 Training a Neural Network to Write Like Lovecraft
Training a Neural Network to Write Like Lovecraft
 Training a Neural Network to Write Like Lovecraft
Training a Neural Network to Write Like LovecraftIn this post, the author attempts to train a neural network to generate Lovecraft-esque prose, known to be awkward and irregular at best. Did it end in success? If not, any suggestions on how it might have? Read on to find out.

LSTM Neural Networks have seen a lot of use in the recent years, both for text and music generation, and for Time Series Forecasting.
Today, I’ll teach you how to train a LSTM Neural Network for text generation, so that it can write with H. P. Lovecraft’s style.
In order to train this LSTM, we’ll be using TensorFlow’s Keras API for Python.
I learned about this subject from this awesome LSTM Neural Networks tutorial. My code follows this Text Generation tutorial‘s closely.
I’ll show you my Python examples and results as usual, but first, let’s do some explaining.
What are LSTM Neural Networks?
The most vanilla, run-of-the-mill Neural Network, called a Multi-Layer-Perceptron, is just a composition of fully connected layers.
In these models, the input is a vector of features, and each subsequent layer is a set of “neurons”.
Each neuron performs an affine (linear) transformation to the previous layer’s output, and then applies some non-linear function to that result.
The output of a layer’s neurons, a new vector, is fed to the next layer, and so on.

A LSTM (Long Short-term Memory) Neural Network is just another kind of Artificial Neural Network, which falls in the category of Recurrent Neural Networks.
What makes LSTM Neural Networks different from regular Neural Networks is, they have LSTM cells as neurons in some of their layers.
Much like Convolutional Layers help a Neural Network learn about image features, LSTM cells help the Network learn about temporal data, something which other Machine Learning models traditionally struggled with.
How do LSTM cells work? I’ll explain it now, though I highly recommend you give those tutorials a chance too.
How do LSTM cells work?
An LSTM layer will contain many LSTM cells.
Each LSTM cell in our Neural Network will only look at a single column of its inputs, and also at the previous column’s LSTM cell’s output.
Normally, we feed our LSTM Neural Network a whole matrix as its input, where each column corresponds to something that “comes before” the next column.
This way, each LSTM cell will have two different input vectors: the previous LSTM cell’s output (which gives it some information about the previous input column) and its own input column.
LSTM Cells in action: an intuitive example.
For instance, if we were training an LSTM Neural Network to predict stock exchange values, we could feed it a vector with a stock’s closing price in the last three days.
The first LSTM cell, in that case, would use the first day as input, and send some extracted features to the next cell.
That second cell would look at the second day’s price, and also at whatever the previous cell learned from yesterday, before generating new inputs for the next cell.
After doing this for each cell, the last one will actually have a lot of temporal information. It will receive, from the previous one, what it learned from yesterday’s closing price, and from the previous two (through the other cells’ extracted information).
You can experiment with different time windows, and also change how many units (neurons) will look at each day’s data, but this is the general idea.
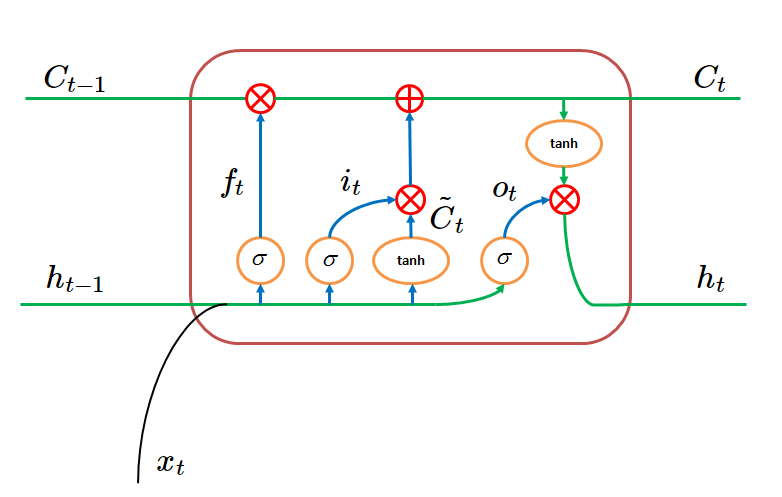
How LSTM Cells work: the Math.
The actual math behind what each cell extracts from the previous one is a bit more involved.
Forget Gate
The “forget gate” is a sigmoid layer, that regulates how much the previous cell’s outputs will influence this one’s.
It takes as input both the previous cell’s “hidden state” (another output vector), and the actual inputs from the previous layer.
Since it is a sigmoid, it will return a vector of “probabilities”: values between 0 and 1.
They will multiply the previous cell’s outputs to regulate how much influence they hold, creating this cell’s state.
For instance, in a drastic case, the sigmoid may return a vector of zeroes, and the whole state would be multiplied by 0 and thus discarded.
This may happen if this layer sees a very big change in the inputs distribution, for example.
Input Gate
Unlike the forget gate, the input gate’s output is added to the previous cell’s outputs (after they’ve been multiplied by the forget gate’s output).
The input gate is the dot product of two different layers’ outputs, though they both take the same input as the forget gate (previous cell’s hidden state, and previous layer’s outputs):
- A sigmoid unit, regulating how much the new information will impact this cell’s output.
- A tanh unit, which actually extracts the new information. Notice tanh takes values between -1 and 1.
The product of these two units (which could, again, be 0, or be exactly equal to the tanh output, or anything in between) is added to this neuron’s cell state.
The LSTM cell’s outputs
The cell’s state is what the next LSTM cell will receive as input, along with this cell’s hidden state.
The hidden state will be another tanh unit applied to this neuron’s state, multiplied by another sigmoid unit that takes the previous layer’s and cell’s outputs (just like the forget gate).
Here’s a visualization of what each LSTM cell looks like, borrowed from the tutorial I just linked:
Now that we’ve covered the theory, let’s move on to some practical uses!
As usual, all of the code is available on GitHub if you want to try it out, or you can just follow along and see the gists.
Training LSTM Neural Networks with TensorFlow Keras
For this task, I used this dataset containing 60 Lovecraft tales.
Since he wrote most of his work in the 20s, and he died in 1937, it’s now mostly in the public domain, so it wasn’t that hard to get.
I thought training a Neural Network to write like him would be an interesting challenge.
This is because, on the one hand, he had a very distinct style (with abundant purple prose: using weird words and elaborate language), but on the other he used a very complex vocabulary, and a Network may have trouble understanding it.
For instance, here’s a random sentence from the first tale in the dataset:
At night the subtle stirring of the black city outside, the sinister scurrying of rats in the wormy partitions, and the creaking of hidden timbers in the centuried house, were enough to give him a sense of strident pandemonium
If I can get a Neural Network to write “pandemonium”, then I’ll be impressed.
Preprocessing our data
In order to train an LSTM Neural Network to generate text, we must first preprocess our text data so that it can be consumed by the network.
In this case, since a Neural Network takes vectors as input, we need a way to convert the text into vectors.
For these examples, I decided to train my LSTM Neural Networks to predict the next M characters in a string, taking as input the previous N ones.
To be able to feed it the N characters, I did a one-hot encoding of each one of them, so that the network’s input is a matrix of CxN elements, where C is the total number of different characters on my dataset.
First, we read the text files and concatenate all of their contents.
We limit our characters to be alphanumerical, plus a few punctuation marks.
We can then proceed to one-hot encode the strings into matrices, where every element of the j-th column is a 0 except for the one corresponding to the j-th character in the corpus.
In order to do this, we first define a dictionary that assigns an index to each character.
Notice how, if we wished to sample our data, we could just make the variable slicessmaller.
I also chose a value for SEQ_LENGTH of 50, making the network receive 50 characters and try to predict the next 50.
Training our LSTM Neural Network
In order to train the Neural Network, we must first define it.
This Python code creates an LSTM Neural Network with two LSTM layers, each with 100 units.
Remember each unit has one cell for each character in the input sequence, thus 50.
Here VOCAB_SIZE is just the amount of characters we’ll use, and TimeDistributedis a way of applying a given layer to each different cell, maintaining temporal ordering.
For this model, I actually tried many different learning rates to test convergence speed vs overfitting.
