Making sense of ensemble learning techniques
This article breaks down ensemble learning and how it can be used for problem solving.
By Ido Zehori, Data Science Team Leader at Bigabid
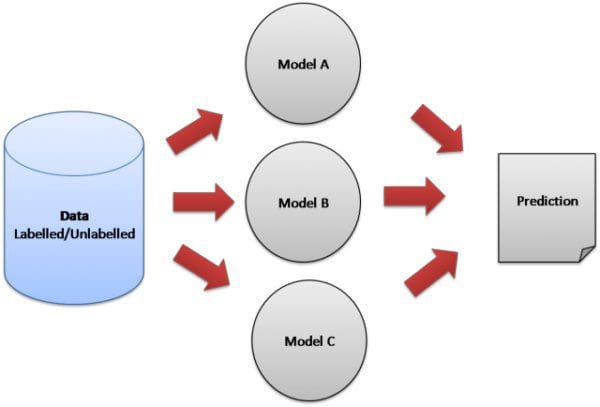
For many companies/data scientists that specialize or work with machine learning (ML), ensemble learning methods have become the weapons of choice. As ensemble learning methods combine multiple base models, together they have a greater ability to produce a much more accurate ML model. For example, at Bigabid we’ve been ensemble learning to successfully solve a variety of problems ranging from optimizing LTV (Customer Lifetime Value) to fraud detection.
It is hard not overstate the importance of ensemble learning to the overall ML process, including the bias-variance tradeoff and the three main ensemble techniques: bagging, boosting and stacking. These powerful techniques should be a part of any data scientist’s tool kit, as they are concepts that are encountered everywhere. Plus, understanding their underlying mechanism is at the heart of the field of machine learning.
Ensemble Learning Methods: An Overview
Ensemble learning is an ML paradigm where numerous base models (which are often referred to as “weak learners”) are combined and trained to solve the same problem. This method is based on the theory that by correctly combining several base models together, these weak learners can be used as building blocks for designing more complex ML models. Together these ensemble models (aptly called “strong learners”) achieve better, more accurate results.
In other words, a weak learner is merely a base model that alone performs rather poorly. In fact, its accuracy level is barely above chance, meaning that it predicts the outcome only slightly better than a random guess would. These weak learners will often be computationally simple as well. Typically, the reason base models don’t perform very well by themselves is because they either have a high bias or too much variance, which makes them weak.
This is where ensemble learning comes in. This method attempts to try to reduce the general error by combining several weak learners together. Think of ensemble models as the data science version of the expression “two heads are better than one.” If one model works well, then a number of models working together can do even better.
A Word about the Bias-Variance Tradeoff
It’s important to understand the concept of a weak learner and why it earned this name in the first place, as the reason comes down to either bias or variance. More specifically, the prediction error of an ML model, namely the difference between the trained model and the ground truth, can be broken down into the sum of the following: the bias and the variance. For instance:
- Error due to Bias: This is the difference between a model’s expected prediction and the precise value that we are aiming to predict.
- Error due to Variance: This is the variance of a model prediction for a specified data point.
If a model is too simplistic and doesn’t have many parameters, then it may have high bias and low variance. In contrast, if a model has many parameters, then it may have high variance and low bias. As such, it’s necessary to find the right balance without underfitting or overfitting the data, as this tradeoff in complexity is the reason why there exists a tradeoff between variance and bias. Simply put, an algorithm can’t simultaneously be more complex and less complex at the same time.
Ensemble Learning Techniques - Combining Weak Learners
There are three main ensemble techniques: bagging, boosting and stacking. There are defined as follows:
Bagging:
Bagging attempts to incorporate similar learners on small-sample populations and calculates the average of all the predictions. Generally, bagging allows you to use different learners in different populations. By doing so, this method helps to reduce the variance error.
Boosting
Boosting is an iterative method that fine-tunes the weight of an observation according to the most recent classification. If an observation was incorrectly classified, this method will increase the weight of that observation in the next round (in which the next model will be trained) and will be less prone to misclassification. Similarly, if an observation was classified correctly, then it will reduce its weight for the next classifier. The weight represents how important the correct classification of the specific data point should be, as this enables the sequential classifiers to focus on examples previously misclassified. Generally, boosting reduces the bias error and forms strong predictive models, but at times they may overfit on the training data.
Stacking
Stacking is a clever way of combining the information provided by different models. With this method, a learner of any sort can be used to combine different learners’ outputs. The result can be a decrease in bias or variance determined by which combined models are used.
The Promise of Ensemble Learning
Ensemble learning is about combining multiple base models to achieve a more effective and accurate ensemble model that features more powerful properties and thus, performs better. Ensemble learning methods have successfully set record performances on challenging datasets and are constantly a part of the winning submissions of Kaggle competitions.
It’s worth noting that even with the three main ensemble techniques – bagging, boosting and stacking – variants are still possible and can be better designed to more effectively adapt to specific problems, such as classifications, regression, time-series analyses, etc. This first requires an understanding of the problem at hand and to be creative in approaching problem solving!
Using ensemble learning methods is a great, promising way to start approaching any problem.
Bio: Ido Zehori is the Data Science Team Leader at Bigabid, a data science company that has developed a second-generation DSP optimized for in-app advertising user acquisition & re-engagement, providing both the scale of a tier-1 DSP and the precision of a cutting edge DMP.
Related:
- Ensemble Methods for Machine Learning: AdaBoost
- Random Forest® — A Powerful Ensemble Learning Algorithm
- Explaining Black Box Models: Ensemble and Deep Learning Using LIME and SHAP