Context Engineering Explained in 3 Levels of Difficulty
Long-running LLM applications degrade when context is unmanaged. Context engineering turns the context window into a deliberate, optimized resource. Learn more in this article.
Context Engineering Explained in 3 Levels of Difficulty | Image by Author
# Introduction
Large language model (LLM) applications hit context window limits constantly. The model forgets earlier instructions, loses track of relevant information, or degrades in quality as interactions extend. This is because LLMs have fixed token budgets, but applications generate unbounded information — conversation history, retrieved documents, file uploads, application programming interface (API) responses, and user data. Without management, important information gets randomly truncated or never enters context at all.
Context engineering treats the context window as a managed resource with explicit allocation policies and memory systems. You decide what information enters context, when it enters, how long it stays, and what gets compressed or archived to external memory for retrieval. This orchestrates information flow across the application's runtime rather than hoping everything fits or accepting degraded performance.
This article explains context engineering at three levels:
- Understanding the fundamental necessity of context engineering
- Implementing practical optimization strategies in production systems
- Reviewing advanced memory architectures, retrieval systems, and optimization techniques
The following sections explore these levels in detail.
# Level 1: Understanding The Context Bottleneck
LLMs have fixed context windows. Everything the model knows at inference time must fit in those tokens. This is not much of a problem with single-turn completions. For retrieval-augmented generation (RAG) applications and AI agents running multi-step tasks with tool calls, file uploads, conversation history, and external data, this creates an optimization problem: what information gets attention and what gets discarded?
Say you have an agent that runs for multiple steps, makes 50 API calls, and processes 10 documents. Such an agentic AI system will most likely fail without explicit context management. The model forgets critical information, hallucinates tool outputs, or degrades in quality as the conversation extends.
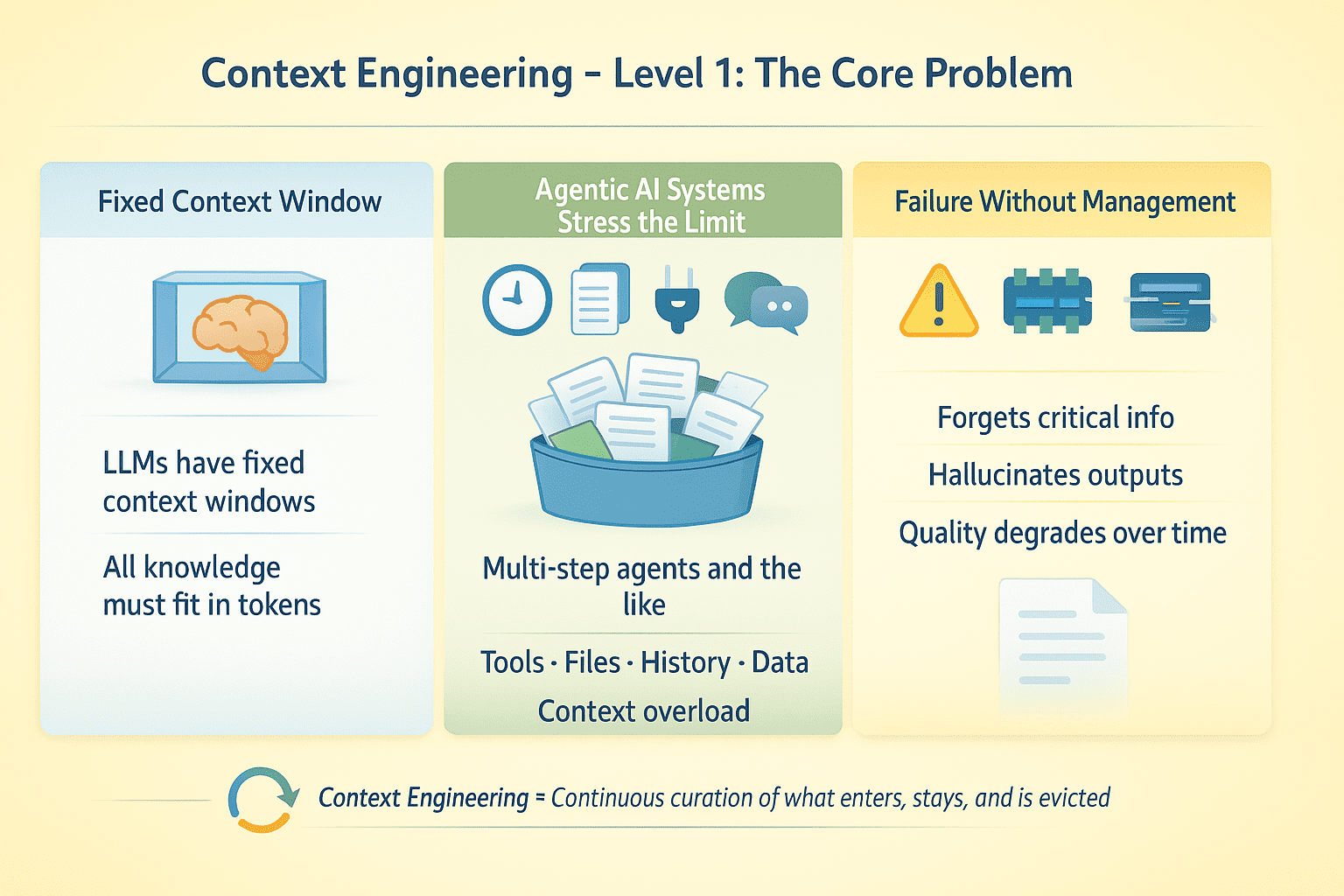
Context Engineering Level 1 | Image by Author
Context engineering is about designing for continuous curation of the information environment around an LLM throughout its execution. This includes managing what enters context, when, for how long, and what gets evicted when space runs out.
# Level 2: Optimizing Context In Practice
Effective context engineering requires explicit strategies across several dimensions.
// Budgeting Tokens
Allocate your context window deliberately. System instructions might take 2K tokens. Conversation history, tool schemas, retrieved documents, and real-time data can all add up quickly. With a very large context window, there is plenty of headroom. With a much smaller window, you are forced to make hard tradeoffs about what to keep and what to drop.
// Truncating Conversations
Keep recent turns, drop middle turns, and preserve critical early context. Summarization works but loses fidelity. Some systems implement semantic compression — extracting key facts rather than preserving verbatim text. Test where your agent breaks as conversations extend.
// Managing Tool Outputs
Large API responses consume tokens fast. Request specific fields instead of full payloads, truncate results, summarize before returning to the model, or use multi-pass strategies where the agent first gets metadata then requests details for relevant items only.
// Using The Model Context Protocol And On-demand Retrieval
Instead of loading everything upfront, connect the model to external data sources it queries when needed using the model context protocol (MCP). The agent decides what to fetch based on task requirements. This shifts the problem from "fit everything in context" to "fetch the right things at the right time."
// Separating Structured States
Put stable instructions in system messages. Put variable data in user messages where it can be updated or removed without touching core directives. Treat conversation history, tool outputs, and retrieved documents as separate streams with independent management policies.
