10 Useful Machine Learning Practices For Python Developers
While you may be a data scientist, you are still a developer at the core. This means your code should be skillful. Follow these 10 tips to make sure you quickly deliver bug-free machine learning solutions.
By Pratik Bhavsar, Remote NLP engineer.
Sometimes as a data scientist, we forget what we are paid for. We are primarily developers, then researchers, and then maybe mathematicians. Our first responsibility is to quickly develop solutions that are bug-free.
Just because we can make models doesn't mean we are gods. It doesn't give us the freedom to write crap code.
Since my start, I have made tremendous mistakes and thought of sharing what I see to be the most common skills for ML engineering. In my opinion, it's also the most lacking skill in the industry right now.
I call them software-illiterate data scientists because a lot of them are non-CS Coursera baptized engineers. And, I myself have been that. ????
If it came to hiring between a great data scientist and a great ML engineer, I would hire the latter.
Let's get started.
1. Learn to write abstract classes
Once you start writing abstract classes, you will know how much clarity it can bring to your codebase. They enforce the same methods and method names. If many people are working on the same project, everyone starts making different methods. This can create unproductive chaos.
2. Fix your seed at the top
Reproducibility of experiments is a very important thing, and seed is our enemy. Catch hold of it. Otherwise, it leads to different splitting of train/test data and different initialisation of weights in the neural network. This leads to inconsistent results.
3. Get started with a few rows
If your data is too big and you are working in the later part of the code, like cleaning data or modeling, use nrows to avoid loading the huge data every time. Use this when you want to only test code and not actually run the whole thing.
This is very applicable when your local PC config is not enough to work with the datasize, but you like doing development on local on Jupyter/VS code/Atom.
df_train = pd.read_csv(‘train.csv’, nrows=1000)
4. Anticipate failures (the sign of a mature developer)
Always check for NA in the data because these will cause you problems later. Even if your current data doesn't have any, it doesn't mean it will not happen in the future retraining loops. So keep checks anyway. ????
print(len(df))
df.isna().sum()
df.dropna()
print(len(df))
5. Show the progress of processing
When you are working with big data, it definitely feels good to know how much time is it going to take and where we are in the whole processing.
Option 1 — tqdm
Option 2 — fastprogress
6. Pandas can be slow
If you have worked with pandas, you know how slow it can get some times — especially groupby. Rather than breaking our heads to find 'great' solutions for speedup, just use modin by changing one line of code.
import modin.pandas as pd
7. Time the functions
Not all functions are created equal.
Even if the whole code works, it doesn't mean you wrote great code. Some soft-bugs can actually make your code slower, and it's necessary to find them. Use this decorator to log the time of functions.
8. Don't burn money on cloud
Nobody likes an engineer who wastes cloud resources.
Some of our experiments can run for hours. It's difficult to keep track of it and shut down the cloud instance when it's done. I have made mistakes myself and have also seen people leaving instances on for days.
This happens when we work on Fridays and leave something running and realise it on Monday. ????
Just call this function at the end of execution, and your ass will never be on fire again!
But wrap the main code in try and this method again in except as well — so that if an error happens, the server is not left running. Yes, I have dealt with these cases too. ????
Let's be a bit responsible and not generate CO2. ????
9. Create and save reports
After a particular point in modeling, all great insights come only from error and metric analysis. Make sure to create and save well-formatted reports for yourself and your manager.
Anyway, management loves reports, right? ????
10. Write great APIs
All that ends bad is bad.
You can do great data cleaning and modeling, but still, you can create huge chaos at the end. My experience with people tells me many are not clear about how to write good APIs, documentation, and server setup.
Below is a good methodology for a classical ML and DL deployment under not too high load — like 1000/min.
Meet the combo — Fastapi + uvicorn
- Fastest— Write the API in fastapi because its the fastest for I/O bound as per this, and the reason is explained here.
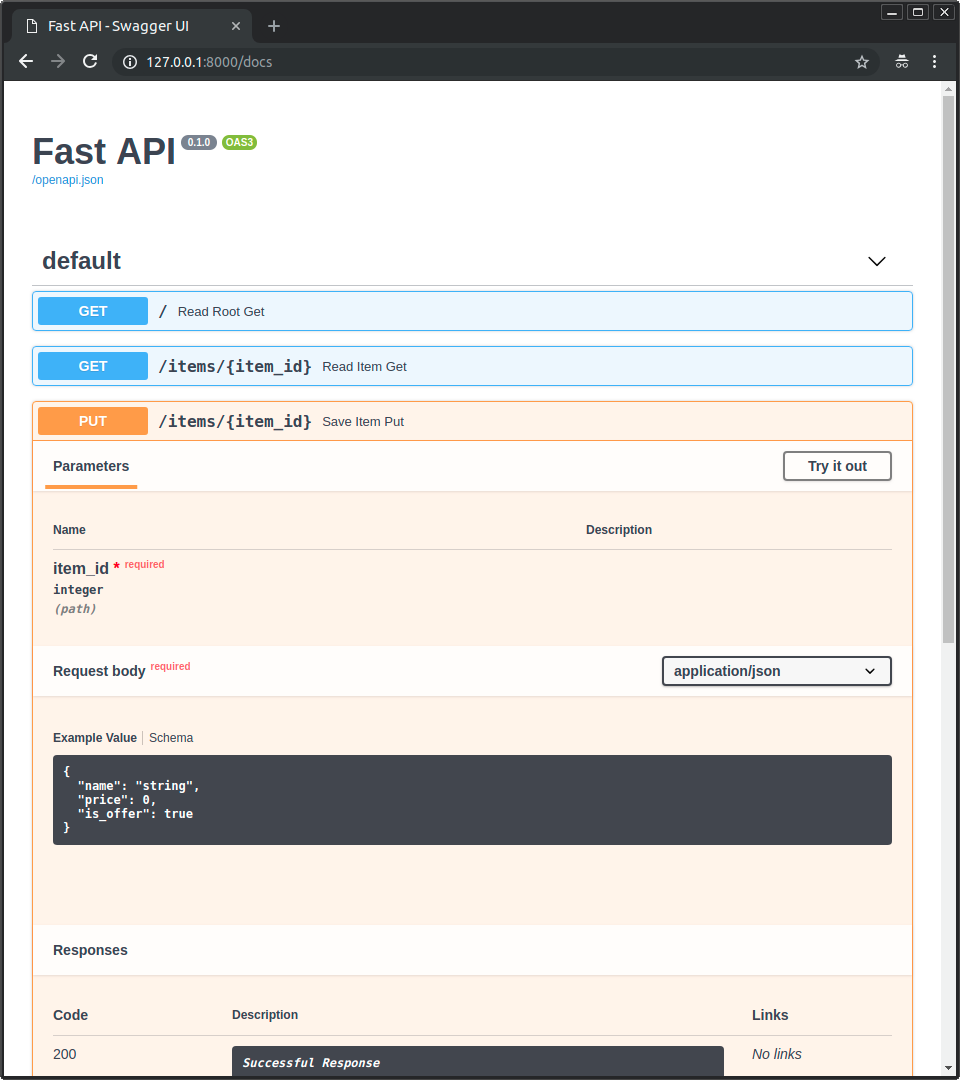
- Documentation— Writing API in fastapi gives us free documentation and test endpoints at http:url/docs → autogenerated and updated by fastapi as we change the code
- Workers— Deploy the API using uvicorn
Run these commands to deploy using 4 workers. Optimise the number of workers by load testing.
pip install fastapi uvicorn
uvicorn main:app --workers 4 --host 0.0.0.0 --port 8000
Original. Reposted with permission.
Related: