How LinkedIn, Uber, Lyft, Airbnb and Netflix are Solving Data Management and Discovery for Machine Learning Solutions
As machine learning evolves, the need for tools and platforms that automate the lifecycle management of training and testing datasets is becoming increasingly important. Fast growing technology companies like Uber or LinkedIn have been forced to build their own in-house data lifecycle management solutions to power different groups of machine learning models.

When comes to machine learning, data is certainly the new oil. The processes for managing the lifecycle of datasets are some of the most challenging elements of large scale machine learning solutions. Data ingestion, indexing, search, annotation, discovery are some of the aspects required to maintain high quality datasets. The complexity of these challenges increase linearly with the size and number of the target datasets. While it is relatively easy to manage training datasets for a single machine learning model, scaling that process across thousands of dataset and hundreds of models can become nothing short of a nightmare. Some of the companies at the forefront of machine learning innovation such as LinkedIn, Uber, Netflix, Airbnb or Lyft have certainly experienced the magnitude of this challenge and they have built specific solutions to address it. Today, I would like to walk you through some of those solutions that can serve as an inspiration in your machine learning journey.
High quality machine learning requires high quality datasets and those are not very easy to produce. As machine learning evolves, the need for tools and platforms that automate the lifecycle management of training and testing datasets is becoming increasingly important. Somewhat paradoxically, machine learning frameworks have evolved several orders of magnitude faster than the corresponding data management toolset. While today we have dozens high quality development frameworks that incorporate the latest research in deep learning disciplines, the platforms for managing the lifecycle of the datasets powering machine learning models are still in its infancy. To solve that challenge, fast growing technology companies like Uber or LinkedIn have been forced to build their own in-house data lifecycle management solutions to power different groups of machine learning models. Let’s take a look at how they did it.
LinkedIn’s Data Hub
Data Hub is a recent addition to LinkedIn’s data analytics stack. The core focus on LinkedIn’s Data Hub is to automate the collection, search and discovery of metadata related to datasets as well as other entities such as machine learning models, microservices, people, groups etc. Specifically, Data Hub was designed to achieve four specific goals:
- Modeling: Model all types of metadata and relationships in a developer friendly fashion.
- Ingestion: Ingest large amount of metadata changes at scale, both through APIs and streams.
- Serving: Serve the collected raw and derived metadata, as well as a variety of complex queries against the metadata at scale.
- Indexing: Index the metadata at scale, as well as automatically update the indexes when the metadata changes.
To enable the aforementioned capabilities, Data Hub a state-of-the-art technology stack that includes several frameworks developed internally at LinkedIn. For instance, all metadata constructs stored in Data Hub are modeled using the Pegasus data schema language which was incubated by LinkedIn years ago. Similarly, the APIs powering Data Hub are based on LinkedIn’s Rest.li architecture for highly scalable RESTful services. LinkedIn’s data storage technologies such as Expresso or Galene are also used to store the metadata representations in ways that can enable diverse use cases such as search or complex relationship navigations. To abstract those different types of storage, Data Hub uses a set of generic Data Access Objects (DAO), such as key-value DAO, query DAO, and search DAO. This allow to use Data Hub with different underlying storage technologies.
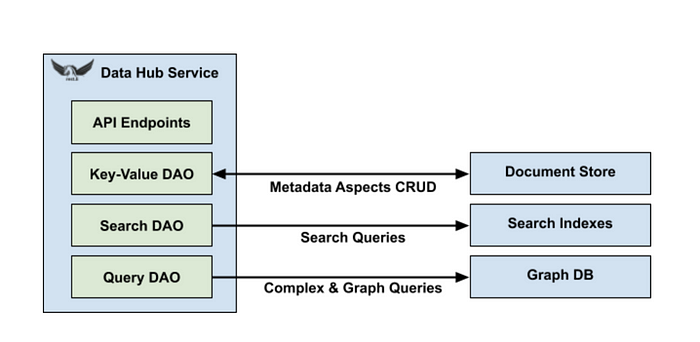
The robust backend architecture of LinkedIn’s Data Hub is complemented with a simple user interface that enables the search and discovery of metadata elements.
Uber’s Databook
Databook is the main platform powering data discovery and lifecycle management across Uber’s data science workflows. The Databook platform manages and surfaces rich metadata about Uber’s datasets, enabling employees across Uber to explore, discover, and effectively utilize data at Uber. Conceptually, Databook was designed to enable four key capabilities:
- Extensibility: New metadata, storage, and entities are easy to add.
- Accessibility: Services can access all metadata programmatically.
- Scalability: Support for high-throughput read.
- Power: Cross-data center read and write.
The current Databook architecture can process metadata from a diverse group of data storage systems including Vertica, PostgreSQL, MySQL and others. The metadata is ultimately indexed in a repository based on ElasticSearch and surfaced through a RESTful APIs powered by Dropwizard, a Java framework for high-performance RESTful web services.

Databook allow users to search and browse the metadata associated with a specific asset using a simple web interface based on React, Redux and D3.js.
Airbnb’s Dataportal
Like many other fast growing technology companies, Airbnb also experienced the challenges of enabling a lifecycle management and discovery layer for those data asset. Dataportal was the solution to those requirements. Dataportal captures metadata information about different data assets in a form of a connected graph. Nodes in the graph are the various resources: data tables, dashboards, reports, users, teams, business outcomes, etc. Their connectivity reflects their relationships: consumption, production, association, etc.

The Dataportal technology stack is based on Neo4J and ElasticSearch as the main data storage components. APIs on the platform are powered by the Flask framework and the UI is based on React and Redux.
The ultimate materialization of Airbnb’s Dataportal is a slick user interface that enables the search, collaboration and discovery of metadata related to corporate datasets.
Lyft’s Amundsen
Amundsen is Lyft’s platform for metadata ingestion, search and discovery. Named after Norwegian explorer Ronald Amundsen, the platform was originally conceived to improve the productivity of data analysts, data scientists and engineers when interacting with data. From the architecture standpoint, Amundsen provides a layer of data collection that integrates with a series of databases as well as microservices for metadata management and search.

Amundsen microservices abstract the core functionalities of the platform. The current version of Amundsen includes the following microservices:
- amundsenfrontendlibrary: Frontend service which is a Flask application with a React frontend.
- amundsensearchlibrary: Search service, which leverages Elasticsearch for search capabilities, is used to power frontend metadata searching.
- amundsenmetadatalibrary: Metadata service, which leverages Neo4j or Apache Atlas as the persistent layer, to provide various metadata.
- amundsendatabuilder: Data ingestion library for building metadata graph and search index. Users could either load the data with a python script with the library or with an Airflow DAG importing the library.
Amundsen combines it backend architecture with a simple user experience that enables the search and exploration of datasets.

Netflix Metacat
Netflix has been an active contributor to open source technologies in the big data space and data discovery and management is not the exception. Metacat is Netflix’s solution to automate the lifecycle of metadata assets. Functionally, Metacat is a federated service providing a unified REST/Thrift interface to access metadata of various data stores. At a high level , Metacat provides the following capabilities:
- Data abstraction and interoperability
- Business and user-defined metadata storage
- Data discovery
- Data change auditing and notifications
- Hive metastore optimizations
The Metacat architecture combines a connectivity layer that integrates with different data stores, a storage layer that captures the metadata relevant to data assets and an API layer that enables the search and querying of metadata elements.
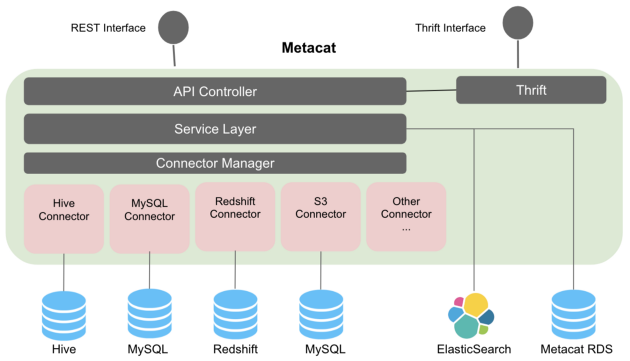
Differently from other solutions in the space, Metacat focuses mostly on the backend infrastructure required to enable metadata search and discovery. The simplicity of the APIs facilitates the implementation of different data catalog frontends based on specific requirements.
As you can see, metadata discovery and management is an active area of development for some of the fastest growing companies in tech. The rapid evolution of machine learning is going to continue increasing the relevance of data discovery and management and we should soon see some of these solutions adopted as part of mainstream machine learning stacks.
Original. Reposted with permission.
Related:
- Manual Coding or Automated Data Integration – What’s the Best Way to Integrate Your Enterprise Data?
- 6 Key Concepts in Andrew Ng’s “Machine Learning Yearning”
- Statistical Modelling vs Machine Learning