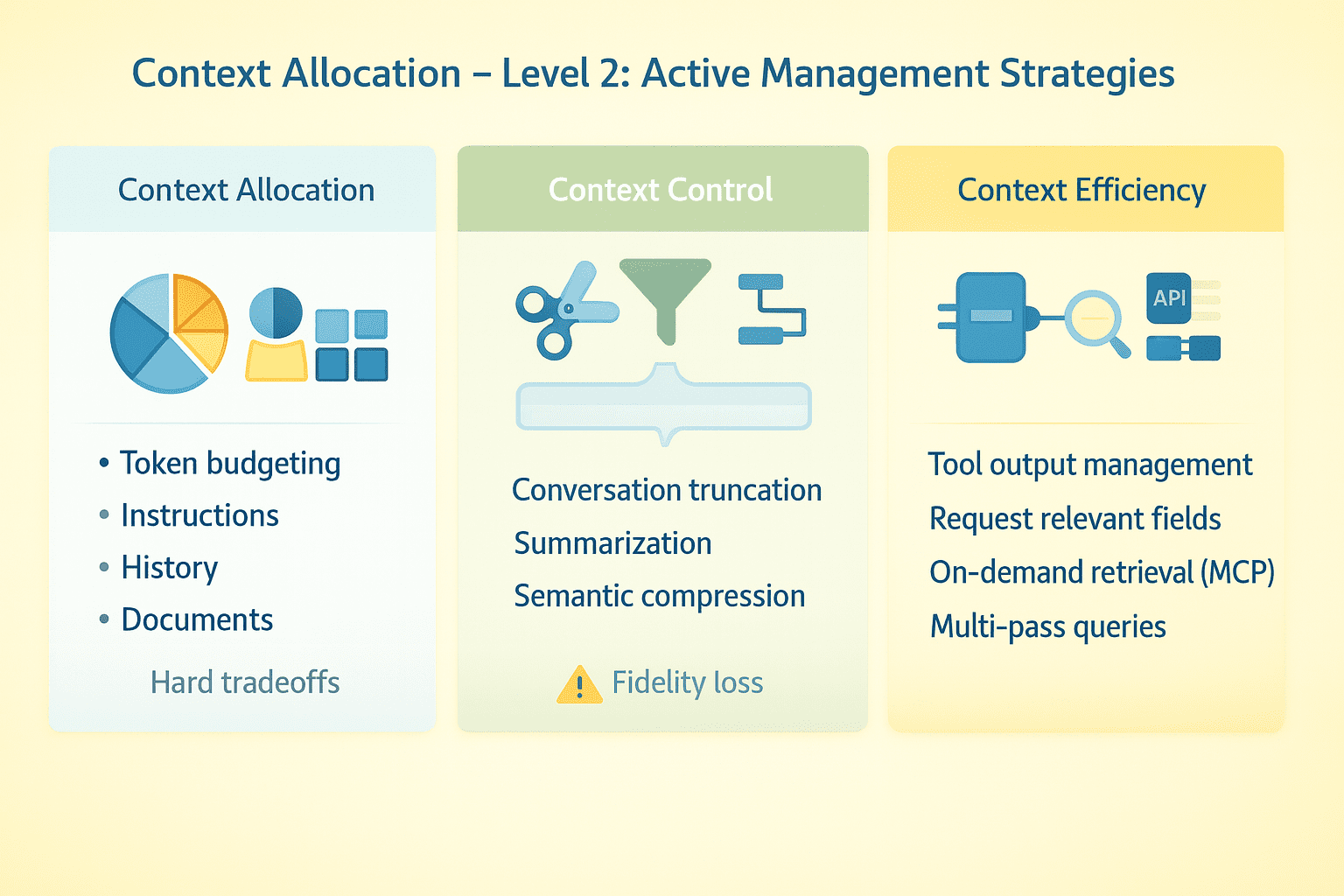
Context Engineering Level 2 | Image by Author
The practical shift here is to treat context as a dynamic resource that needs active management across an agent's runtime, not a static thing you configure once.
# Level 3: Implementing Context Engineering In Production
Context engineering at scale requires sophisticated memory architectures, compression strategies, and retrieval systems working in concert. Here is how to build production-grade implementations.
// Designing Memory Architecture Patterns
Separate memory in agentic AI systems into tiers:
- Working memory (active context window)
- Episodic memory (compressed conversation history and task state)
- Semantic memory (facts, documents, knowledge base)
- Procedural memory (instructions)
Working memory is what the model sees now, which is to be optimized for immediate task needs. Episodic memory stores what happened. You can compress aggressively but preserve temporal relationships and causal chains. For semantic memory, store indexes by topic, entity, and relevance for fast retrieval.
