Google Open Sources SimCLR, A Framework for Self-Supervised and Semi-Supervised Image Training
The new framework uses contrastive learning to improve image analysis in unlabeled datasets.

High quality labeled datasets remain one of the biggest obstacles for the mainstream adoption of machine learning technologies. While we are seeing unprecedented advancements in machine learning research and technology, many of those methods can’t be widely adopted due to limitations in the creation of training datasets. That hurtle has propelled research in alternative methods such as semi-supervised and self-supervised learning which are able to operate by pretraining with unlabeled datasets. In the language analysis front, we have seen remarkable achievements of these type of techniques with models such as Google BERT or Microsoft Turin-NLG breaking records in performance and efficiency. Other deep learning domains remain behind in the adoption of semi-supervised and self-supervised models. To address that challenge, Google recently unveiled SimCLR, a framework for advancing self-supervised and semi-supervised models for image analysis.
The goal of self-supervised and semi-supervised learning methods is to transform an unsupervised learning problem into a supervised one by creating surrogate labels from the unlabeled dataset. In the case of vision analysis models, this problem has many particularities. Despite recent advancements in this area of research, learning effective visual representations without human supervision is a long-standing problem. Most mainstream approaches fall into one of two classes:
- Generative: These methods learn to generate or otherwise model pixels in the input space. However, pixel-level generation is computationally expensive and may not be necessary for representation learning.
- Discriminative: These methods learn representations using objective functions similar to those used for supervised learning, but train networks to perform pretext tasks where both the inputs and labels are derived from an unlabeled dataset. Many such approaches have relied on heuristics to design pretext tasks, which could limit the generality of the learned representations.
Discriminative approaches have shown a lot of promise in recent years, particularly accelerated by a relatively unknown paradigm called contrastive learning.
Contrastive Learning
One of the hallmarks of human’s vision cognition is to rapidly determine similarities and differences in sets of images. When applied to deep learning models, this ability to detect distinctiveness is what we know as contrastive learning. Conceptually, contrastive learning can be defined as the ability to learn representations by enforcing similar elements to be equal and dissimilar elements to be different.
The key idea behind contrastive learning is to expand learning beyond high level features. For instance, suppose that we are trying to determine differences in the tail of two images of whales. Sometimes high level features such as color and size are not sufficient because they are going to be too similar in the different pictures. Contrastive learning, combines those high level features with local and global features that can contextualize the analysis in order to determine similarities and differences between images.
SimCLR
Building on the principles of contrastive learning, SimCLR provides a model that learns representations by maximizing agreement between differently augmented views of the same data example via a contrastive loss in the latent space. Conceptually, SimCLR is based on the following components:
- Stochastic Data Augmentation Module: This component transforms any given data example stochastically generating two correlated views of the same example. Specifically, this module applies three different data transformations to a given input: random cropping, random color distortions and random Gaussian blur.
- Base Encoder: This component extracts representation vectors from augmented data samples. The output of the last average pooling layer used for extracting representations.
- Projection Head: This component maps representations to the space where contrastive loss is applied.
- Contrastive Loss Function: This component takes as an input a set of examples including a positive pair of examples (xi and xj) and aims to identify xj in the given set for a given xi.
The following image illustrates the relationship between the components listed above:
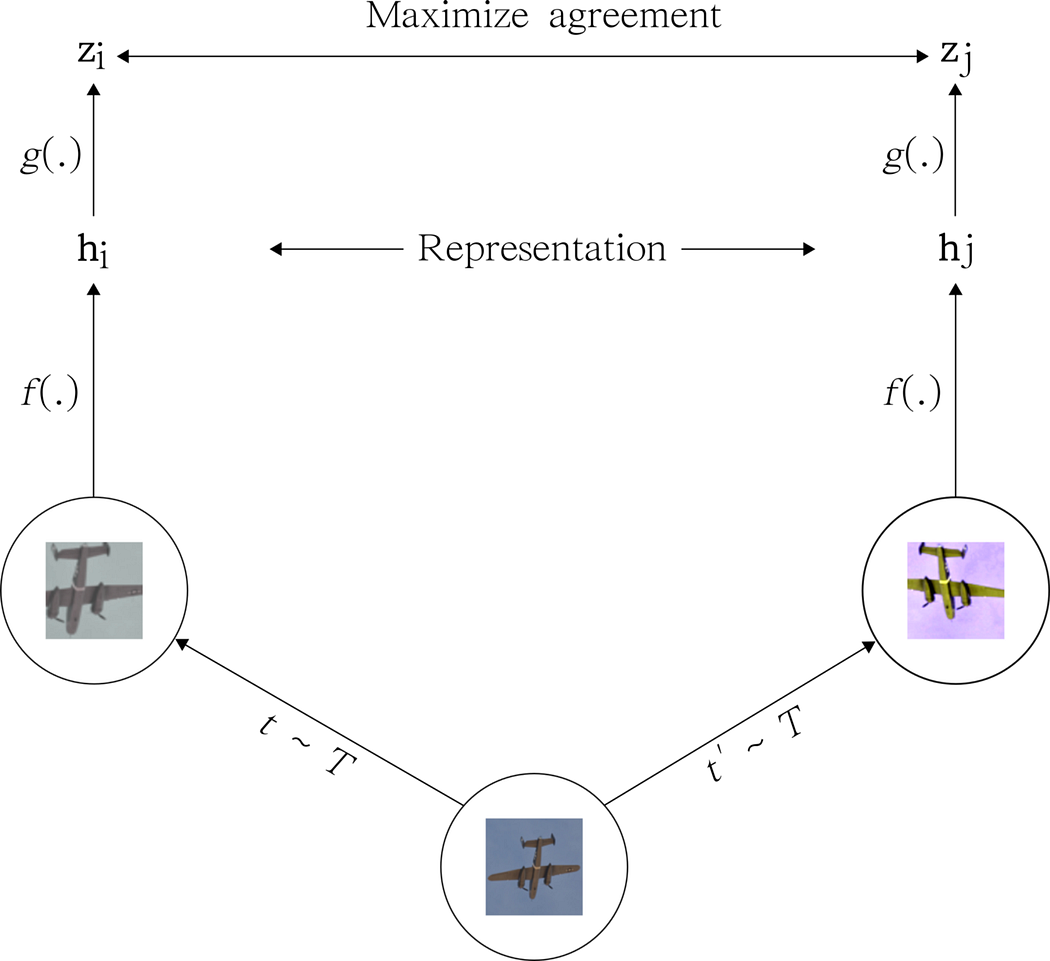
SimCLR maps the previous conceptual components onto a clever deep neural network architecture. The core architecture is inspired in residual neural networks(ResNet). Initially, SimCLR randomly draws examples from the original dataset, transforming each example twice using a combination of simple augmentations (random cropping, random color distortion, and Gaussian blur), creating two sets of corresponding views. After that, the framework computes the image representation using a convolutional neural network(CNN) based on the ResNet architecture. SimCLR complements that step by computing the non-linear projection of the image presentation using a multi-layer-perception layer. This step mplifies the invariant features and maximizes the ability of the network to identify different transformations of the same image. The output of both the CNN and the MLP layer is optimized using a stochastic gradient descent in order to minimize the loss function of the contrastive objective.

