Google Open Sources MobileNetV3 with New Ideas to Improve Mobile Computer Vision Models
The latest release of MobileNets incorporates AutoML and other novel ideas in mobile deep learning.

Mobile deep learning is becoming one of the most active areas of research in the artificial intelligence(AI) space. Designing deep learning models that can execute efficiently on mobile runtimes requiring rethinking many of the architecture paradigms in neural networks. Mobile deep learning models need to balance the accuracy of complex neural network structures with the performance constraints of mobile runtimes. Among the areas of mobile deep learning, computer vision remains one of the most challenging ones. In 2017, Google introduced MobileNets, a family of computer vision models based on TensorFlow. The newest architecture of architecture of MobileNets was unveiled a few days ago and contains a few interesting ideas to improve mobile computer vision models.
MobileNetV3 is the third version of the architecture powering the image analysis capabilities of many popular mobile applications. The architecture has also been incorporated in popular frameworks such as TensorFlow Lite. MobileNets need to carefully balance the advancements in computer vision and deep learning in general with the limitations of mobile environments. Google has regularly been releasing updates to the MobileNets architecture which incorporate some of the most novel ideas in the deep learning space.
MobileNetV1
The first version of MobileNets was released in the spring of 2017. The core idea was to introduce a series of TensorFlow-based computer vision models that maximize accuracy while being mindful of the restricted resources for an on-device or embedded application. Conceptually, MobileNetV1 is trying to achieve two fundamental goals in order to build mobile-first computer vision models:
- Smaller model size: Fewer number of parameters
- Smaller complexity: Fewer Multiplications and Additions
Following those principles, MobileNetV1 are small, low-latency, low-power models parameterized to meet the resource constraints of a variety of use cases. They can be built upon for classification, detection, embeddings and segmentation.
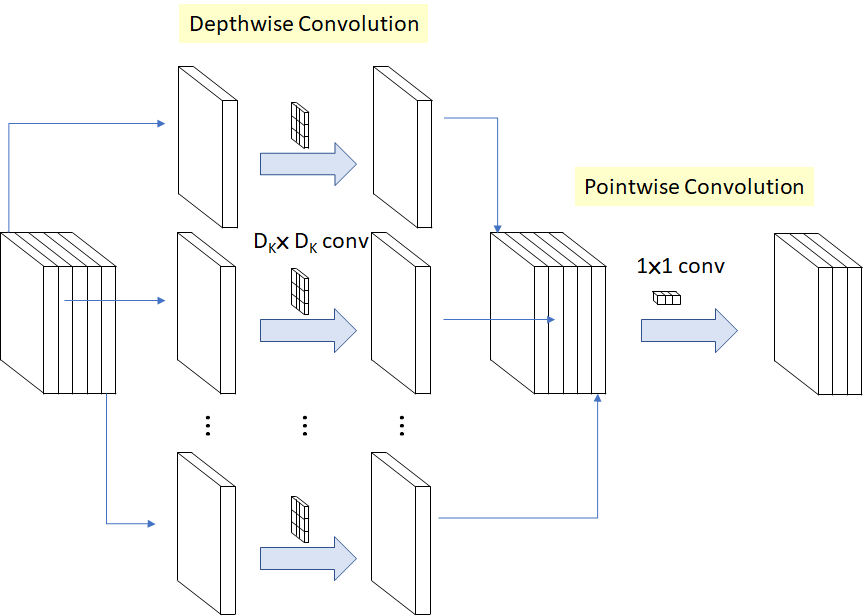
The core architecture of MobileNetV1 is based on a streamlined architecture that uses depth-wise separable convolutions to build light weight deep neural networks. In terms of neural network architectures, depth-wise separable convolution is a depth-wise convolution followed by a pointwise convolution as illustrated in the following figure. In MobileNetV1, the depth-wise convolution applies a single filter to each input channel. The pointwise convolution then applies a 1×1 convolution to combine the outputs the depth-wise convolution. A standard convolution both filters and combines inputs into a new set of outputs in one step. The depth-wise separable convolution splits this into two layers, a separate layer for filtering and a separate layer for combining.
The first MobileNetV1 implementation was included as part of the TensorFlow-Slim Image Classification Library. As new mobile applications were built using this new paradigm, new ideas emerged to improve the overall architecture.