// Applying Compression Techniques
Naive summarization loses critical details. A better approach is extractive compression, where you identify and preserve high-information-density sentences while discarding filler.
- For tool outputs, extract structured data (entities, metrics, relationships) rather than prose summaries.
- For conversations, preserve user intents and agent commitments exactly while compressing reasoning chains.
// Designing Retrieval Systems
When the model needs information not in context, retrieval quality determines success. Implement hybrid search: dense embeddings for semantic similarity, BM25 for keyword matching, and metadata filters for precision.
Rank results by recency, relevance, and information density. Return top K but also surface near-misses; the model should know what almost matched. Retrieval happens in-context, so the model sees query formulation and results. Bad queries produce bad results; expose this to enable self-correction.
// Optimizing At The Token Level
Profile your token usage continuously.
- System instructions consuming 5K tokens that could be 1K? Rewrite them.
- Tool schemas verbose? Use compact
JSONschemas instead of fullOpenAPIspecs. - Conversation turns repeating similar content? Deduplicate.
- Retrieved documents overlapping? Merge before adding to context.
Every token saved is a token available for task-critical information.
// Triggering Memory Retrieval
The model should not retrieve constantly; it is expensive and adds latency. Implement smart triggers: retrieve when the model explicitly requests information, when detecting knowledge gaps, when task switches occur, or when user references past context.
When retrieval returns nothing useful, the model should know this explicitly rather than hallucinating. Return empty results with metadata: "No documents found matching query X in knowledge base Y." This lets the model adjust strategy by reformulating the query, searching a different source, or informing the user the information is not available.
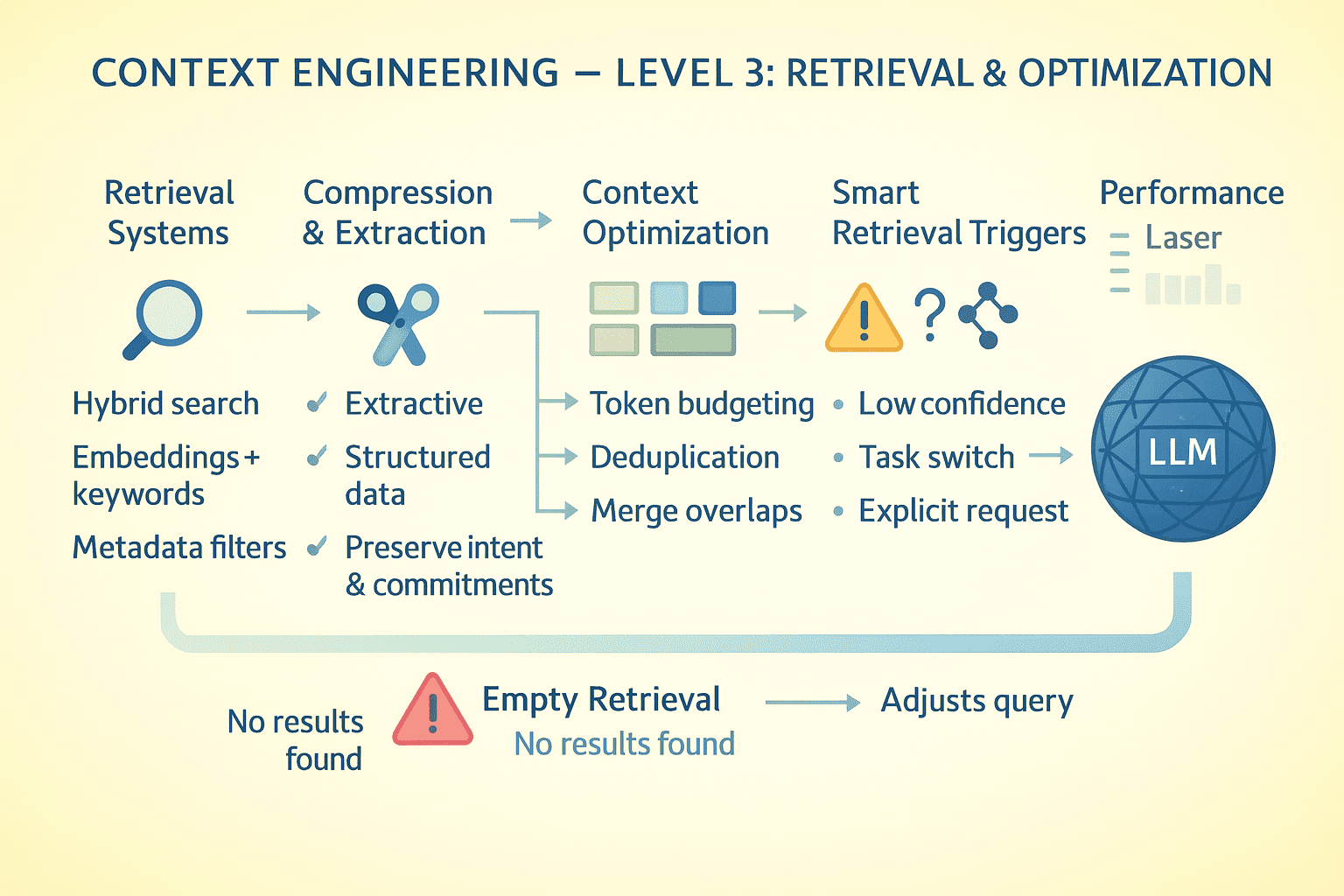
Context Engineering Level 3 | Image by Author
// Synthesizing Multi-document Information
When reasoning requires multiple sources, process hierarchically.
- First pass: extract key facts from each document independently (parallelizable).
- Second pass: load extracted facts into context and synthesize.
