Introduction to Image Segmentation with K-Means clustering
Image segmentation is the classification of an image into different groups. Many kinds of research have been done in the area of image segmentation using clustering. In this article, we will explore using the K-Means clustering algorithm to read an image and cluster different regions of the image.

Image segmentation is an important step in image processing, and it seems everywhere if we want to analyze what’s inside the image. For example, if we seek to find if there is a chair or person inside an indoor image, we may need image segmentation to separate objects and analyze each object individually to check what it is. Image segmentation usually serves as the pre-processing before pattern recognition, feature extraction, and compression of the image.
Image segmentation is the classification of an image into different groups. Many kinds of research have been done in the area of image segmentation using clustering. There are different methods and one of the most popular methods is K-Means clustering algorithm.
So here in this article, we will explore a method to read an image and cluster different regions of the image. But before doing lets first talk about:
- Image Segmentation
- How Image segmentation works
- K-Means clustering ML Algorithm
- Merge K-Means clustering Algorithm with Image Segmentation.
- Canny Edge detection
Image Segmentation

Image segmentation is the process of partitioning a digital image into multiple distinct regions containing each pixel(sets of pixels, also known as superpixels) with similar attributes.
The goal of Image segmentation is to change the representation of an image into something that is more meaningful and easier to analyze.
Image segmentation is typically used to locate objects and boundaries(lines, curves, etc.) in images. More precisely, Image Segmentation is the process of assigning a label to every pixel in an image such that pixels with the same label share certain characteristics.
Of course, a common question arises:
Why does Image Segmentation even matter?
If we take an example of Autonomous Vehicles, they need sensory input devices like cameras, radar, and lasers to allow the car to perceive the world around it, creating a digital map. Autonomous driving is not even possible without object detection which itself involves image classification/segmentation.
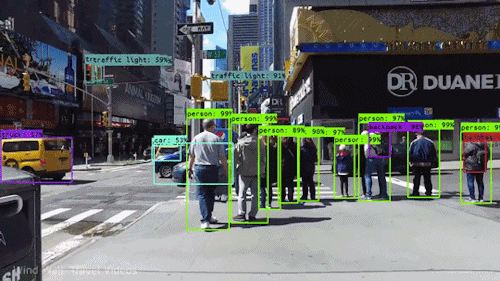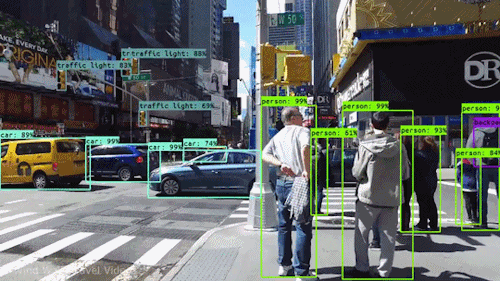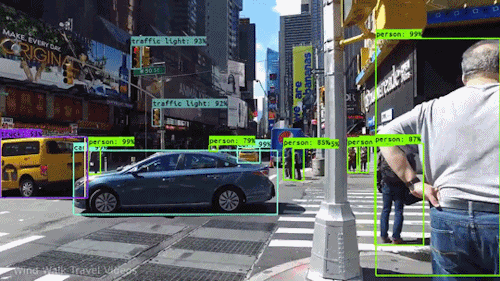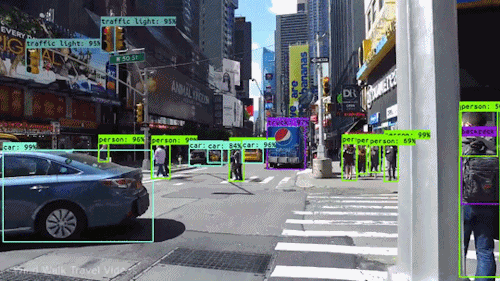
Other examples involve Healthcare Industry where if we talk about Cancer, even in today’s age of technological advancements, cancer can be fatal if we don’t identify it at an early stage. Detecting cancerous cell(s) as quickly as possible can potentially save millions of lives. The shape of the cancerous cells plays a vital role in determining the severity of cancer which can be identified using image classification algorithms.
Like this, there were several algorithms and techniques for image segmentation have been developed over the years using domain-specific knowledge to effectively solve segmentation problems in that specific application area which includes medical imaging, object detection, Iris recognition, video surveillance, machine vision and many more….
Let us plot an image in 3D space using python matplotlib library.
Below is the image that we’ll gonna plot in 3D space and we can clearly see 3 different colors which means 3 clusters/groups should be generated.

import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import cv2img = cv2.imread("/Users/nageshsinghchauhan/Documents/images10.jpg")
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
r, g, b = cv2.split(img)
r = r.flatten()
g = g.flatten()
b = b.flatten()#plotting
fig = plt.figure()
ax = Axes3D(fig)
ax.scatter(r, g, b)
plt.show()
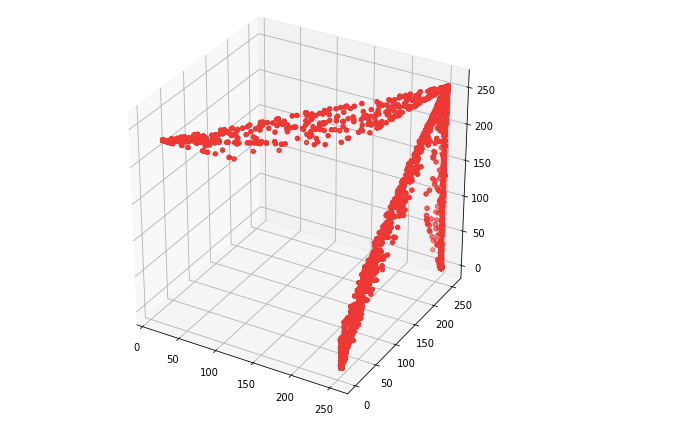
From the plot one can easily see that the data points are forming groups — some places in a graph are more dense, which we can think as different colors’ dominance on the image.
How Image Segmentation works
Image Segmentation involves converting an image into a collection of regions of pixels that are represented by a mask or a labeled image. By dividing an image into segments, you can process only the important segments of the image instead of processing the entire image.
A common technique is to look for abrupt discontinuities in pixel values, which typically indicate edges that define a region.
Another common approach is to detect similarities in the regions of an image. Some techniques that follow this approach are region growing, clustering, and thresholding.
A variety of other approaches to perform image segmentation have been developed over the years using domain-specific knowledge to effectively solve segmentation problems in specific application areas.
So let us start with one of the clustering-based approaches in Image Segmentation which is K-Means clustering.
K-Means clustering algorithm
Ok first What are Clustering algorithms in Machine Learning?
Clustering algorithms are unsupervised algorithms but are similar to Classification algorithms but the basis is different.
In Clustering, you don't know what you are looking for, and you are trying to identify some segments or clusters in your data. When you use clustering algorithms in your dataset, unexpected things can suddenly pop-up like structures, clusters, and groupings you would have never thought otherwise.
K-Means clustering algorithm is an unsupervised algorithm and it is used to segment the interest area from the background. It clusters, or partitions the given data into K-clusters or parts based on the K-centroids.
The algorithm is used when you have unlabeled data(i.e. data without defined categories or groups). The goal is to find certain groups based on some kind of similarity in the data with the number of groups represented by K.
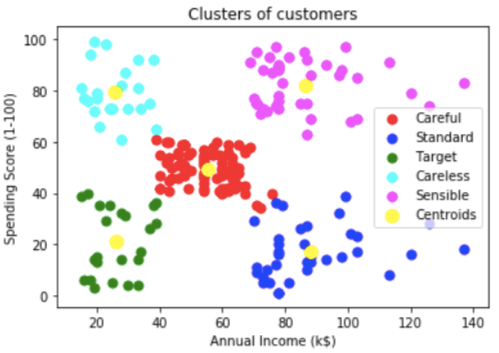
In the above figure, Customers of a shopping mall have been grouped into 5 clusters based on their income and spending score. Yellow dots represent the Centroid of each cluster.
The objective of K-Means clustering is to minimize the sum of squared distances between all points and the cluster center.
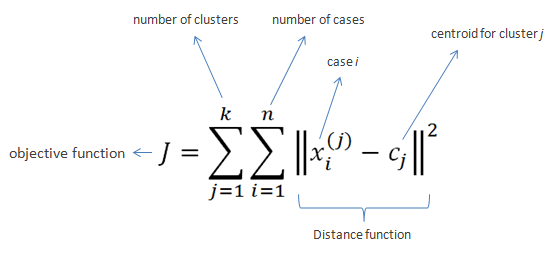
Steps in K-Means algorithm:
- Choose the number of clusters K.
- Select at random K points, the centroids(not necessarily from your dataset).
- Assign each data point to the closest centroid → that forms K clusters.
- Compute and place the new centroid of each cluster.
- Reassign each data point to the new closest centroid. If any reassignment . took place, go to step 4, otherwise, the model is ready.
How to choose the optimal value of K?
For a certain class of clustering algorithms (in particular K-Means, K-medoids, and expectation-maximization algorithm), there is a parameter commonly referred to as K that specifies the number of clusters to detect. Other algorithms such as DBSCAN and OPTICS algorithm do not require the specification of this parameter; Hierarchical Clustering avoids the problem altogether but that's beyond the scope of this article.
If we talk about K-Means then the correct choice of K is often ambiguous, with interpretations depending on the shape and scale of the distribution of points in a data set and the desired clustering resolution of the user. In addition, increasing K without penalty will always reduce the amount of error in the resulting clustering, to the extreme case of zero error if each data point is considered its own cluster (i.e., when K equals the number of data points, n). Intuitively then, the optimal choice of K will strike a balance between maximum compression of the data using a single cluster, and maximum accuracy by assigning each data point to its own cluster.
If an appropriate value of K is not apparent from prior knowledge of the properties of the data set, it must be chosen somehow. There are several categories of methods for making this decision and Elbow method is one such method.
Elbow method
The basic idea behind partitioning methods, such as K-Means clustering, is to define clusters such that the total intra-cluster variation or in other words, total within-cluster sum of square (WCSS) is minimized. The total WCSS measures the compactness of the clustering and we want it to be as small as possible.
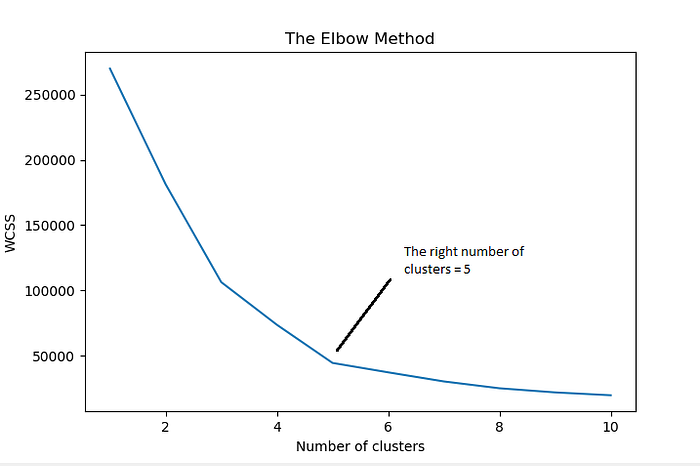
The Elbow method looks at the total WCSS as a function of the number of clusters: One should choose a number of clusters so that adding another cluster doesn’t improve much better the total WCSS.
Steps to choose the optimal number of clusters K:(Elbow Method)
- Compute K-Means clustering for different values of K by varying K from 1 to 10 clusters.
- For each K, calculate the total within-cluster sum of square (WCSS).
- Plot the curve of WCSS vs the number of clusters K.
- The location of a bend (knee) in the plot is generally considered as an indicator of the appropriate number of clusters.
There is a catch!!!
In spite of all the advantages K-Means have got but it fails sometimes due to the random choice of centroids which is called The Random Initialization Trap.
To solve this issue we have an initialization procedure for K-Means which is called K-Means++(Algorithm for choosing the initial values for K-Means clustering).
In K-Means++, We pick a point randomly and that's your first centroid, then we pick the next point based on the probability that depends upon the distance of the first point, the further apart the point is the more probable it is.
Then we have two centroids, repeat the process, the probability of each point is based on its distance to the closest centroid to that point. Now, this introduces an overhead in the initialization of the algorithm, but it reduces the probability of a bad initialization leading to bad clustering result.
Visual Representation of K-Means Clustering: Starting with 4 leftmost points.

Enough of theory lets implement what we have discussed in a real-world scenario.
In this section, we will explore a method to read an image and cluster different regions of the image using the K-Means clustering algorithm and OpenCV.
So basically we will perform Color clustering and Canny Edge detection.
Color Clustering:
Load all the required libraries:
import numpy as np import cv2 import matplotlib.pyplot as plt
Next step is to load the image in RGB color space
original_image = cv2.imread("/Users/nageshsinghchauhan/Desktop/image1.jpg")
Original Image:

We need to convert our image from RGB Colours Space to HSV to work ahead.
But the question is why ??
According to wikipedia the R, G, and B components of an object’s color in a digital image are all correlated with the amount of light hitting the object, and therefore with each other, image descriptions in terms of those components make object discrimination difficult. Descriptions in terms of hue/lightness/chroma or hue/lightness/saturation are often more relevant.
If you don't convert your image to HSV, your image will look something like this:

img=cv2.cvtColor(original_image,cv2.COLOR_BGR2RGB)
Next, converts the MxNx3 image into a Kx3 matrix where K=MxN and each row is now a vector in the 3-D space of RGB.
vectorized = img.reshape((-1,3))
We convert the unit8 values to float as it is a requirement of the k-means method of OpenCV.
vectorized = np.float32(vectorized)
We are going to cluster with k = 3 because if you look at the image above it has 3 colors, green-colored grass and forest, blue sea and the greenish-blue seashore.
Define criteria, number of clusters(K) and apply k-means()
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
OpenCV provides cv2.kmeans(samples, nclusters(K), criteria, attempts, flags) function for color clustering.
1. samples: It should be of np.float32 data type, and each feature should be put in a single column.
2. nclusters(K): Number of clusters required at the end
3. criteria: It is the iteration termination criteria. When this criterion is satisfied, the algorithm iteration stops. Actually, it should be a tuple of 3 parameters. They are `( type, max_iter, epsilon )`:
Type of termination criteria. It has 3 flags as below:
- cv.TERM_CRITERIA_EPS — stop the algorithm iteration if specified accuracy, epsilon, is reached.
- cv.TERM_CRITERIA_MAX_ITER — stop the algorithm after the specified number of iterations, max_iter.
- cv.TERM_CRITERIA_EPS + cv.TERM_CRITERIA_MAX_ITER — stop the iteration when any of the above condition is met.
4. attempts: Flag to specify the number of times the algorithm is executed using different initial labelings. The algorithm returns the labels that yield the best compactness. This compactness is returned as output.
5. flags: This flag is used to specify how initial centers are taken. Normally two flags are used for this: cv.KMEANS_PP_CENTERS and cv.KMEANS_RANDOM_CENTERS.
K = 3 attempts=10 ret,label,center=cv2.kmeans(vectorized,K,None,criteria,attempts,cv2.KMEANS_PP_CENTERS)
Now convert back into uint8.
center = np.uint8(center)
Next, we have to access the labels to regenerate the clustered image
res = center[label.flatten()] result_image = res.reshape((img.shape))
result_image is the result of the frame which has undergone k-means clustering.
Now let us visualize the output result with K=3
figure_size = 15
plt.figure(figsize=(figure_size,figure_size))
plt.subplot(1,2,1),plt.imshow(img)
plt.title('Original Image'), plt.xticks([]), plt.yticks([])
plt.subplot(1,2,2),plt.imshow(result_image)
plt.title('Segmented Image when K = %i' % K), plt.xticks([]), plt.yticks([])
plt.show()

So the algorithm has categorized our original image into three dominant colors.
Let's see what happens when we change the value of K=5:

Change the value of K=7:

As you can see with an increase in the value of K, the image becomes clearer because the K-means algorithm can classify more classes/cluster of colors.
We can try our code for different images:


Let's move to our next part which is Canny Edge detection.
Canny Edge detection: It is an image processing method used to detect edges in an image while suppressing noise.
The Canny Edge detection algorithm is composed of 5 steps:
Gradient calculation - Non-maximum suppression
- Double threshold
- Edge Tracking by Hysteresis
OpenCV provides cv2.Canny(image, threshold1,threshold2) function for edge detection.
The first argument is our input image. Second and third arguments are our min and max threshold respectively.
The function finds edges in the input image(8-bit input image) and marks them in the output map edges using the Canny algorithm. The smallest value between threshold1 and threshold2 is used for edge linking. The largest value is used to find initial segments of strong edges.
edges = cv2.Canny(img,150,200)
plt.figure(figsize=(figure_size,figure_size))
plt.subplot(1,2,1),plt.imshow(img)
plt.title('Original Image'), plt.xticks([]), plt.yticks([])
plt.subplot(1,2,2),plt.imshow(edges,cmap = 'gray')
plt.title('Edge Image'), plt.xticks([]), plt.yticks([])
plt.show()


Conclusion: What the future holds
Due to advancements in Image processing, Machine learning, AI and related technologies, there will be millions of robots in the world in a few decades time, transforming the way we live our daily lives. These advancements will involve spoken commands, anticipating the information requirements of governments, translating languages, recognizing and tracking people and things, diagnosing medical conditions, performing surgery, reprogramming defects in human DNA, driverless cars and many more applications, the count of real-life applications is endless.
Well, this comes to the end of this article. I hope you guys have enjoyed reading this article. Share your thoughts/comments/doubts in the comment section.
You can reach me out over LinkedIn for any query.
Thanks for reading !!!
Bio: Nagesh Singh Chauhan is a Data Science enthusiast. Interested in Big Data, Python, Machine Learning.
Original. Reposted with permission.
Related:
- Predict Age and Gender Using Convolutional Neural Network and OpenCV
- A Beginner’s Guide to Linear Regression in Python with Scikit-Learn
- From Data Pre-processing to Optimizing a Regression Model Performance