Here’s the code for training:
What you are seeing is what had the best performance in terms of loss minimization.
However, with a binary_cross_entropy of 0.0244 in the final epoch (after 500 epochs), here’s what the model’s output looked like.
Tolman hast toemtnsteaetl nh otmn tf titer aut tot tust tot ahen h l the srrers ohre trrl tf thes snneenpecg tettng s olt oait ted beally tad ened ths tan en ng y afstrte and trr t sare t teohetilman hnd tdwasd hxpeinte thicpered the reed af the satl r tnnd Tev hilman hnteut iout y techesd d ty ter thet te wnow tn tis strdend af ttece and tn aise ecn
There are many good things about this output, and many bad ones as well.
The way the spacing is set up, with words mostly between 2 and 5 characters long with some longer outliers, is pretty similar to the actual word length distribution in the corpus.
I also noticed the letters ‘T’, ‘E’ and ‘I’ were appearing very commonly, whereas ‘y’ or ‘x’ were less frequent.
When I looked at letter relative frequencies in the sampled output versus the corpus, they were pretty similar. It’s the ordering that’s completely off.
There is also something to be said about how capital letters only appear after spaces, as is usually the case in English.
To generate these outputs, I simply asked the model to predict the next 50 characters for different 50 character subsets in the corpus. If it’s this bad with training data, I figured testing or random data wouldn’t be worth checking.
The nonsense actually reminded me of one of H. P. Lovecraft’s most famous tales, “Call of Cthulhu”, where people start having hallucinations about this cosmic, eldritch being, and they say things like:
Ph’nglui mglw’nafh Cthulhu R’lyeh wgah’nagl fhtagn.
Sadly the model wasn’t overfitting that either, it was clearly underfitting.
So I tried to make its task smaller, and the model bigger: 125 units, predicting only 30 characters.
Bigger model, smaller problem. Any results?
With this smaller model, after another 500 epochs, some patterns began to emerge.
Even though the loss function wasn’t that much smaller (at 210), the character’s frequency remained similar to the corpus’.
The ordering of characters improved a lot though: here’s a random sample from its output, see if you can spot some words.
the sreun troor Tvwood sas an ahet eae rin and t paared th te aoolling onout The e was thme trr t sovtle tousersation oefore tifdeng tor teiak uth tnd tone gen ao tolman aarreed y arsred tor h tndarcount tf tis feaont oieams wnd toar Tes heut oas nery tositreenic and t aeed aoet thme hing tftht to te tene Te was noewked ay tis prass s deegn aedgireean ect and tot ced the sueer anoormal -iuking torsarn oaich hnher tad beaerked toring the sars tark he e was tot tech
Tech, the, and, was… small words are where it’s at! It also realized many words ended with common suffixes like -ing, -ed, and -tion.
Out of 10000 words, 740 were “the“, 37 ended in “tion” (whereas only 3 contained without ending in it), and 115 ended in –ing.
Other common words were “than” and “that”, though the model was clearly still unable to produce English sentences.
Even bigger model
This gave me hopes. The Neural Network was clearly learning something, just not enough.
So I did what you do when your model underfits: I tried an even bigger Neural Network.
Take into account, I’m running this on my laptop.
With a modest 16GB of RAM and an i7 processor, these models take hours to learn.
So I set the amount of units to 150, and tried my hand again at 50 characters.
I figured maybe giving it a smaller time window was making things harder for the Network.
Here’s what the model’s output was like, after a few hours of training.
andeonlenl oou torl u aote targore -trnnt d tft thit tewk d tene tosenof the stown ooaued aetane ng thet thes teutd nn aostenered tn t9t aad tndeutler y aean the stun h tf trrns anpne thin te saithdotaer totre aene Tahe sasen ahet teae es y aeweeaherr aore ereus oorsedt aern totl s a dthe snlanete toase af the srrls-thet treud tn the tewdetern tarsd totl s a dthe searle of the sere t trrd eneor tes ansreat tear d af teseleedtaner nl and tad thre n tnsrnn tearltf trrn T has tn oredt d to e e te hlte tf the sndirehio aeartdtf trrns afey aoug ath e -ahe sigtereeng tnd tnenheneo l arther ardseu troa Tnethe setded toaue and tfethe sawt ontnaeteenn an the setk eeusd ao enl af treu r ue oartenng otueried tnd toottes the r arlet ahicl tend orn teer ohre teleole tf the sastr ahete ng tf toeeteyng tnteut ooseh aore of theu y aeagteng tntn rtng aoanleterrh ahrhnterted tnsastenely aisg ng tf toueea en toaue y anter aaneonht tf the sane ng tf the
Pure nonsense, except a lot of “the” and “and”s.
It was actually saying “the” more often than the previous one, but it hadn’t learned about gerunds yet (no -ing).
Interestingly, many words here ended with “-ed” which means it was kinda grasping the idea of the past tense.
I let it go at it a few hundred more epochs (to a total of 750).
The output didn’t change too much, still a lot of “the”, “a” and “an”, and still no bigger structure. Here’s another sample:
Tn t srtriueth ao tnsect on tias ng the sasteten c wntnerseoa onplsineon was ahe ey thet tf teerreag tispsliaer atecoeent of teok ond ttundtrom tirious arrte of the sncirthio sousangst tnr r te the seaol enle tiedleoisened ty trococtinetrongsoa Trrlricswf tnr txeenesd ng tispreeent T wad botmithoth te tnsrtusds tn t y afher worsl ahet then
An interesting thing that emerged here though, was the use of prepositions and pronouns.
The network wrote “I”, “you”, “she”, “we”, “of” and other similar words a few times. All in all, prepositions and pronouns amounted to about 10% of the total sampled words.
This was an improvement, as the Network was clearly learning low-entropy words.
However, it was still far from generating coherent English texts.
I let it train 100 more epochs, and then killed it.
Here’s its last output.
thes was aooceett than engd and te trognd tarnereohs aot teiweth tncen etf thet torei The t hhod nem tait t had nornd tn t yand tesle onet te heen t960 tnd t960 wndardhe tnong toresy aarers oot tnsoglnorom thine tarhare toneeng ahet and the sontain teadlny of the ttrrteof ty tndirtanss aoane ond terk thich hhe senr aesteeeld Tthhod nem ah tf the saar hof tnhe e on thet teauons and teu the ware taiceered t rn trr trnerileon and
I knew it was doing its best, but it wasn’t really going anywhere, at least not quickly enough.
I thought of accelerating convergence speed with Batch Normalization.
However, I read on StackOverflow that BatchNorm is not supposed to be used with LSTM Neural Networks.
If any of you is more experienced with LSTM nets, please let me know if that’s right in the comments!
At last, I tried this same task with 10 characters as input and 10 as output.
I guess the model wasn’t getting enough context to predict things well enough though: the results were awful.
I considered the experiment finished for now.
Conclusions
While it is clear, looking at other people’s work, that an LSTM Neural Network couldlearn to write like Lovecraft, I don’t think my PC is powerful enough to train a big enough model in a reasonable time.
Or maybe it just needs more data than I had.
In the future, I’d like to repeat this experiment with a word-based approach instead of a character-based one.
I checked, and about 10% of the words in the corpus appear only once.
Is there any good practice I should follow if I removed them before training? Like replacing all nouns with the same one, sampling from clusters, or something? Please let me know! I’m sure many of you are more experienced with LSTM neural networks than I.
Do you think this would have worked better with a different architecture? Something I should have handled differently? Please also let me know, I want to learn more about this.
Did you find any rookie mistakes on my code? Do you think I’m an idiot for not trying XYZ? Or did you actually find my experiment enjoyable, or maybe you even learned something from this article?
Contact me on Twitter, LinkedIn, Medium or Dev.to if you want to discuss that, or any related topic.
If you want to become a Data scientist, or learn something new, check out my Machine Learning Reading List!
Bio: Luciano Strika is a computer science student at Buenos Aires University, and a data scientist at MercadoLibre. He also writes about machine learning and data on www.datastuff.tech.
Original. Reposted with permission.
Related:
- Autoencoders: Deep Learning with TensorFlow’s Eager Execution
- 3 Machine Learning Books that Helped me Level Up as a Data Scientist
- Understanding Backpropagation as Applied to LSTM