The initial implementation of SimCLR incorporate some important best practices that distinguished it from alternative methods. Let’s explore a few of those:
1) Multiple transformations generate better representations.
SimCLR incorporates different transformations that can be applied to the image input dataset. The experiments with SimCLR discovered that no single transformation suffices to define a prediction task that yields the best representations, two transformations stand out: random cropping and random color distortion. Although neither cropping nor color distortion leads to high performance on its own, composing these two transformations leads to state-of-the-art results.

2) Nonlinear projections are important
SimCLR leverages an MLP layer to implement a nonlinear projection to the image before the loss function is calculated. The idea is that the nonlinear projection would help to identify the invariant features of each input image and maximize the ability of the network to identify different transformations of the same image. The initial experiments showed that the nonlinear project helps to improve the learned representation by more than 10%.
3) Scaling up significantly improves performance
SimCLR experiments showed that scaling up measures such as (1) processing more examples in the same batch, (2) using bigger networks, and (3) training for longer all lead to significant improvements. From that perspective, optimizing for scaled up training is important when using SimCLR.
SimCLR showed remarkable performance improvements compared to other self-supervised and semi-supervised models for image classification. Larger versions of SimCLR achieved levels of performance comparable to the equivalent supervised task.

SimCLR incorporates some very innovative techniques to improve self-supervised and semi-supervised models for image analysis. In particular, the use of contrastive learning techniques is something relatively nascent but very promising in this space. The open source release of SimCLR can be found in GitHub and is based on this research paper.
Original. Reposted with permission.
Related:
- The Double Descent Hypothesis: How Bigger Models and More Data Can Hurt Performance
- OpenAI Open Sources Microscope and the Lucid Library to Visualize Neurons in Deep Neural Networks
- Google Open Sources TFCO to Help Build Fair Machine Learning Models