Hand labeling is the past. The future is #NoLabel AI
Data labeling is so hot right now… but could this rapidly emerging market face disruption from a small team at Stanford and the Snorkel open source project, which enables highly efficient programmatic labeling that is 10 to 1,000x as efficient as hand labeling?
By Russell Jurney, Consultant and machine learning engineer.
Labelomania
We are witnessing a data labeling market explosion: labeling platforms have hit prime time. S&P Global released an October 11 report entitled *Avoiding Garbage in Machine Learning* in which it termed unlabeled data “garbage data” to highlight the importance of labeling in AI. The Economist recently noted that while spending on AI is growing from $38bn this year to $98bn in 2023, only 1 in 5 companies interested in AI has deployed machine learning models because of a shortage of labeled data. This is why “the market for data-labeling services may triple to $5bn by 2023.” It is difficult not to notice the abundance of labeling startups being funded of late that are chasing after this market.

Is exuberance about traditional hand labeling label mania? Source: Wikipedia, Tulip Mania.
Why all the excitement?
The deep learning revolution has brought about new levels of sophistication in machine learning and artificial intelligence, such that it has applicability to a large range of business problems. Traditional modeling involved feature engineering as a primary activity in order to select a subset of features to simplify the model. Representation learning with neural networks uses massive models and large volumes of training data to learn features automatically. This has shifted the activity in machine learning from feature engineering to dataset management. [Ratner, A, 2019]. Acquiring and managing labeled data can be the most expensive part of building AI into a business, and this is a major gating factor in AI adoption.
Far from being an implementation detail, the availability of labeled data is often what determines whether a problem is even approachable. Pete Skomoroch, the AI veteran and investor, recently said, “Data labeling is a good proxy for whether machine learning is cost-effective for a problem. If you can build labeling into normal user activities you track like Facebook, Google, and Amazon consumer applications, you have a shot. Otherwise, you burn money paying for labeled data. Many people still try to apply machine learning on high profile problems without oxygen, and burn lots of money in the process without solving them.”
Large technology companies have a large lead in AI because their labeling costs are so low. They were the companies that created the field of big data processing, and now that infrastructure is being used to drive AI using their vast reserves of labeled data. Other companies are struggling to get started, let alone catchup. As they rush to do so, a major question they must answer is: how can I acquire the labeled data needed to transform my business with AI to keep it relevant in the changing market? Another related question is: how much labeling technology even applies to private data that can’t be shipped outside of an organization?
Programmatic Labeling
What if there were a shortcut to labeling data? What if subject matter experts could write data labeling programs that each acted as weak labels that an unsupervised model - one requiring no labels - could combine into strong labels? That is the promise of the Snorkel Project that emerged from Stanford’s HazyResearch group. “Back in 2016, we were surprised to notice that a lot of our collaborators in ML were starting to spend the majority of their time building, managing, cleaning, and most of all, labeling massive training datasets — and we asked why there wasn’t a system where practitioners could label and manage their training data in higher-level, programmatic, and ultimately faster ways?”
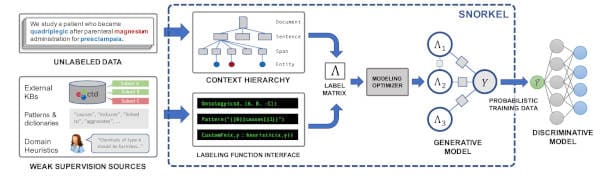
An overview of the Snorkel systems. (1) SME users write labeling functions (LFs) that express weak supervision sources like distance supervision, patterns, and heuristics. (2) Snorkel applies the LFs over unlabeled data and learns a generative model to combine the LFs' outputs into probabilistic labels. (3) Snorkel uses these labels to train a discriminative classification model, such as a deep neural network.
Ratner, A. Bach, S. H. Ehrenberg, H. Fries, J. Wu, S. Ré, C. Snorkel: Rapid Training Data Creation with Weak Supervision. Stanford University, 2017.
Snorkel team member Henry Ehrenberg calls it an effort to turn the onerous, ad-hoc tasks of hand labeling and manually managing a messy collection of training sets into an iterative development process, guided by a common set of interfaces (like labeling functions) and algorithms (like Snorkel’s label model) Weak supervision through Snorkel was introduced in the landmark 2016 paper Data Programming: Creating Large Training Sets, Quickly and 2017 paper Snorkel: Rapid Training Data Creation with Weak Supervision, calling it, “a first-of-its-kind system that enables users to train state-of-the-art models without hand labeling any training data.”
Snorkel uses an unsupervised generative model that learns the dependency graph among weak sets of labels produced by small user-written “labeling functions” by looking at each labeling function’s coverage, overlap, and conflicts with other labeling functions. This enables it to determine their accuracies as well as their correlations, and the only underlying assumption is that the average labeling function is better than a random coin flip. This seems like mathematical magic, matrix factorization of strange geometries from the Necronomicon. But I was somehow surprised to find how well it really does work. And it scales. Google uses it with PySpark at scale to label vast amounts of data for some of its most critical systems [Ratner, Hancock et al, 2018]. Weak supervision has become a fundamental part of Software 2.0. Another important ability of data programming with Snorkel is that it can label data without ever exposing it to human eyes - a critical feature in industries like healthcare and legal services.

An example of a labeling function dependency graph (left) and its junction tree representation (right). Here, the output of labeling functions 1 and 2 are modeled as dependent conditioned on y. This results in a junction tree with singleton separator sets, y.
Ratner, Alex. Accelerating Machine Learning with Training Data Management. PhD Thesis, Stanford University, 2019.
#NoLabel Products
So what does this mean for companies building AI systems and products to drive their business?
AI product management is constrained by the availability of labeled data. Product thinking starts with, “What can we build to improve our business using the labels we have or can acquire?” The availability of labels is a gating step. After identifying a key problem AI can address, one often undertakes a massive labeling scheme using task workers or hardware devices. Building products has become more about dataset management than it is about data science.

Just as higher-level programming languages magnify a user's algorithmic capabilities, we envision higher-level supervision interfaces that magnify a user's labeling capabilities. These higher-level inputs can be compiled into labeling functions (LFs), which in turn are used by systems like Snorkel to generate labeled training sets.
Ratner, A. Hancock, B. Ré, C. The Role of Massively Multi-Task and Weak Supervision in Software 2.0. Stanford University, 2019.
Weak supervision uncorks that bottleneck, eliminating the labeling gating step by increasing the efficiency of labeling by one, two, or even three orders of magnitude. This greatly expands the range of possible products and transforms the thought process into, “What can we build using the labels we can infer using the data we have or can acquire?” This is a profound change in AI product management that after a year of work is still sinking in. The range of possible applications for AI within a business increases dramatically. Leveraging weak supervision to build AI will give early adopters an enormous advantage in the coming decade.
In short: the adoption of weak supervision will help determine winners and losers across a range of industries in the next decade, and Snorkel sits at the center of the open-source ecosystem around this trend.
Sources
- Ratner, Alex. Accelerating Machine Learning with Training Data Management, Stanford University, Ph.D. Thesis, 2019.
- Ratner, A. Bach, S. H. Ehrenberg, H. Fries, J. Wu, S. Ré, C. Snorkel: Rapid Training Data Creation with Weak Supervision. Stanford University, 2017.
- Ratner, A. Hancock, B. Dunnmon, J. Goldman, R. Ré, C. Snorkel MeTaL: Weak Supervision for Multi-Task Learning. Stanford University, 2018.
- Ratner, A. Hancock, B. Ré, C. The Role of Massively Multi-Task and Weak Supervision in Software 2.0. Stanford University, 2019.
- Ratner, A. De Sa, C. Wu, S. Selsam, D. Ré, C. Data Programming: Creating Large Training Sets, Quickly. Stanford University, 2019.
Bio: Russell Jurney is a consultant and machine learning engineer specializing in data labeling, natural language processing, weak supervision, Snorkel, and building end-to-end AI products from conception to deployment. He is the author of the forthcoming book on weak supervision and Snorkel entitled Weakly Supervised Learning, O’Reilly Media, 2020.
Related: