
 The Death of Big Data and the Emergence of the Multi-Cloud Era
The Death of Big Data and the Emergence of the Multi-Cloud Era

 The Death of Big Data and the Emergence of the Multi-Cloud Era
The Death of Big Data and the Emergence of the Multi-Cloud EraThe Era of Big Data is coming to an end as the focus shifts from how we collect data to processing that data in real-time. Big Data is now a business asset supporting the next eras of multi-cloud support, machine learning, and real-time analytics.
By Hyoun Park, Amalgam Insights.

RIP Era of Big Data
April 1, 2006 – June 5, 2019
The Era of Big Data passed away on June 5, 2019, with the announcement of Tom Reilly’s upcoming resignation from Cloudera and subsequent market capitalization drop. Coupled with MapR’s recent announcement intending to shut down in late June, which will be dependent on whether MapR can find a buyer to continue operations, June of 2019 accentuated that the initial Era of Hadoop-driven Big Data has come to an end. Big Data will be remembered for its role in enabling the beginning of social media dominance, its role in fundamentally changing the mindset of enterprises in working with multiple orders of magnitude increases in data volume, and in clarifying the value of analytic data, data quality, and data governance for the ongoing valuation of data as an enterprise asset.
As I give a eulogy of sorts to the Era of Big Data, I do want to emphasize that Big Data technologies are not actually “dead,” but that the initial generation of Hadoop-based Big Data has reached a point of maturity where its role in enterprise data is established. Big Data is no longer part of the breathless hype cycle of infinite growth but is now an established technology.
Editor's note: See also Google Trends for Big Data and Hadoop
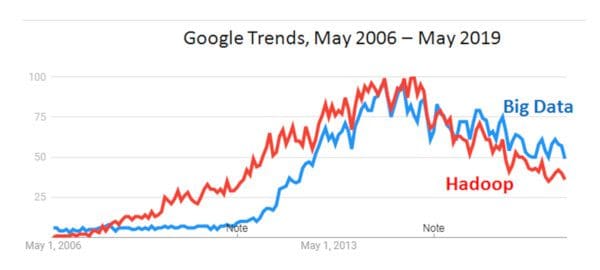
The Birth of Big Data
When the Era of Big Data started with the launch of Apache Hadoop in 2006, developers and architects saw this tool as an enabler to process and store multi-structured and semi-structured data. The fundamental shift in thinking of enterprise data beyond traditional enterprise database assumptions of ACID (atomicity, consistency, isolation, and durability), led to a transformation of data use cases as companies realized that data previously thrown away or kept in static archives could actually provide value to understanding customer behavior, propensity to take action, risk factors, and complex organizational, environmental, and business behaviors. The commercial value of Hadoop started to be established in 2009 with the launch of Cloudera as a commercial distribution, which was quickly followed by MapR, Hortonworks, and EMC Greenplum (now Pivotal HD). Although analysts provided heady projections of Big Data as a potential market of $50 billion or more, Hadoop ended up being challenged through the 2010s as an analytic tool.
Hadoop’s Challenges in the Enterprise World
Although Hadoop was very valuable in supporting large storage and ETL (Extract, Transform, and Load) jobs and in supporting machine learning tasks through batch processing, it was not optimal for supporting more traditional analytics jobs that businesses and large organizations used to manage day-to-day operations. Tools such as Hive, Dremel, and Spark were used on top of Hadoop to support analytics, but Hadoop never became fast enough to truly replace the data warehouse.
Hadoop also faced challenges from the advances in NoSQL databases and object storage providers in solving aspects of the storage and management challenges that Hadoop was originally designed to support. Over time, the challenges of supporting business continuity on Hadoop and the lack of flexibility in supporting real-time, geospatial, and other emerging analytics use cases made it difficult for Hadoop to evolve beyond batch processing for massive volumes of data.