MobileNetV2
The second version of the MobileNet architecture was unveiled in early 2018. MobileNetV2 built on some of the ideas of its predecessor and incorporated new ideas to optimize the architecture for tasks such as classification, object detection and semantic segmentation. From the architecture standpoint, MobileNetV2 introduced two new features to the architecture:
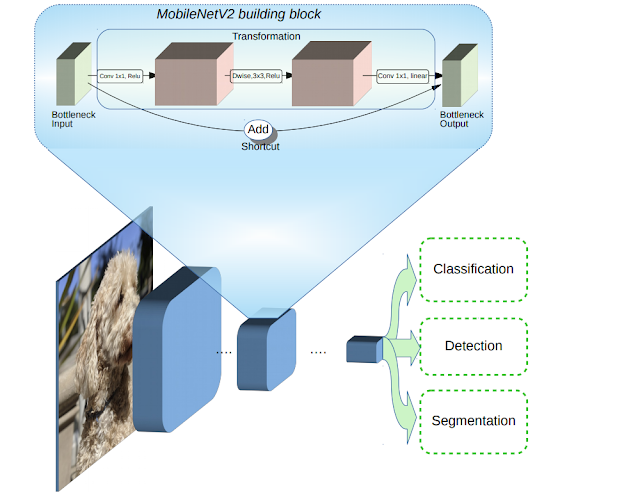
- linear bottlenecks between the layers
- shortcut connections between the bottlenecks1. The basic structure is shown below.
The core idea behind MobileNetV2 is that the bottlenecks encode the model’s intermediate inputs and outputs while the inner layer encapsulates the model’s ability to transform from lower-level concepts such as pixels to higher level descriptors such as image categories. Finally, as with traditional residual connections, shortcuts enable faster training and better accuracy.
MobileNetsV3
The latest improvements to the MobileNets architecture were summarized in a research paper published in August this year. The main contribution of MobileNetV3 is the use of AutoML to find the best possible neural network architecture for a given problem. This contrast with the hand-crafted design of previous versions of the architecture. Specifically, MobileNetV3 leverages two AutoML techniques: MnasNet and NetAdapt. MobileNetV3 first searches for a coarse architecture using MnasNet, which uses reinforcement learning to select the optimal configuration from a discrete set of choices. After that, the model fine-tunes the architecture using NetAdapt, a complementary technique that trims under-utilized activation channels in small decrements.
Another novel idea of MobileNetV3 is the incorporation of an squeeze-and-excitation block into the core architecture. The core idea of the squeeze-and-excitation blocks is to improve the quality of representations produced by a network by explicitly modelling the interdependencies between the channels of its convolutional features. To this end, we propose a mechanism that allows the network to perform feature recalibration, through which it can learn to use global information to selectively emphasize informative features and suppress less useful ones. In the case of MobileNetV3, the architecture extends MobileNetV2 incorporates squeeze-and-excitation blocks as part of the search space which ended up yielding more robust architectures.
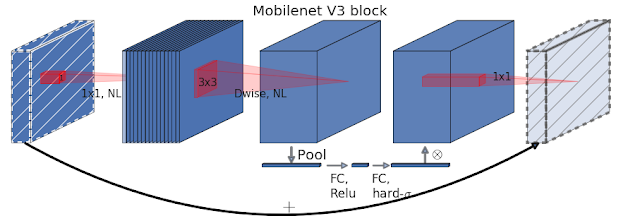
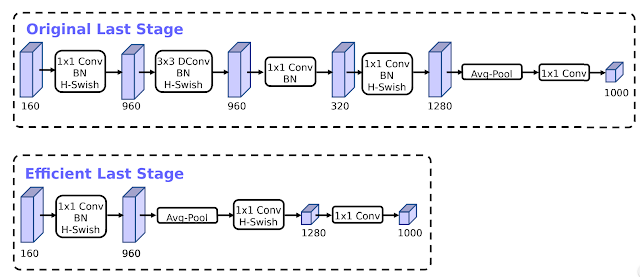
An interesting optimization of MobileNetV3 was the redesign of some of the expensive layers in the architecture. Some of the layers in MobileNetV2 were foundational to the accuracy of the models but also introduced concerning levels of latency. By incorporating some basic optimizations, MobileNetV3 was able to remove three expensive layers of its predecessor architecture without sacrificing accuracy.
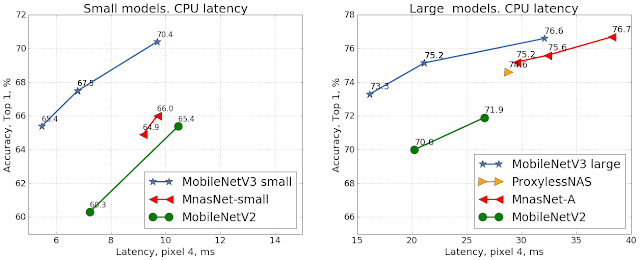
MobileNetV3 has shown significant improvements over previous architectures. For instance, in object detection tasks, MobileNetV3 operated with 25% less latency and the same accuracy of previous versions. Similar improvements were seen in classification tasks as illustrated in the following figure:
MobileNets remain one of the most advanced architecture in mobile computer vision. The incorporation of AutoML in MobileNetV3 certainly opens the door to all sorts of interesting architectures that we haven’t thought of before. The latest release of MobileNets is available in GitHub and the implementation of MobileNetV3 is included in the Tensorflow Object Detection API.
Original. Reposted with permission.
Related:
- Introduction to Image Segmentation with K-Means clustering
- Comparing MobileNet Models in TensorFlow
- Open Source Projects by Google, Uber and Facebook for Data Science and AI