OpenAI Open Sources Microscope and the Lucid Library to Visualize Neurons in Deep Neural Networks
The new tools shows the potential of data visualizations for understanding features in a neural network.

Interpretability is one of the most challenging aspects of the deep learning space. Imagine understanding a neural network with hundreds of thousands of neurons distributed across thousands of hidden layers. The interconnected and complex nature of most deep neural networks makes unsuitable for traditional debugging tools. As a result, data scientists often rely on visualization techniques that help them understand how neural networks make decisions which becomes an constant challenge. To advance this area, OpenAI just unveiled Microscope and the Lucid Library which enable the visualization of neurons within a neural network.
Interpretability is a desirable property in deep neural network solutions until you need to sacrifice other aspects such as accuracy. The friction between the interpretability and accuracy capabilities of deep learning models is the friction between being able to accomplish complex knowledge tasks and understanding how those tasks were accomplished. Knowledge vs. Control, Performance vs. Accountability, Efficiency vs. Simplicity…pick your favorite dilemma and they all can be explained by balancing the tradeoffs between accuracy and interpretability. Many deep learning techniques are complex in nature and, although they result very accurate in many scenarios, they can become incredibly difficult to interpret. All deep learning models have certain degree of interpretability but the specifics of it depends on a few key building blocks.
The Building Blocks of Interpretability
When comes to deep learning models, interpretability is not a single concept but a combination of different principles. In a recent paper, researchers from Google outlined what they considered some of the foundational building blocks of interpretability. The paper presents three fundamental characteristics that make a model interpretable:
Understanding what Hidden Layers Do: The bulk of the knowledge in a deep learning model is formed in the hidden layers. Understanding the functionality of the different hidden layers at a macro level is essential to be able to interpret a deep learning model.
- Understanding How Nodes are Activated: The key to interpretability is not to understand the functionality of individual neurons in a network but rather groups of interconnected neurons that fire together in the same spatial location. Segmenting a network by groups of interconnected neurons will provide a simpler level of abstraction to understand its functionality.
- Understanding How Concepts are Formed: Understanding how deep neural network forms individual concepts that can then be assembled into the final output is another key building block of interpretability.
Borrowing Inspiration from Natural Sciences
Outlining the key building blocks of interpretability was certainly a step on the right direction but is far from being universally adopted. One of the few things that the majority of the deep learning community agrees when comes to interpretability is that we don’t even have the right definition.
In the absence of the solid consensus around interpretability, the answer might rely on diving deeper into our understanding of the decision making process in neural networks. That approached seemed to have worked for many other areas of science. For instance, at a time where there was not fundamental agreement about the structure of organisms, the invention of the microscope enabled the visualization of cells which catalyzed the cellular biology revolution.
Maybe we need a microscope for neural networks.
Microscope
OpenAI Microscope is a collection of visualizations of common deep neural networks in order to facilitate their interpretability. Microscope makes it easier to analyze the features that form inside these neural networks as well as the connections between its neurons.
Let’s take the famous AlexNet neural network which was the winning entry winning entry in ILSVRC 2012. It solves the problem of image classification where the input is an image of one of 1000 different classes (e.g. cats, dogs etc.) and the output is a vector of 1000 numbers.
Using OpenAI Microscope, we can select a sample dataset and visualize the core architecture of AlexNet alongside the state of the image classification process on each layer.