This avoids context exhaustion from loading 10 full documents while preserving multi-source reasoning capability. For contradictory sources, preserve the contradiction. Let the model see conflicting information and resolve it or flag it for user attention.
// Persisting Conversation State
For agents that pause and resume, serialize context state to external storage. Save compressed conversation history, current task graph, tool outputs, and retrieval cache. On resume, reconstruct minimal necessary context; do not reload everything.
// Evaluating And Measuring Performance
Track key metrics to understand how your context engineering strategy is performing. Monitor context utilization to see the average percentage of the window being used, and eviction frequency to understand how often you are hitting context limits. Measure retrieval precision by checking what fraction of retrieved documents are actually relevant and used. Finally, track information persistence to see how many turns important facts survive before being lost.
# Wrapping Up
Context engineering is ultimately about information architecture. You are building a system where the model has access to everything in its context window and no access to what is not. Every design decision — what to compress, what to retrieve, what to cache, and what to discard — creates the information environment your application operates in.
If you do not focus on context engineering, your system may hallucinate, forget important details, or break down over time. Get it right and you get an LLM application that stays coherent, reliable, and effective across complex, extended interactions despite its underlying architectural limits.
Happy context engineering!
# References And Further Learning
- Context Engineering for AI Agents | Weaviate
- Context Engineering For Agents | LangChain
- Effective Context Engineering for AI Agents | Anthropic
- Memory Cookbook | Claude Cookbooks
Bala Priya C is a developer and technical writer from India. She likes working at the intersection of math, programming, data science, and content creation. Her areas of interest and expertise include DevOps, data science, and natural language processing. She enjoys reading, writing, coding, and coffee! Currently, she's working on learning and sharing her knowledge with the developer community by authoring tutorials, how-to guides, opinion pieces, and more. Bala also creates engaging resource overviews and coding tutorials.