Markov Chains: How to Train Text Generation to Write Like George R. R. Martin
Read this article on training Markov chains to generate George R. R. Martin style text.

Markov chains have been around for a while now, and they are here to stay. From predictive keyboards to applications in trading and biology, they’ve proven to be versatile tools.
Here are some Markov Chains industry applications:
- Text Generation (you’re here for this).
- Financial modelling and forecasting (including trading algorithms).
- Logistics: modelling future deliveries or trips.
- Search Engines: PageRank can seen as modelling a random internet surfer with a Markov Chain.
So far, we can tell this algorithm is useful, but what exactly are Markov Chains?
What are Markov Chains?
A Markov Chain is a stochastic process that models a finite set of states, with fixed conditional probabilities of jumping from a given state to another.
What this means is, we will have an “agent” that randomly jumps around different states, with a certain probability of going from each state to another one.
To show what a Markov Chain looks like, we can use a digraph, where each node is a state (with a label or associated data), and the weight of the edge that goes from node a to node b is the probability of jumping from state a to state b.
Here’s an example, modelling the weather as a Markov Chain.
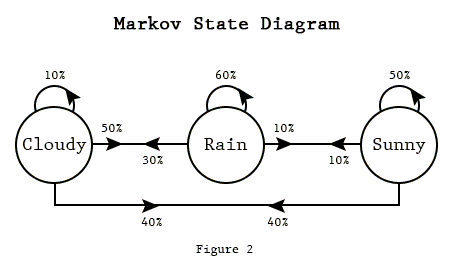
We can express the probability of going from state a to state b as a matrix component, where the whole matrix characterizes our Markov chain process, corresponding to the digraph’s adjacency matrix.
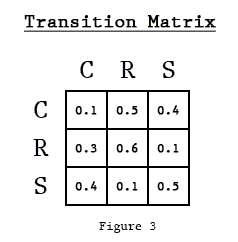
Then, if we represent the current state as a one-hot encoding, we can obtain the conditional probabilities for the next state’s values by taking the current state, and looking at its corresponding row.
After that, if we repeatedly sample the discrete distribution described by the n-th state’s row, we may model a succession of states of arbitrary length.
Markov Chains for Text Generation
In order to generate text with Markov Chains, we need to define a few things:
- What are our states going to be?
- What probabilities will we assign to jumping from each state to a different one?
We could do a character-based model for text generation, where we define our state as the last n characters we’ve seen, and try to predict the next one.
I’ve already gone in-depth on this for my LSTM for Text Generation article, to mixed results.
In this experiment, I will instead choose to use the previous k words as my current state, and model the probabilities of the next token.
In order to do this, I will simply create a vector for each distinct sequence of k words, having N components, where N is the total quantity of distinct words in my corpus.
I will then add 1 to the j-th component of the i-th vector, where i is the index of the i-th k-sequence of words, and j is the index of the next word.
If I normalize each word vector, I will then have a probability distribution for the next word, given the previous k tokens.
Confusing? Let’s see an example with a small corpus.
Training our chain: toy example.
Let’s imagine my corpus is the following sentence.
This sentence has five words
We will first choose k: the quantity of words our chain will consider before sampling/predicting the next one. For this example, let’s use k=1.
Now, how many distinct sequences of 1 word does our sentence have? It has 5, one for each word. If it had duplicate words, they wouldn’t add to this number.
We will first initialize a 5×5 matrix of zeroes.
After that, we will add 1 to the column corresponding to ‘sentence’ on the row for ‘this’. Then another 1 on the row for ‘sentence’, on the column for ‘has’. We will continue this process until we’ve gone through the whole sentence.
This would be the resulting matrix:
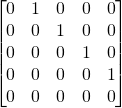
The diagonal pattern comes from the ordering of the words.
Since each word only appears once, this model would simply generate the same sentence over and over, but you can see how adding more words could make this interesting.
I hope things are clearer now. Let’s jump to some code!
Coding our Markov Chain in Python
Now for the fun part! We will train a Markov chain on the whole A Song of Ice and Fire corpus (Ha! You thought I was going to reference the show? Too bad, I’m a book guy!).
We will then generate sentences with varying values for k.
For this experiment, I decided to treat anything between two spaces as a word or token.
Conventionally, in NLP we treat punctuation marks (like ‘,’ or ‘.’) as tokens as well. To solve this, I will first add padding in the form of two spaces to every punctuation mark.
