State of the Machine Learning and AI Industry
Enterprises are struggling to launch machine learning models that encapsulate the optimization of business processes. These are now the essential components of data-driven applications and AI services that can improve legacy rule-based business processes, increase productivity, and deliver results. In the current state of the industry, many companies are turning to off-the-shelf platforms to increase expectations for success in applying machine learning.
By Ed Fernandez, Board Director, Advisor, Early-stage & Startup VC.
From 2012 to 2018, blue-chip technology companies implemented custom-built ML platforms for internal use (i.e., Facebook’s FBLearning, Uber’s Michelangelo, Twitter’s Cortex, AirBnB’s BigHead), many of these platforms are primarily based on open-source packages and have been deeply tailored for the specific use cases of their respective companies.
Since then, the industry has seen a strong evolution of Enterprise-grade ML platform solutions, including those from incumbent vendors (e.g., Amazon Sagemaker, Microsoft Azure ML, Google Cloud ML, etc.) and the challengers in the space (e.g., DataRobot, H2O, BigML, Dataiku). Incumbent vendors follow an incremental strategy approach, with their ML services offering sitting on top of their existing cloud services as another application layer vs. the ML native approach taken by the challengers.
As adoption of ML increases, many Enterprises are quickly turning to off-the-shelf Data Science & Machine Learning Platforms to accelerate time to market, reduce costs of operationalization, and increase success ratio (number of ML models deployed and operationalized).
Given only a small fraction of current ML projects, PoCs (Proof of Concepts) and models reach production and meaningful ROI, ML platforms and AutoML (Automated Machine Learning) are arising as tools of choice to increase rapid prototyping of ML models and validation of use cases (ROI validation).
Conclusions:
- Despite significant and growing efforts, including corporate investment in ML projects and initiatives for the past few years, only a fraction of ML models reach production and deliver tangible results. Those which do have proven to be profitable or very profitable in many cases. At scale, Pareto’s principle applies with 20% of ML initiatives accounting for 80% of benefits, while many PoC projects are discarded or frozen for later improvement.
- Evidence suggests the market is approaching a turning point where more and more companies are inclined to buy (vs. build) with regards to ML platforms and tools, considering off-the-shelf vendor solutions or hybrid approaches vs. Open Source.
- AutoML, as well as APIs,are integral to ML platforms to increase rapid model prototyping, validation of ML use cases and deployment capabilities. The underlying rationale is to achieve better ROI (Return of Investment) by increasing both the number of ML candidate use cases and the success ratio (ML models deployed in production).
- Data (quantity and quality — ML ready), ML technical debt, MLOps vs. DevOps, and Enterprise ML processes and skills remain the main barriers to adoption. Despite that, traditional ML is quickly going beyond the hype cycle peak, and mainstream adoption in the Enterprise is expected to be only 2–3 years away.
- Future evolution: beyond deep learning, in the next decade, ML platforms are expected to gradually incorporate Knowledge Representation, Reasoning, Planning, and Optimization functionality, paving the path towards robust AI.
*Disclaimer: The term AI* (Artificial Intelligence) in the context of this post refers specifically to the ability to build machine learning-driven applications which ultimately automate and/or optimize business processes and SHOULD NOT BE CONFUSED with robust or strong Artificial Intelligence in the formal sense, ‘something not likely to happen for a least this decade and/or next’ (emphasis from the author).
Summary
Slides here — Video 45 min here
[1] Definitions & Context (this post)
Machine Learning Platforms Definitions •ML models & apps as first-class assets in the Enterprise•Workflow of an ML application•ML Algorithms overview •Architecture of an ML platform•Update on the Hype cycle for ML
[2] Adopting ML at Scale
The Problem with Machine Learning • Technical Debt in ML systems • How many models are too many models • The need for ML platforms
[3] The Market for ML Platforms
ML platform Market References • early adopters • Custom Build vs Buy: ROI & Technical Debt • ML Platforms • Vendor Landscape
[4] Custom Built ML Platforms
ML platform Market References — a closer look • Facebook — FBlearner • Uber — Michelangelo • AirBnB — BigHead • ML Platformization Going Mainstream
[5] From DevOps to MLOps
DevOps <> ModelOps • The ML platform-driven Organization • Leadership & Accountability
[6] Automated ML — AutoML
Scaling ML — Rapid Prototyping & AutoML • Vendor Comparison • AutoML: OptiML
[7] Future Evolution for ML Platforms
Beyond Deep Learning: Knowledge Representation, Reasoning, Planning & Optimization
1. Definitions & Context
There is not something as a unique ML platform, product, or service. The industry is very fragmented still, and the terms ‘ML Platform’, ‘Data Science Platform’, or ‘AI* platform’ are many times used interchangeably.
There are, though, commonalities emerging from the different products and services available in the market, in summary:

An ML platform offers advanced functionality essential for building ML solutions (primarily predictive and prescriptive models).
ML platforms support the incorporation of these solutions into business processes, surrounding infrastructure, products, and applications.
It supports variously skilled data scientists (and other stakeholders, i.e., ML Engineers, Data Analysts & Business Analysts/Experts) in multiple tasks across the data and analytics pipeline, including all of the following areas:
ML Workflow — % allocation of resources
- Data ingestion • Data preparation & Transformation • Data exploration & Visualization
- Feature engineering
- Model Selection, Evaluation & Testing (and AutoML)
- Deployment
- Monitoring & Explainability
- Maintenance & • Collaboration

ML platforms, as a combination of tools, systems, and services, enable experimentation and rapid prototyping, but their ROI materializes in the context of Enterprise operations and business processes, well beyond experimentation.
References:
Poul Petersen, Anatomy of an End To End ML Application https://www.slideshare.net/bigml/mlsev-anatomy-of-an-ml-application
ML Platform Research Report Papis.io
Enterprise Adoption Framework for ML & AI*
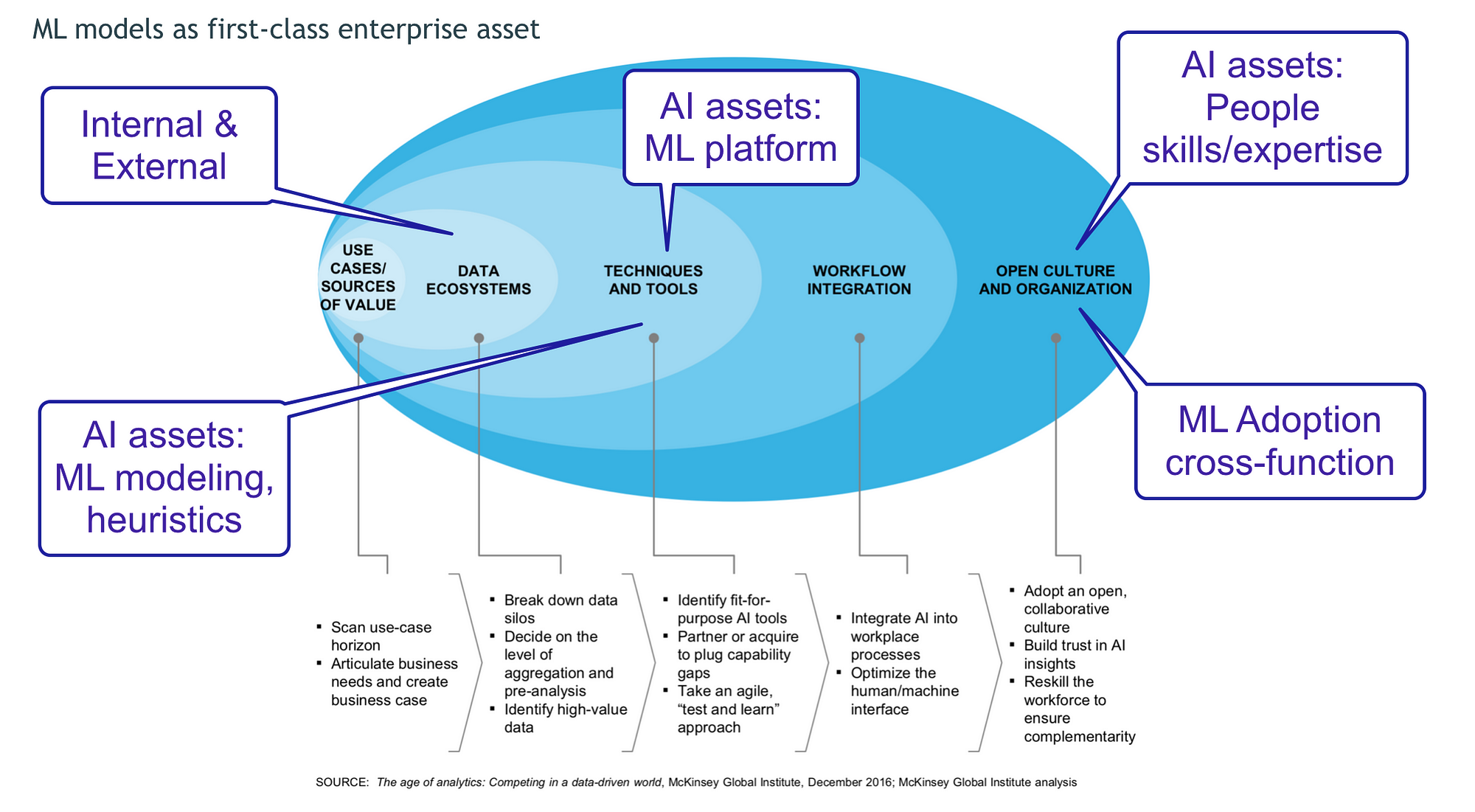
The ML platform & tools, as well as their products, ML models and data-driven applications, can be considered first-class enterprise assets, given their impact and ROI in the Enterprise.
McKinsey’s Global AI Survey provides a current overview of Enterprise self-reporting impact of AI* and its benefits.
However, it’s not only about technology. Processes, priorities, and people (leadership & accountability) also play an integral role in onboarding and successfully deploying ML-driven applications and services.
Not only software development is different when it comes to ML apps, deploying and integrating them with existing systems is proving to be a major challenge. DevOps can’t handle MLOps (Machine Learning Operations) adequately, considering the many differences in ML Software development (more details in section 5).
ML Algorithms
Managing ML algorithms as well as supporting their computational and data transformation needs is arguably the key task ML platforms solve both for Data Scientists and Domain Experts. The ability to quickly experiment and apply different algorithms to a given dataset is key to validate any use case (hypothesis validation).
Precisely AutoML (Automated Machine Learning) provides further automation for this process, creating many model candidates with different algorithms and evaluating their performance to suggest the best model options to a given prediction objective.

ML Algorithms — Supervised & Unsupervised (#MLSEV Courtesy of BigML Inc).
In practice, the vast majority of ML use cases in the enterprise (think Marketing, Finance, HR, Manufacturing, etc) do not require Deep Learning or Neural Network algorithms unless there are extraordinary performance requirements, or, in specific use cases where there is a need to deal with unstructured data (e.g., video, images or sound).
Almost 80–90% of the use cases leverage traditional ML algorithms such as Linear Regression, Logistic Regression, Random Forests, or Ensembles, which provide solid results and further explainability vs. the more opaque Neural Network methods.
Kaggle’s survey, which nearly comprises 20K respondents (data scientists a significant part), serves as a good proxy to monitor algorithm usage:
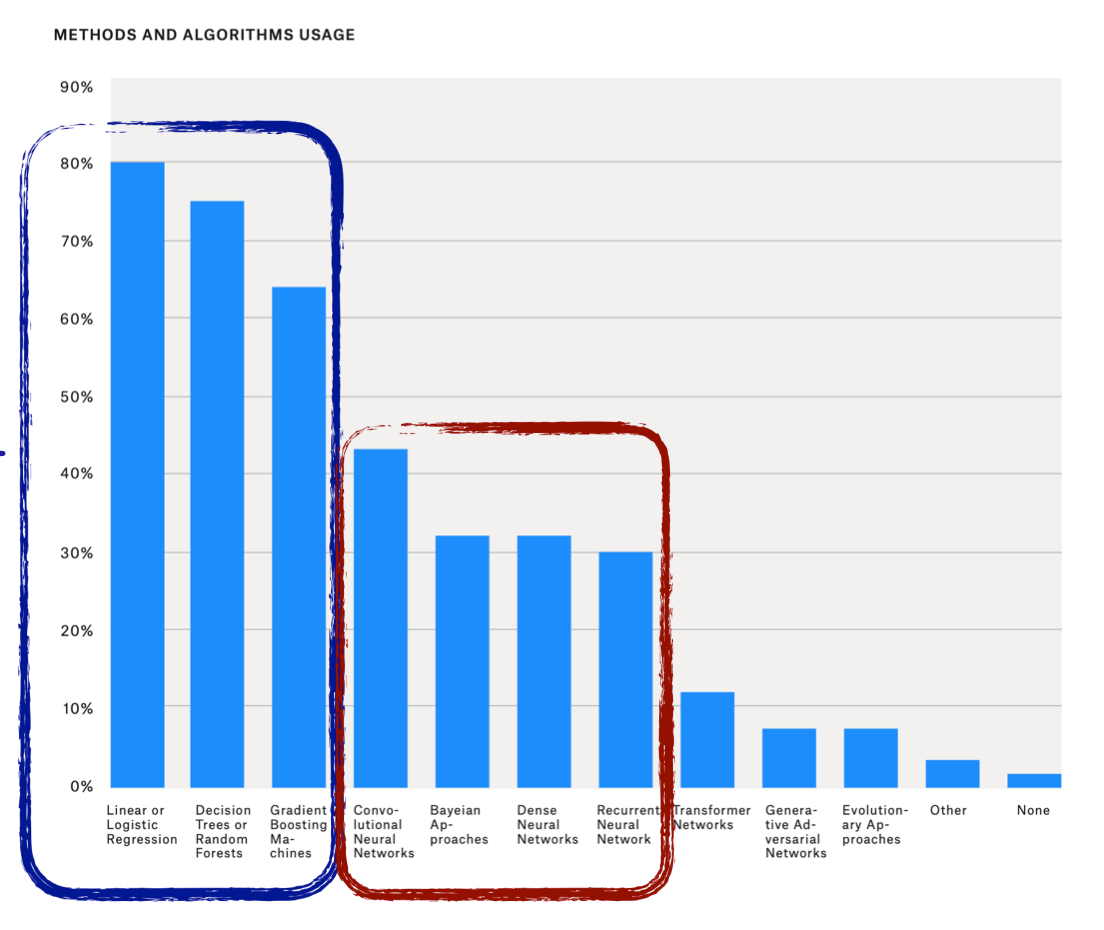
Blue box: Traditional ML Algorithms — Red Box: CNN, RNN, DNN & Bayesian — Source: Kaggle · The State of Data Science & ML 2019.
References:
Kaggle’s State of Data Science & ML Survey https://www.kaggle.com/kaggle-survey-2019
McKinsey — The Age of Analytics
ML Platforms Architecture
For custom-built ML platforms, open-source packages and technologies have been the preferred choice (e.g., Uber’s case: HDFS, Spark, Samza, Cassandra, MLLib, XGBoost, and TensorFlow), determining much of the underlying architecture.
Use cases to be solved and how much real-time vs. static data modeling was required have been the other factors shaping platform architectures. Uber services’ real-time needs (e.g., forecasting ride time) differ from AirBnB’s (e.g., recommender) and are very different from FICO’s (e.g., credit scoring) in terms of access, processing data requirements and expected time to prediction, hence having very distinct architectural needs.

Uber’s ML Platform — Michelangelo, source: Uber engineering https://eng.uber.com/michelangelo-machine-learning-platform/.
For example, in the case of Uber, models that are deployed online cannot access data stored in HDFS, making it difficult to retrieve key features from production online databases (e.g., query the UberEATS order service to compute the average meal prep time for a restaurant over a specific period of time).
Uber’s solution is to pre-compute and store those needed features in Cassandra, so latency requirements at prediction time could be met (source: Uber engineering — Michelangelo https://eng.uber.com/michelangelo-machine-learning-platform/).
Commercial ML Platforms, as opposed to custom-built open-source, are intended to generalize over a vast and diverse array of ML problems and use cases. Their architecture needs to support critical capabilities while allowing sufficient customization via abstraction layers:
- Automatic Deployment and Auto Scaling of Infrastructure (Cloud, Hybrid and On-Premise) — Distributed
- API— RESTful ML services —Programmatic API-fication and Integration
- Advanced Feature Engineering — DSL**
- Programmatic use of Algorithms and Models
- Customization with Programmatic Automation for ML Workflows — DSL
- Front-end: Visualizations and Interface
- Development Tools: Bindings (Python, R, Java, C), Libraries, CLI tools
** DSL Domain Specific Language

ML Platform architecture overview (Courtesy of BigML Inc).
APIs and programmatic automation with DSLs — Domain Specific Languages — warrant a spin-off post. AutoML, in particular, will be covered in section 7 of this post series.
DSLs provide the necessary level of abstraction on top of APIs and the computing infrastructure to deal with complexity, automation, and customization. Examples of DSL approaches are Uber’s DSL for Feature Selection and Transformation (Uber’s ML Platform — Michelangelo) and BigML’s DSL for ML workflow automation (WhizzML).
References:
Uber engineering — Michelangelo https://eng.uber.com/michelangelo-machine-learning-platform/
Arxiv: A survey on DSLs for Machine Learning and Big Data https://arxiv.org/pdf/1602.07637
PAPIS.io proceedings: The Past, Present, and Future of Machine Learning APIs http://proceedings.mlr.press/v50/cetinsoy15.pdf
WhizzML a DSL for ML workflow’s automation https://bigml.com/whizzml
Update on the Hype Cycle for Machine Learning
As Enterprises and practitioners go past the learning curve of applying ML in practice, both Machine Learning and Deep Learning as technologies went through and beyond the hype cycle peak, quickly navigating through the ‘Valley of Disillusionment’ (adjustment of expectations). Gartner’s latest Hype Cycle report reflects on this and predicts mainstream adoption to happen in the next 2–3 years.
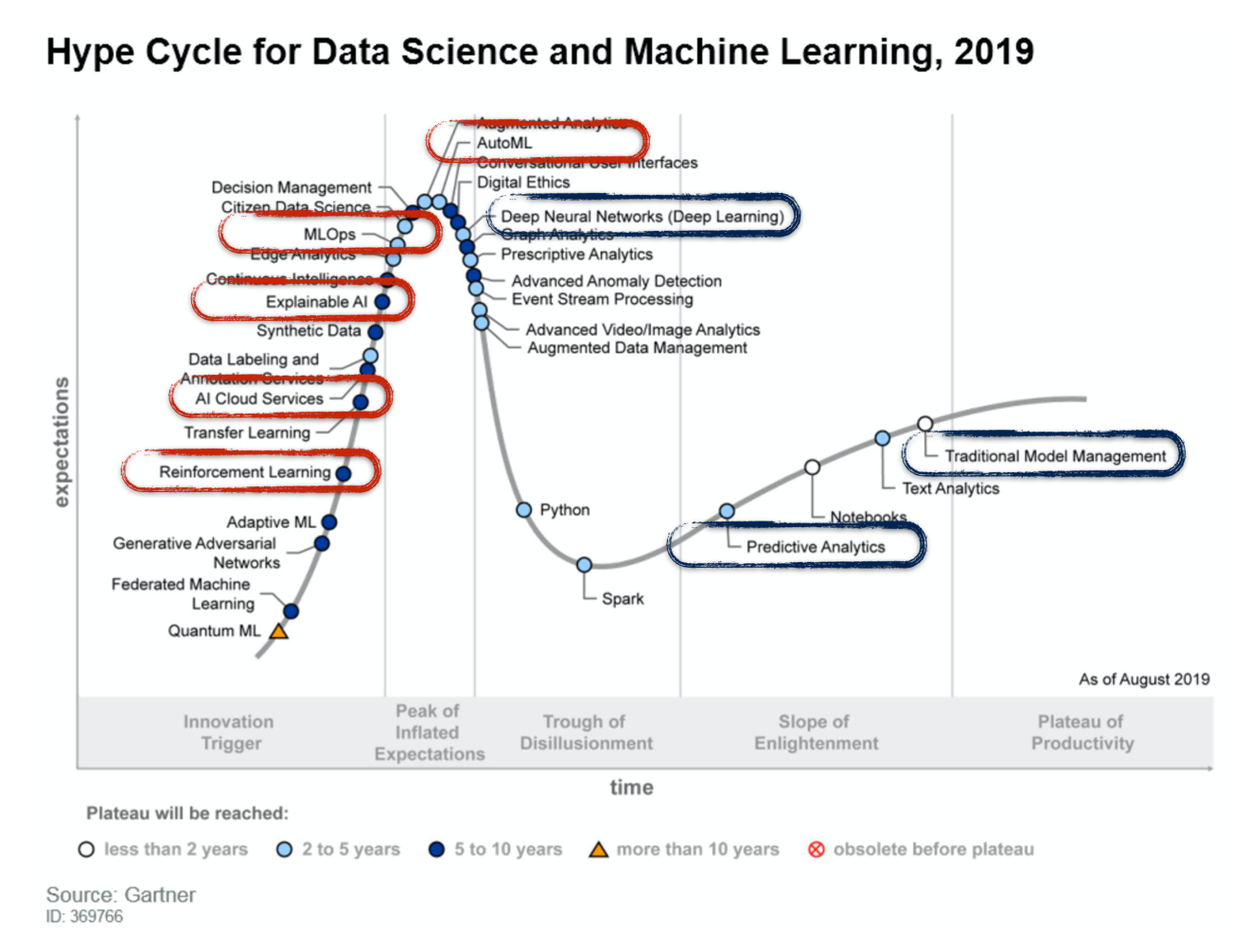
Source: Gartner Hype Cycle for DS and ML 2019.
Following suit, new ML platform’s functionalities, such as AutoML, MLOps, Explainable AI, or Reinforcement Learning, are currently entering the hype curve, quickly becoming overhyped. These new ML technologies, still immature, are not ready for mainstream or massive adoption yet.
Built vs. Buy
For some years now, the market has been divided between open-source and industry solutions.
From 2012 to 2018, blue chip technology companies implemented custom-built ML platforms for internal use (i.e., Facebook’s FBLearning, Uber’s Michelangelo, Twitter’s Cortex, AirBnB’s BigHead, more detailed analysis in Section 4 later on).
Many of these platforms are primarily based on open-source packages and have been deeply tailored for the specific use cases of those companies.
Despite the inherent free nature of open source packages (cost-benefit on acquisition) and the virtually unlimited capacity for customization, the problem with open source, however, comes with the associated hidden technical debt, and Glue Code in particular (more details in section 2, see Hidden Technical Debt in Machine Learning Systems. D. Sculley et al., Google, NIPS 2015).

Sculley et al., Google, NIPS 2015
It’s precisely the cost of configuring, orchestrating, and consolidating the use of different open source packages (Glue Code) what increases costs in the long run, making the build vs. buy business case more appealing toward industry solutions.
The industry has seen a strong evolution of Enterprise-grade ML platform solutions and MLaaS (Machine Learning as a Service or Cloud ML services), with the offering now divided between industry incumbents (e.g., Amazon Sagemaker, Microsoft Azure ML, Google Cloud ML, etc.) and challengers (DataRobot, H2O, BigML, Dataiku, etc.).
An important key driver for many Enterprises is time to market and competitiveness. As they struggle to scale and get enough ML models successfully to production with a traditional build R&D approach, many are quickly turning to off-the-shelf Data Science & Machine Learning Platforms to accelerate go to market, reduce costs of operationalization and increase success ratio (number of ML models deployed and operationalized).

References:
Hidden Technical Debt in Machine Learning Systems. D. Sculley et al., Google, NIPS 2015 https://papers.nips.cc/paper/5656-hidden-technical-debt-in-machine-learning-systems.pdf
Gartner’s Hype Cycle for AI https://www.gartner.com/smarterwithgartner/top-trends-on-the-gartner-hype-cycle-for-artificial-intelligence-2019/
Companion slides for this post are available at this link [presentation at the Machine Learning School #MLSEV — 26th March]
Original. Reposted with permission.
Bio: Ed Fernandez (@efernandez) is a Board Director, Advisor, Early-stage & Startup VC / PE - Entrepreneur, and Faculty @ Northeastern University based in Palo Alto.
Related: