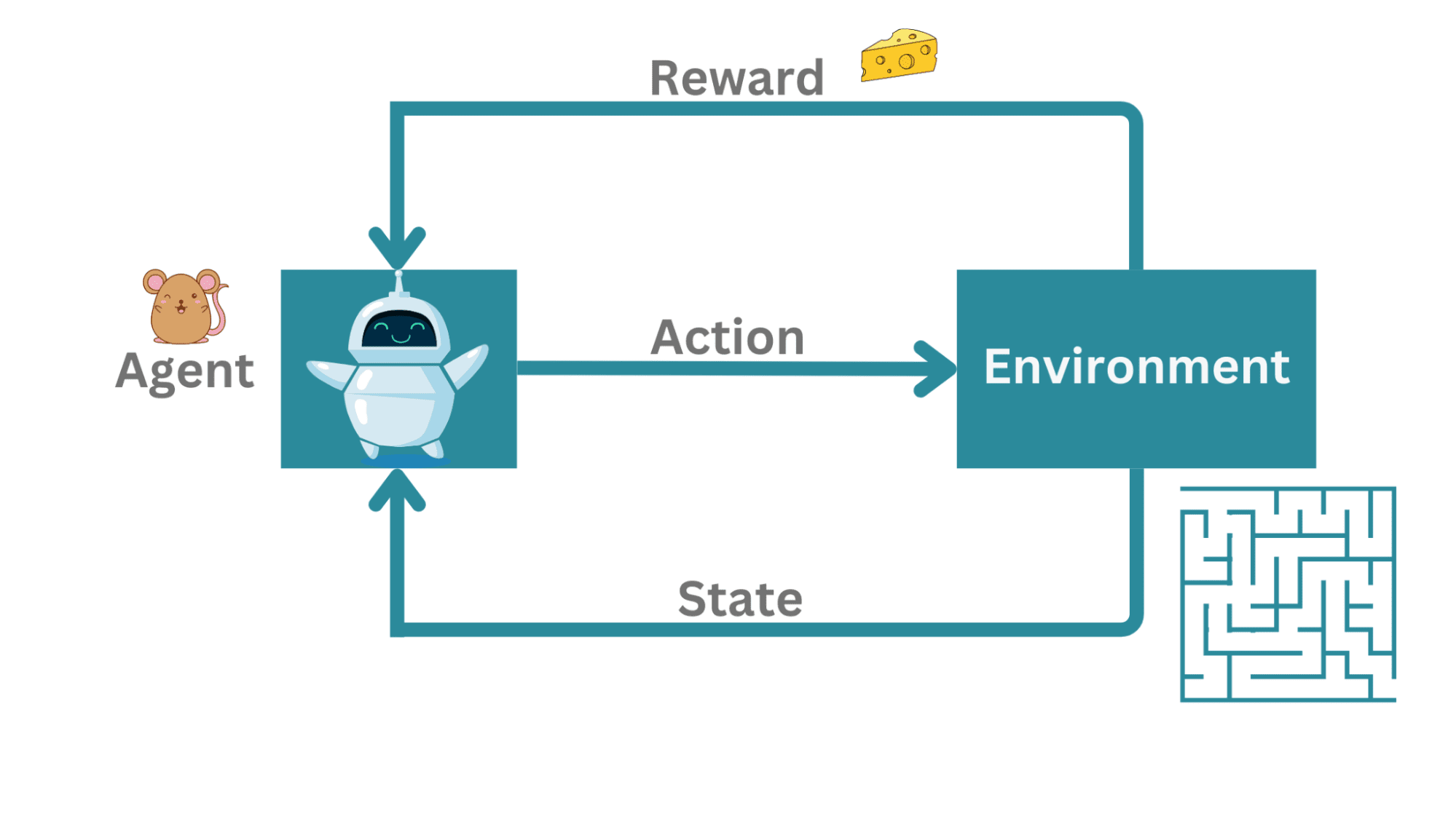
Example | Image by Author
The sequence of actions happens in discrete time steps (say, t = 1, 2, 3,...). At any time step t, the mouse can only measure its current state in the maze. It doesn’t know the whole maze yet.
So the agent (the mouse) measures its state  in the environment at time step t, takes a valid action and moves to state .
in the environment at time step t, takes a valid action and moves to state .
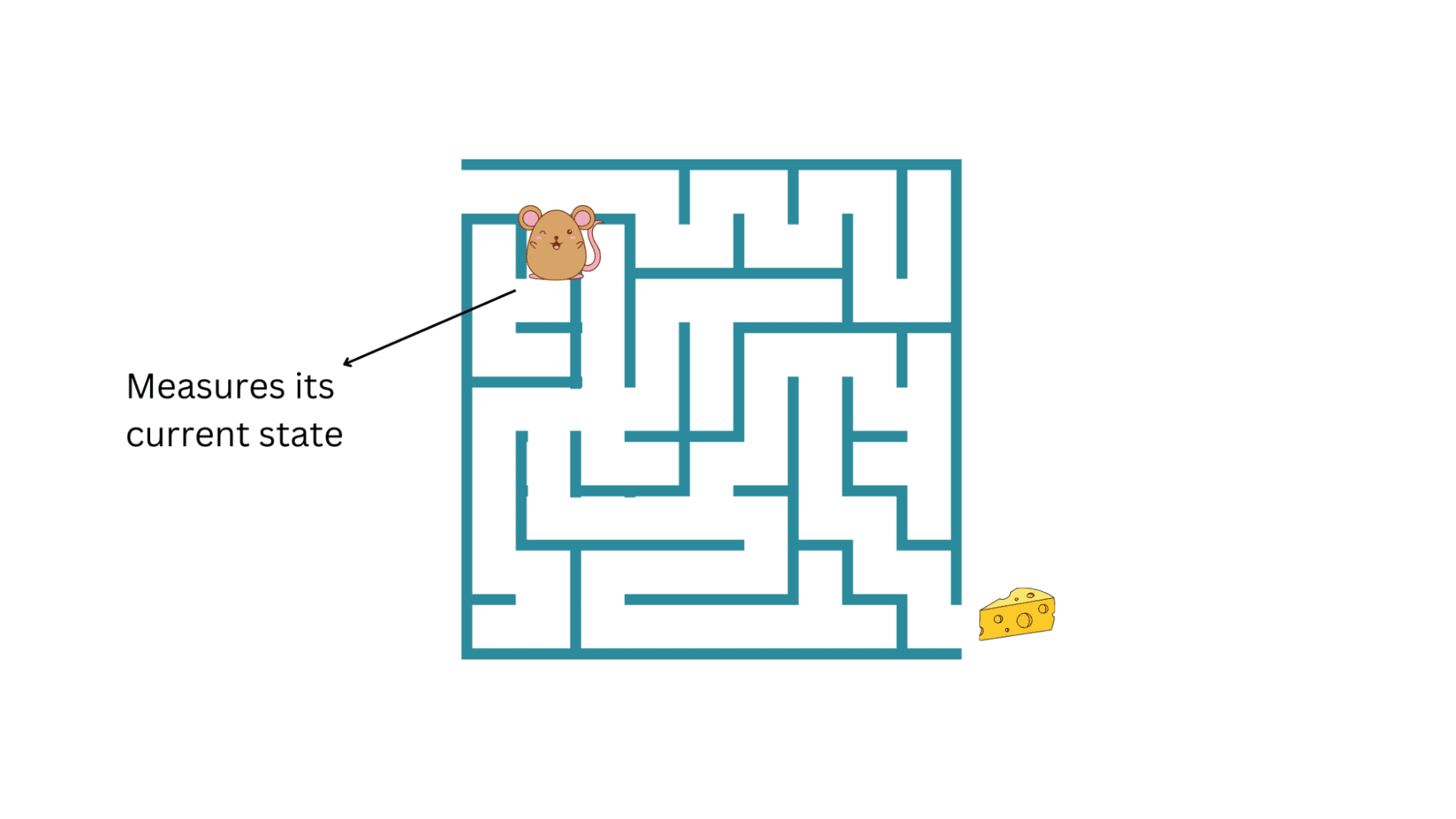
State | Image by Author
How Is Reinforcement Learning Different?
Notice how the mouse (the agent) has to figure its way out of the maze through trial and error. Now if the mouse hits one of the walls of the maze, it has to try to find its way back and etch a different route to the exit.
If this were a supervised learning setting, after every move, the agent would get to know whether or not that action—was correct—and would lead to a reward. Supervised learning is like learning from a teacher.
While a teacher tells you ahead of time, a critic always tells you—after the performance is over— how good or bad your performance was. For this reason, reinforcement learning is also called learning in the presence of a critic.
Terminal State and Episode
When the mouse has reached the exit, it reaches the terminal state. Meaning it cannot explore any further.
And the sequence of actions—from the initial state to the terminal state—is called an episode. For any learning problem, we need multiple episodes for the agent to learn to navigate. Here, for our agent (the mouse) to learn the sequence of actions that would lead it to the exit, and subsequently, receive the piece of cheese, we’d need many episodes.
Dense and Sparse Rewards
Whenever the agent takes a correct action or a sequence of actions that is correct, it gets a reward. In this case, the mouse receives a piece of cheese as a reward for etching a valid route—through the maze(the environment)—to the exit.
In this example, the mouse receives a piece of cheese only at the very end—when it reaches the exit.This is an example of a sparse and delayed reward.
If the rewards are more frequent, then we will have a dense reward system.
Looking back we need to figure out (it’s not trivial) which action or sequence of actions caused the agent to get the reward; this is commonly called the credit assignment problem.
Policy, Value Function, and the Optimization Problem
The environment is often not deterministic but probabilistic and so is the policy. Given a state , the agent takes an action and goes to another state with a certain probability.
The policy helps define a mapping from the set of possible states to the actions. It helps answer questions like:
- What actions to take to maximize the expected reward?
- Or better yet: Given a state, what is the best possible action that the agent can take so as to maximize expected reward?
So you can think of the agent as enacting a policy π:

Another related and helpful concept is the value function. The value function is given by:

This signifies the value of being in a state given a policy π. The quantity denotes the expected reward in the future if the agent starts at state and enacts the policy π thereafter.
To sum up: the goal of reinforcement learning is to optimize the policy so as to maximize the expected future rewards. Therefore, we can think of it as an optimization problem to solve for π.
Discount Factor
Notice that we have a new quantity ɣ. What does it stand for? ɣ is called the discount factor, a quantity between 0 and 1. Meaning future rewards are discounted (read: because now is greater than much later).
Exploration vs. Exploitation Tradeoff
Going back to the food loop example of mouse in a maze: If the mouse is able to figure out a route to exit A with a small piece of cheese, it can keep repeating it and collecting the cheese piece. But what if the maze also had another exit B with a bigger cheese piece (greater reward)?
So long as the mouse keeps exploiting this current strategy without exploring new strategies, it is not going to get the much greater reward of a bigger cheese piece at exit B.
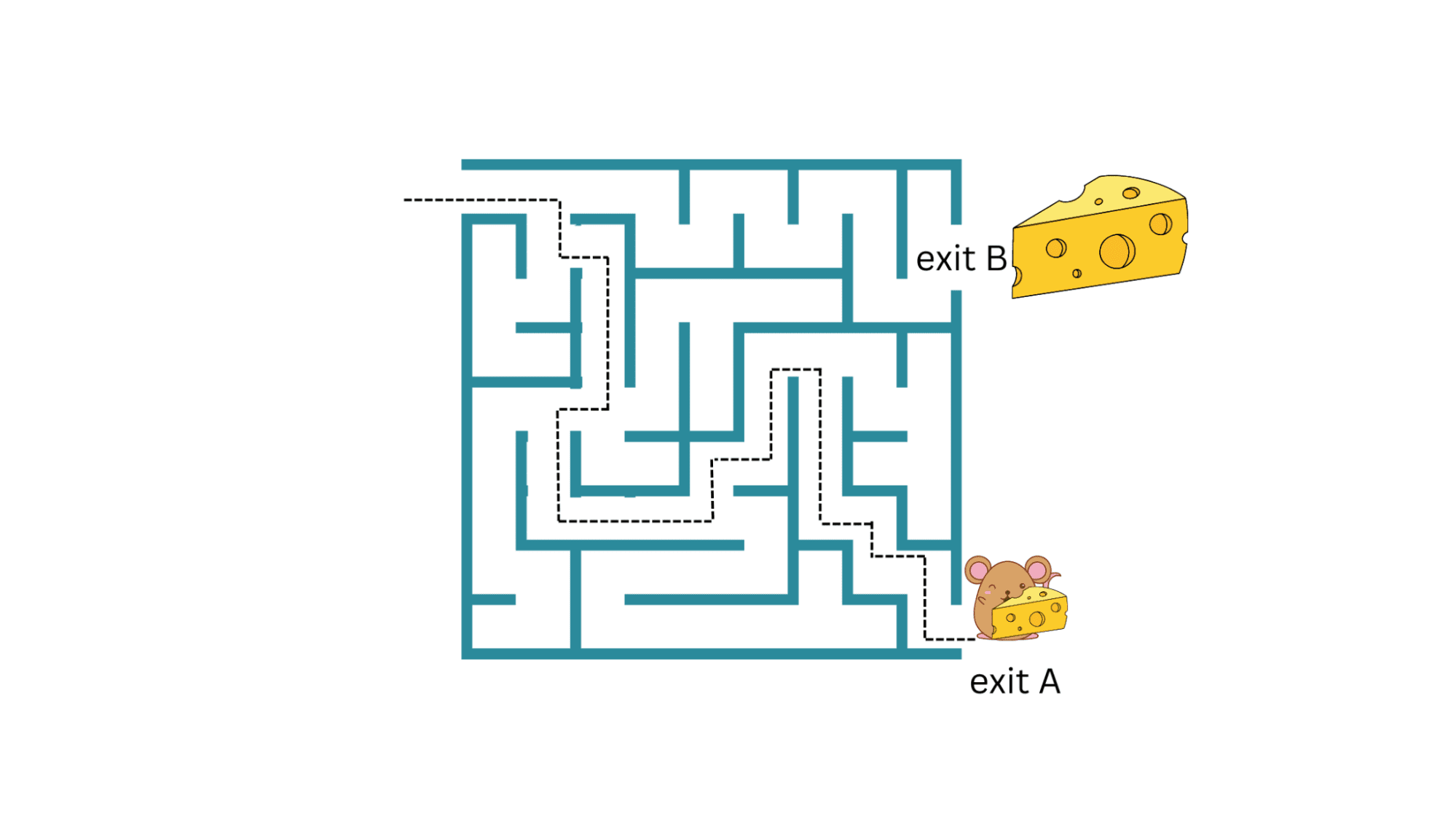
Exploration vs. Exploitation | Image by Author
But the uncertainty associated with exploring new strategies and future rewards is greater. So how do we exploit and explore? This tradeoff between exploiting the current strategy and exploring new ones with potentially better rewards is called the exploration vs exploitation tradeoff.
One possible approach is the ε-greedy search. Given a set of all possible actions , the ε-greedy search explores one of the possible actions with the probability ε while exploiting the current strategy with the probability 1 - ε.
Wrap-up and Next Steps
Let's summarize what we’ve covered so far. We learned about the components of the reinforcement learning framework:
- The agent interacts with the environment, gets to measure its current state, takes actions, and receives rewards as positive reinforcement. The framework is probabilistic.
- We then went over value functions and policy, and how the optimization problem often boils down to finding the optimal policies that maximize the expected future awards.
You’ve now learned just enough to navigate the reinforcement learning landscape. Where to go from here? We did not talk about reinforcement learning algorithms in this guide, so you can explore some basic algorithms:
- If we know everything about the environment (and can model it completely), we can use model-based algorithms like policy iteration and value iteration.
- However, in most cases, we may not be able to model the environment completely. In this case, you can look at model-free algorithms such as Q-learning which optimizes state-action pairs.
If you’re looking to further your understanding of reinforcement learning, David Silver’s reinforcement learning lectures on YouTube and Hugging Face’s Deep Reinforcement Learning Course are some good resources to look at.
Bala Priya C is a developer and technical writer from India. She likes working at the intersection of math, programming, data science, and content creation. Her areas of interest and expertise include DevOps, data science, and natural language processing. She enjoys reading, writing, coding, and coffee! Currently, she's working on learning and sharing her knowledge with the developer community by authoring tutorials, how-to guides, opinion pieces, and more.