Here’s the code for that small preprocessing, plus loading the corpus:
corpus = ""
for file_name in file_names:
with open(file_name, 'r') as f:
corpus+=f.read()
corpus = corpus.replace('\n',' ')
corpus = corpus.replace('\t',' ')
corpus = corpus.replace('“', ' " ')
corpus = corpus.replace('”', ' " ')
for spaced in ['.','-',',','!','?','(','—',')']:
corpus = corpus.replace(spaced, ' {0} '.format(spaced))
len(corpus) #10510355 characters
We will start training our Markov Chain right away, but first let’s look at our dataset:
corpus_words = corpus.split(' ')
corpus_words= [word for word in corpus_words if word != '']
corpus_words # [...'a', 'wyvern', ',', 'two', 'of', 'the', 'thousand'...]
len(corpus_words) # 2185920
distinct_words = list(set(corpus_words))
word_idx_dict = {word: i for i, word in enumerate(distinct_words)}
distinct_words_count = len(list(set(corpus_words)))
distinct_words_count # 32663
We have over 2 million tokens, representing over 32000 distinct words! That’s a pretty big corpus for a single writer.
If only he could add 800k more…
Training our chain
Moving on, here’s how we initialize our “word after k-sequence” counts matrix for an arbitrary k (in this case, 2).
There are 2185918 words in the corpus, and 429582 different sequences of 2 words, each followed by one of 32663 words.
That means only slightly over 0.015% of our matrix’s components will be non-zero.
Because of that, I used scipy’s dok_matrix (dok stands for Dictionary of Keys), a sparse matrix implementation, since we know this dataset is going to be extremely sparse.
k = 2 # adjustable
sets_of_k_words = [ ' '.join(corpus_words[i:i+k]) for i, _ in enumerate(corpus_words[:-k]) ]
from scipy.sparse import dok_matrix
sets_count = len(list(set(sets_of_k_words)))
next_after_k_words_matrix = dok_matrix((sets_count, len(distinct_words)))
distinct_sets_of_k_words = list(set(sets_of_k_words))
k_words_idx_dict = {word: i for i, word in enumerate(distinct_sets_of_k_words)}
for i, word in enumerate(sets_of_k_words[:-k]):
word_sequence_idx = k_words_idx_dict[word]
next_word_idx = word_idx_dict[corpus_words[i+k]]
next_after_k_words_matrix[word_sequence_idx, next_word_idx] +=1
After initializing our matrix, sampling it is pretty intuitive.
Here’s the code for that:
def sample_next_word_after_sequence(word_sequence, alpha = 0):
next_word_vector = next_after_k_words_matrix[k_words_idx_dict[word_sequence]] + alpha
likelihoods = next_word_vector/next_word_vector.sum()
return weighted_choice(distinct_words, likelihoods.toarray())
def stochastic_chain(seed, chain_length=15, seed_length=2):
current_words = seed.split(' ')
if len(current_words) != seed_length:
raise ValueError(f'wrong number of words, expected {seed_length}')
sentence = seed
for _ in range(chain_length):
sentence+=' '
next_word = sample_next_word_after_sequence(' '.join(current_words))
sentence+=next_word
current_words = current_words[1:]+[next_word]
return sentence
# example use
stochastic_chain('the world')
There are two things that may have caught your attention here. The first is the alpha hyperparameter.
This is our chain’s creativity: a (typically small, or zero) chance that it will pick a totally random word instead of the ones suggested by the corpus.
If the number is high, then the next word’s distribution will approach uniformity. If zero or closer to it, then the distribution will more closely resemble that seen in the corpus.
For all the examples I’ll show, I used an alpha value of 0.
The second thing is the weighted_choice function. I had to implement it since Python’s random package doesn’t support weighted choice over a list with more than 32 elements, let alone 32000.
Results: Generated Sentences
First of all, as a baseline, I tried a deterministic approach: what happens if we pick a word, use k=1, and always jump to the most likely word after the current one?
The results are underwhelming, to say the least.
I am not have been a man , and the Wall . " " " " he was a man , and the Wall . " " " " " " " she had been a man , and the Wall . " " " " " "
Since we’re being deterministic, ‘a’ is always followed by ‘man’, ‘the’ is always followed by ‘Wall’ (hehe) and so on.
This means our sentences will be boring, predictable and kind of nonsensical.
Now for some actual generation, I tried using a stochastic Markov Chain of 1 word, and a value of 0 for alpha.
1-word Markov Chain results
Here are some of the resulting 15-word sentences, with the seed word in bold letters.
'the Seven in front of whitefish in a huge blazes burning flesh . I had been' 'a squire , slain , they thought . " He bathed in his head . The' 'Bran said Melisandre had been in fear I’ve done . " It must needs you will' 'Melisandre would have feared he’d squired for something else I put his place of Ser Meryn' 'Daenerys is dead cat - TOOTH , AT THE GREAT , Asha , which fills our' 'Daenerys Targaryen after Melara had worn rich grey sheep to encircle Stannis . " The deep'
As you can see, the resulting sentences are quite nonsensical, though a lot more interesting than the previous ones.
Each individual pair of words makes some sense, but the whole sequence is pure non-sequitur.
The model did learn some interesting things, like how Daenerys is usually followed by Targaryen, and ‘would have feared’ is a pretty good construction for only knowing the previous word.
However, in general, I’d say this is nowhere near as good as it could be.
When increasing the value of alpha for the single-word chain, the sentences I got started turning even more random.
Results with 2-word Markov chains
The 2-word chain produced some more interesting sentences.
Even though it too usually ends sounding completely random, most of its output may actually fool you for a bit at the beginning (emphasis mine).
'the world . And Ramsay loved the feel of grass welcomed them warmly , the axehead flew' 'Jon Snow . You are to strike at him . The bold ones have had no sense' 'Eddard Stark had done his best to give her the promise was broken . By tradition the' 'The game of thrones , so you must tell her the next buyer who comes running ,' 'The game trail brought her messages , strange spices . The Frey stronghold was not large enough' 'heard the scream of fear . I want to undress properly . Shae was there , fettered'
The sentences maintain local coherence (You are to strike at him, or Ramsay loved the feel of grass), but then join very coherent word sequences into a total mess.
Any sense of syntax, grammar or semantics is clearly absent.
By the way, I didn’t cherry-pick those sentences at all, those are the first outputs I sampled.
Feel free to play with the code yourself, and you can share the weirdest sentences you get in the comments!
Since we’re using two sentences as keys now, we can’t let the chain ‘get creative’ as in the previous one-word case. Therefore, the alpha value had to be kept on 0.
As an alternative, I thought of setting it a bit higher, and then always selecting the closest FuzzyWuzzy string matching (an approximation of string equality) instead of exact matching. I may try that in the future, though I’m not sure the results will be good.
As a last experiment, let’s see what we get with a 3-word Markov Chain.
3-Word Chain Results
Here are some of the sentences the model generated when trained with sequences of 3 words.
'I am a master armorer , lords of Westeros , sawing out each bay and peninsula until the' 'Jon Snow is with the Night’s Watch . I did not survive a broken hip , a leathern' 'Jon Snow is with the Hound in the woods . He won’t do it . " Please don’t' 'Where are the chains , and the Knight of Flowers to treat with you , Imp . "' 'Those were the same . Arianne demurred . " So the fishwives say , " It was Tyrion’s' 'He thought that would be good or bad for their escape . If they can truly give us' 'I thought that she was like to remember a young crow he’d met briefly years before . "'
Alright, I really liked some of those, especially the last one. It kinda sounds like a real sentence you could find in the books.
Conclusion
Implementing a Markov Chain is a lot easier than it may sound, and training it on a real corpus was fun.
The results were frankly better than I expected, though I may have set the bar too low after my little LSTM fiasco.
In the future, I may try training this model with even longer chains, or a completely different corpus.
In this case, trying a 5-word chain had basically deterministic results again, since each 5-word sequence was almost always unique, so I did not consider 5-words and upwards chains to be of interest.
Which corpus do you think would generate more interesting results, Especially for a longer chain? Let me know in the comments!
Bio: Luciano Strika is a computer science student at Buenos Aires University, and a data scientist at MercadoLibre. He also writes about machine learning and data on www.datastuff.tech.
Original. Reposted with permission.
Related:
- Training a Neural Network to Write Like Lovecraft
- 3 Machine Learning Books that Helped me Level Up as a Data Scientist
- K-Means Clustering: Unsupervised Learning for Recommender Systems