Upon selecting a specific layer (ex: conv5_1) Microscope will present a visualization of the different hidden units in that layer.
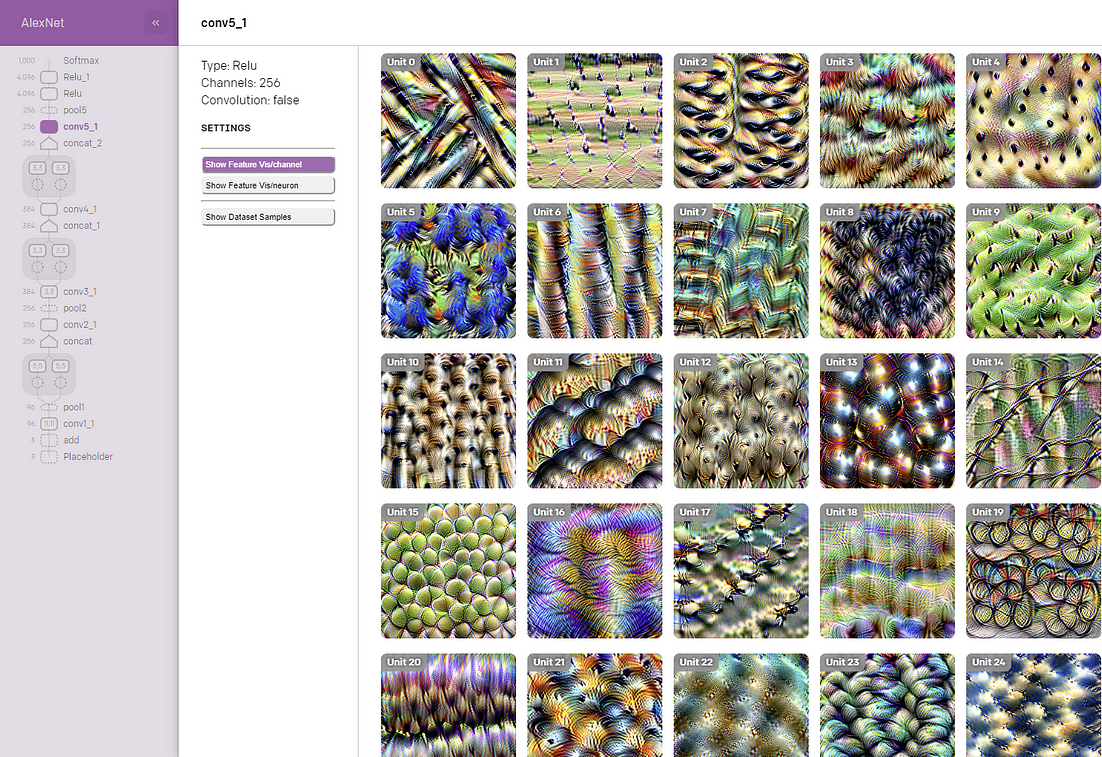
After selecting a layer, Microscope will visualize the corresponding features as well as the elements of the training dataset that were relevant to its formation.
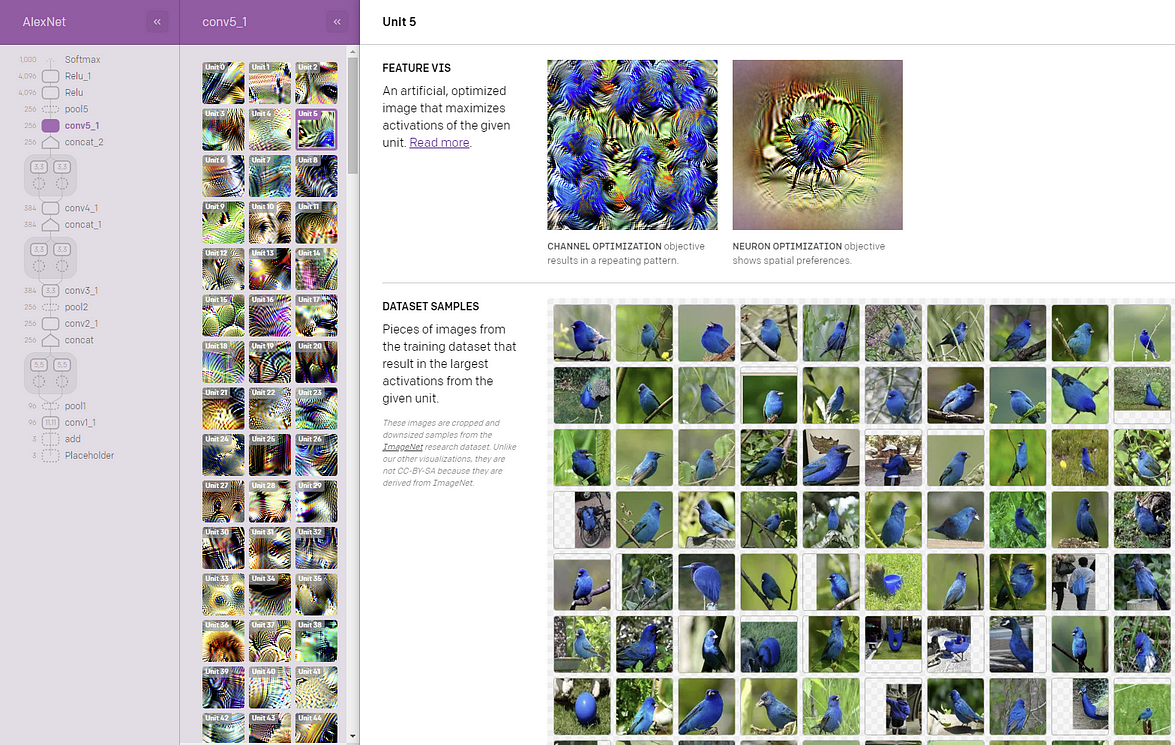
Navigating through Microscope can help illustrate how clever visualizations can help improve the interpretability of specific deep neural networks. To expand in the initial research, OpenAI also open sourced a framework to reuse some of the existing visualization models.
The Lucid Library
The Lucid Library is an open source framework to improve the interpretation of deep neural networks. The current release includes all the visualizations included in Miroscope.
Using Lucid is extremely simple. The framework can be installed as a simple Python package.
# Install Lucid
!pip install --quiet lucid==0.2.3
#!pip install --quiet --upgrade-strategy=only-if-needed git+https://github.com/tensorflow/lucid.git
# %tensorflow_version only works on colab
%tensorflow_version 1.x
# Imports
import numpy as np
import tensorflow as tf
assert tf.__version__.startswith('1')
import lucid.modelzoo.vision_models as models
from lucid.misc.io import show
import lucid.optvis.objectives as objectives
import lucid.optvis.param as param
import lucid.optvis.render as render
import lucid.optvis.transform as transform
# Let's import a model from the Lucid modelzoo!
model = models.InceptionV1()
model.load_graphdef()
Visualizing a neuron using Lucid is just a matter of calling the render_vis operation.
# Visualizing a neuron is easy! _ = render.render_vis(model, "mixed4a_pre_relu:476")

Additionally, Lucid produces different types of visualization that can help interpret layers and neurons:
- Objectives: What do you want the model to visualize?
- Parameterization: How do you describe the image?
- Transforms: What transformations do you want your visualization to be robust to?
The following code visualized a neuron with a specific objective.
# Let's visualize another neuron using a more explicit objective:
obj = objectives.channel("mixed4a_pre_relu", 465)
_ = render.render_vis(model, obj)

Both Microscope and the Lucid library are major improvements in the area of model interpretability. The idea of understanding features and neuron relationships is fundamental to evolve our understanding of deep learning models and releases like Microscope and Lucid are a solid step in the right direction.
Original. Reposted with permission.
Related:
- Google Open Sources MobileNetV3 with New Ideas to Improve Mobile Computer Vision Models
- OpenAI is Adopting PyTorch… They Aren’t Alone
- Sharing your machine learning models through a common API