LinkedIn Open Sources a Small Component to Simplify the TensorFlow-Spark Interoperability
Spark-TFRecord enables the processing of TensorFlow’s TFRecord structures in Apache Spark.

Interoperating TensorFlow and Apache Spark is a common challenge in real world machine learning scenarios. TensorFlow is, arguably, the most popular deep learning framework in the market while Apache Spark remains one of the most widely adopted data computations platforms with a large install based across large enterprises and startups. It is only natural that companies will try to combine the two. While there are frameworks that adapt TensorFlow to Spark, the root of the interoperability challenge is often rooted at the data level. TFRecord, is the native data structure in TensorFlow, is not fully supported in Apache Spark. Recently, engineers from LinkedIn open sourced Spark-TFRecord, a new native data source from Spark based on the TensorFlow TFRecord.
The fact that LinkedIn decided to address this problem is not surprising. The internet giant has long been a wide adopter of Spark technologies and has been an active contributor to the TensorFlow and machine learning open source communities. Internally, LinkedIn’s engineering teams were regularly trying to implement transformation between TensorFlow’s native TFRecord format and Spark’s internal formats such as Avro or Parquet. The goal of the Spark-TFRecord project was to provide the native functionalities of the TFRecord structure in Spark pipelines.
Prior Attempts
Spark-TFRecord is not the first project that attempts to solve the data interoperability challenges between Spark and TensorFlow. The most popular project in that reel is the Spark-Tensorflow-Connector promoted by Spark’s creator Databricks. We have used the Spark-TensorFlow-Connector plenty of times with various degrees of success. Architecturally, the connector is an adaptation of the TFRecord format into Spark SQL DataFrames. Knowing that, it shouldn’t be surprising that the Spark-TensorFlow-Connector works very effectively in relational data access scenarios but remains very limited in other use cases.
If you think about it, an important part of a TensorFlow workflow is related to disk I/O operations rather than database access. In those scenarios, developers end up writing considerable amounts of code when using the Spark-TensorFlow-Connector. Additionally, the current version of the Spark-TensorFlow-Connector still lacks important functions such as the PartitionBy which are regularly used in TensorFlow computations. Finally, the connector is more like a bridge to process TensorFlow records in Spark SQL Data Frames rather than a native file format.
Factoring in those limitations, the LinkedIn engineering team decided to address the Spark-TensorFlow interoperability challenge from a slightly different perspective.
Spark-TFRecord
Spark-TFRecord is a native TensorFlow TFRecord for Apache Spark. Specifically, Spark-TFRecord provides the routines for reading and writing TFREcord data from/to Apache Spark. Instead of building a connector to process TFRecord structures, Spark-TFRecord is built as a native Spark dataset just like Avro, JSON or Parquet. That means that all Spark’s DataSet and DataFrame I/O routines are automatically available within a Spark-TFRecord.
An obvious question worth exploring is why build a new data structure instead of simply versioning the open source Spark-TensorFlow connector? Well, it seems that adapting the connector to disk I/O operations require a fundamental redesign.
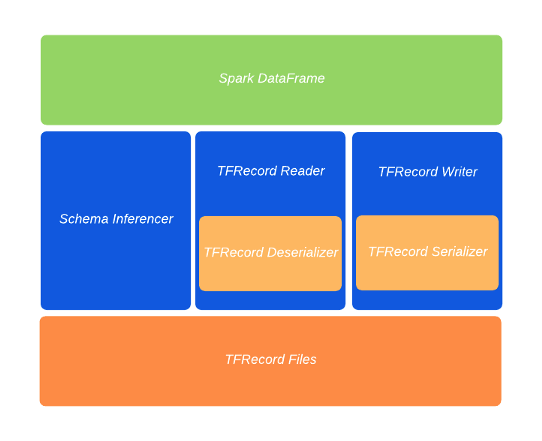
Instead of following that route, the LinkedIn engineering team decided to implement a new Spark FileFormat interface which is fundamentally designed to support disk I/O operations. The new interface would adapt the TFRecord native operations to any Spark DataFrames. Architecturally, Spark-TFRecord is composed of a series of basic building blocks that abstract reading/writing and serialization/deserialization routines:
-
Schema Inferencer: This is the component that is closest to the Spark-TensorFlow-Connector. This interface maps TFRecords representations into native Spark data types.
TFRecord Reader: This component reads TFRecord structures and passes them to the deserializer.
TFRecord Writer: This component receives a TFRecord structure from the serializer and writes it to disk.
TFRecord Serializer: This component converts Spark InternalRow to TFRecord structures.
TFRecord Deserializer: This component converts TFRecords to Spark InternalRow structures.
Using LinkedIn’s Spark-TFRecord is not different from other Spark native datasets. A developer simply needs to include the spark-tfrecord jar library and use the traditional DataFrame API to read and write TFRecords as illustrated in the following code:
import org.apache.commons.io.FileUtils
import org.apache.spark.sql.{ DataFrame, Row }
import org.apache.spark.sql.catalyst.expressions.GenericRow
import org.apache.spark.sql.types._
val path = "test-output.tfrecord"
val testRows: Array[Row] = Array(
new GenericRow(Array[Any](11, 1, 23L, 10.0F, 14.0, List(1.0, 2.0), "r1")),
new GenericRow(Array[Any](21, 2, 24L, 12.0F, 15.0, List(2.0, 2.0), "r2")))
val schema = StructType(List(StructField("id", IntegerType),
StructField("IntegerCol", IntegerType),
StructField("LongCol", LongType),
StructField("FloatCol", FloatType),
StructField("DoubleCol", DoubleType),
StructField("VectorCol", ArrayType(DoubleType, true)),
StructField("StringCol", StringType)))
val rdd = spark.sparkContext.parallelize(testRows)
//Save DataFrame as TFRecords
val df: DataFrame = spark.createDataFrame(rdd, schema)
df.write.format("tfrecord").option("recordType", "Example").save(path)
//Read TFRecords into DataFrame.
//The DataFrame schema is inferred from the TFRecords if no custom schema is provided.
val importedDf1: DataFrame = spark.read.format("tfrecord").option("recordType", "Example").load(path)
importedDf1.show()
//Read TFRecords into DataFrame using custom schema
val importedDf2: DataFrame = spark.read.format("tfrecord").schema(schema).load(path)
importedDf2.show()The interoperability between Spark and deep learning frameworks like TensorFlow is likely to continue being a challenging area for most organizations. However, projects like LinkedIn’s Spark-TFRecord that have been tested at a massive scale definitely help to simplify the bridge between these two technologies that are essential to so many modern machine learning architectures.
Original. Reposted with permission.
Related:
- OpenAI Open Sources Microscope and the Lucid Library to Visualize Neurons in Deep Neural Networks
- Google Open Sources SimCLR, A Framework for Self-Supervised and Semi-Supervised Image Training
- The Architecture Used at LinkedIn to Improve Feature Management in Machine Learning Models