In addition, over time, businesses started to find that their Big Data challenges were increasingly associated with supporting a wide variety of data sources and quickly adjusting data schemas, queries, definitions, and contexts to reflect the use of new applications, platforms, and cloud infrastructure vendors. To solve this challenge, analytics, integration, and replication had to both become more agile and more rapid. This challenge was reflected in the creation of a number of vendors ranging including:
- Analytics solutions like ClearStory Data, Domo, Incorta, Looker, Microsoft Power BI, Qlik, Sisense, Tableau, and ThoughtSpot
- Data pipeline vendors such as Alooma, Attunity, Alteryx, Fivetran, and Matillion
- And data integration vendors including Informatica, MuleSoft, SnapLogic, Talend, and TIBCO (which also competes in the analytics space with its Spotfire portfolio)
If it seems like a lot of these companies have been in the spotlight, either from an acquisition or funding perspective, it is no coincidence. Recent examples include, but are not limited to:
- ThoughtSpot’s $145 million D Round in May 2018
- Sisense’s $80 million E round in September 2018
- Incorta’s $15 million B round extension in October 2018
- Fivetran’s $15 million A round in December 2018
- Looker’s $103 million E round in December 2018
- TIBCO’s acquisition of Orchestra Networks in December 2018
- Logi Analytics’ acquisition of Jinfonet in February 2019
- Google’s acquisition of Alooma in February 2019
- Qlik’s acquisition of Attunity in February 2019
- Informatica’s acquisition of AllSight in February 2019
- TIBCO’s acquisition of SnappyData in March 2019
- Alteryx’ acquisition of ClearStory Data in April 2019
- Matillion’s $35 million C round in June 2019
- Google’s intent to acquire Looker in June 2019
- Salesforce’s intent to acquire of Tableau in June 2019
- Logi Analytics’ acquisition of Zoomdata in June 2019
The success of these solutions reflects the increasing need for analyst, data, and platform flexibility in improving the contextual analytic value of data across clouds and sources. And there will be more activity in 2019 as a number of these companies are either private equity-owned or have taken significant venture capital funding and will need to exit soon to help fund future venture capital funds.
With the passing of Big Data, we move forward in tending to the health and care of the Era of Big Data’s progeny, including the Era of Multi-Cloud, Era of Machine Learning, and the Era of Real-Time and Ubiquitous Context.
The Era of Multi-Cloud speaks to the increasing need to support applications and platforms across multiple clouds based on the variety of applications in place and the increasing need for supporting continuous delivery and business continuity. The “there’s an app for that” mentality has led to a business environment that averages 1 SaaS app per employee in the enterprise, meaning that every large enterprise is supporting data and traffic for thousands of SaaS apps. And the evolution of containerization on the backend is leading to the increasing fragmentation and specialization of storage and workload environments to support on-demand and peak usage environments.
The Era of Machine Learning stands out in its focus on analytic models, algorithms, model training, deep learning, and the ethics of algorithmic and deep learning technologies. Machine Learning requires much of the same work needed to create clean data for analytics, but also requires additional mathematical, business, and ethical context to create lasting and long-term value.
The Era of Real-Time and Ubiquitous Context speaks to the increasing need for timely updates both from an analytic and engagement perspective. From an analytic perspective, it is no longer enough to simply update corporate analytics processing once a week or once a day. Employees now need near-real-time updates or risk making poor corporate decisions that are already outdated or obsolete as they are being made. The effective use of real-time analytics requires a breadth of business data to provide appropriate holistic context as well as for analytics being performed on-data and on-demand. Ubiquity also speaks to the emergence of interaction, including the Internet of Things in providing more edge observations of environmental and mechanical activity as well as the still-evolving world of Extended Reality, including both augmented and virtual reality, in providing in-site, in-time, in-action, and sensory context. To provide this level of interaction, data must be analyzed at the speed of interaction, which can be as short as 300-500 milliseconds to provide effective behavioral feedback.
With the Era of Big Data coming to an end, we now can focus less on the mechanics of collecting large volumes of data and more on the myriad challenges of processing, analyzing, and interacting with massive amounts of data in real-time. Here are a few concepts to keep in mind as we progress to new Eras driven by Big Data.
First, Hadoop still has its place in enterprise data. Amalgam Insights expects that MapR will eventually end up in a company known for managing IT software such as BMC, CA, or Micro Focus and believes that Cloudera has taken steps to move beyond Enterprise Hadoop to support the next Eras of data. But the pace of technology is unforgiving, and the question for Cloudera is whether it can move fast enough to transform. Cloudera has a digital transformation challenge in evolving its Enterprise Data Platform into a next-generation Insight and Machine Learning Platform. Companies used to be able to define the time frame for transformation in decades. Now, successful tech companies must be prepared to transform and possibly even cannibalize parts of themselves every decade just to stay alive, as we see from the likes of Amazon, Facebook, and Microsoft.
Second, the need for multi-cloud analytics and data visualization is greater than ever. Google and Salesforce just poured $18 billion into Looker and Tableau acquisitions, and those purchases were basically market-value acquisitions for companies of that scale and revenue growth. There will be many more billions spent on the challenges of providing analytics across a wide variety of data sources and to supporting the increasingly fragmented and varied storage, compute, and integration needs to be associated with multi-cloud. This means that enterprises will need to strategically figure out how much of this challenge will be managed by data integration, data modelling, analytics, and/or machine learning/data science teams as the processing and analysis of heterogeneous data becomes increasingly difficult, complex, and yet necessary to support strategic business imperatives and use data as a true strategic advantage.
Third, machine learning and data science are the next generation of analytic analysis and will require their own new data management efforts. The creation of testing data, synthetic data, and masked data at scale as well as the lineage, governance, parameter and hyperparameter definitions, and algorithmic assumptions require efforts beyond traditional Big Data assumptions. The most important consideration here is to use data that does not serve the business well due to small sample size, lack of data sources, poorly defined data, poorly contextualized data, or inaccurate algorithmic and classification assumptions. In other words, don’t use data that lies. Lying data leads to outcomes that are biased, non-compliant, inaccurate, and can lead to issues such as Nick Leeson’s destruction of Barings Bank in 1995 or Societe Generale’s $7 billion trading loss based on well-manipulated trades by Jerome Kerviel. AI is now the new potential “rogue trader” that needs to be appropriately governed, managed, and supported.
Fourth, real-time and ubiquitous context needs to be seen as a data challenge as well as a collaborative and technological challenge. We are entering a world where every object, process, and conversation can be tagged, captioned, or augmented with additional context and gigabytes of data may be processed in real-time to produce a simple two-word alert that may be as simple as “slow down” or “buy now.” We are seeing the concept of “digital twins” being created in the industrial world for objects by PTC, GE, and other product lifecycle and manufacturing companies as well as in the sales world as companies such as Gong, Tact, and Voicera digitally record, analyze, and augment analog conversations with additional context.
Conclusion
So, the era of Big Data has come to an end. But in the process, Big Data itself has become a core aspect of IT and brought into being a new set of Eras, each with its bright future. Companies that have invested in Big Data should see these investments as an important foundation for their future as real-time, augmented, and interactive engagement companies. As the Era of Big Data comes to an end, we are now ready to use the entirety of Big Data as a business asset, not just hype, to support job-based context, machine learning, and real-time interaction.
Bio: Hyoun Park is the CEO and Founder of Amalgam Insights, a firm focused on the technology, analytics, and financial tools needed to support emerging business models. Over the past 20+ years, Park has been at the forefront of trends such as Moneyball, social networking, Bring Your Own Device, the Subscription Economy, and video as the dominant use of Internet bandwidth. Park has been quoted in USA Today, the Los Angeles Times, and a wide variety of mainstream and technology press sources.
Related: