Tuning Hyperparameters in Neural Networks
Learn essential techniques for tuning hyperparameters to enhance the performance of your neural networks.

Hyperparameters determine how well your neural network learns and processes information. Model parameters are learned during training. Unlike these parameters, hyperparameters must be set before the training process starts. In this article, we will describe the techniques for optimizing the hyperparameters in the models.
Hyperparameters In Neural Networks
Learning Rate
The learning rate tells the model how much to change based on its errors. If the learning rate is high, the model learns quickly but might make mistakes. If the learning rate is low, the model learns slowly but more carefully. This leads to less errors and better accuracy.
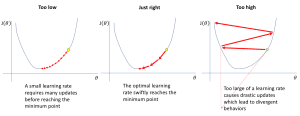 Source: https://www.jeremyjordan.me/nn-learning-rate/
Source: https://www.jeremyjordan.me/nn-learning-rate/There are ways of adjusting the learning rate to achieve the best results possible. This involves adjusting the learning rate at predefined intervals during training. Furthermore, optimizers like the Adam enables a self-tuning of the learning rate according to the execution of the training.
Batch Size
Batch size is the number of training samples a model undergoes at a given time. A large batch size basically means that the model goes through more samples before the parameter update. It can lead to more stable learning but requires more memory. A smaller batch size on the other hand updates the model more frequently. In this case, learning can be faster but it has more variation in each update.
The value of the batch size affects memory and processing time for learning.
Number of Epochs
Epochs refers to the number of times a model goes through the entire dataset during training. An epoch includes several cycles where all the data batches are shown to the model, it learns from it, and optimizes its parameters. More epochs are better in learning the model but if not well observed they can result in overfitting. Deciding the correct number of epochs is necessary to achieve a good accuracy. Techniques like early stopping are commonly used to find this balance.
Activation Function
Activation functions decide whether a neuron should be activated or not. This leads to non-linearity in the model. This non-linearity is beneficial especially while trying to model complex interactions in the data.
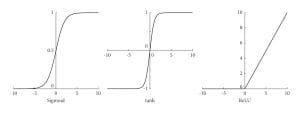 Source: https://www.researchgate.net/publication/354971308/figure/fig1/AS:1080246367457377@1634562212739/Curves-of-the-Sigmoid-Tanh-and-ReLu-activation-functions.jpg
Source: https://www.researchgate.net/publication/354971308/figure/fig1/AS:1080246367457377@1634562212739/Curves-of-the-Sigmoid-Tanh-and-ReLu-activation-functions.jpgCommon activation functions include ReLU, Sigmoid and Tanh. ReLU makes the training of neural networks faster since it permits only the positive activations in neurons. Sigmoid is used for assigning probabilities since it outputs a value between 0 and 1. Tanh is advantageous especially when one does not want to use the whole scale which ranges from 0 to ± infinity. The selection of a right activation function requires careful consideration since it dictates whether the network shall be able to make a good prediction or not.
Dropout
Dropout is a technique which is used to avoid overfitting of the model. It randomly deactivates or "drops out" some neurons by setting their outputs to zero during each training iteration. This process prevents neurons from relying too heavily on specific inputs, features, or other neurons. By discarding the result of specific neurons, dropout helps the network to focus on essential features in the process of training. Dropout is mostly implemented during training while it is disabled in the inference phase.
Hyperparameter Tuning Techniques
Manual Search
This method involves trial and error of values for parameters that determine how the learning process of a machine learning model is done. These settings are adjusted one at a time to observe how it influences the model’s performance. Let's try to change the settings manually to get better accuracy.
learning_rate = 0.01
batch_size = 64
num_layers = 4
model = Model(learning_rate=learning_rate, batch_size=batch_size, num_layers=num_layers)
model.fit(X_train, y_train)
Manual search is simple because you do not require any complicated algorithms to manually set parameters for testing. However, it has several disadvantages as compared to other methods. It can take a lot of time and it may not find the very best settings efficiently than the automated methods
Grid Search
Grid search tests many different combinations of hyperparameters to find the best ones. It trains the model on part of the data. After that, it checks how well it does with another part. Let's implement grid search using GridSearchCV to find the best model .
from sklearn.model_selection import GridSearchCV
param_grid = {
'learning_rate': [0.001, 0.01, 0.1],
'batch_size': [32, 64, 128],
'num_layers': [2, 4, 8]
}
grid_search = GridSearchCV(model, param_grid, cv=5)
grid_search.fit(X_train, y_train)
Grid search is much faster than manual search. However, it is computationally expensive because it takes time to check every possible combination.
Random Search
This technique randomly selects combinations of hyperparameters to find the most efficient model. For each random combination, it trains the model and checks how well it performs. In this way, it can quickly arrive at good settings that cause the model to perform better. We can implement random search using RandomizedSearchCV to achieve the best model on the training data.
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import uniform, randint
param_dist = {
'learning_rate': uniform(0.001, 0.1),
'batch_size': randint(32, 129),
'num_layers': randint(2, 9)
}
random_search = RandomizedSearchCV(model, param_distributions=param_dist, n_iter=10, cv=5)
random_search.fit(X_train, y_train)
Random search is normally better than the grid search since only a few number of hyperparameters are checked to get suitable hyperparameters settings. Nonetheless, it might not search the correct combination of hyperparameters particularly when the working hyperparameters space is large.
Wrapping Up
We've covered some of the basic hyperparameter tuning techniques. Advanced techniques include Bayesian Optimization, Genetic Algorithms and Hyperband.
Jayita Gulati is a machine learning enthusiast and technical writer driven by her passion for building machine learning models. She holds a Master's degree in Computer Science from the University of Liverpool.