The Architecture Used at LinkedIn to Improve Feature Management in Machine Learning Models
The new typed feature schema streamlined the reusability of features across thousands of machine learning models.

LinkedIn is one of the companies at the forefront of machine learning innovation. Regularly faced with applying machine learning at massive levels of scalability, the LinkedIn engineering team has become a regular contributor to open source machine learning stacks as well as content that details some of the best practices learned in their machine learning journey. At the heart of the LinkedIn experience, we have the content feed that recommends new connections, jobs or candidates for a position. That content feed is powered by many recommendation systems based on machine learning models that need constant experimentation, versioning and evaluation. Those goals depend on a very robust feature engineering process. Recently, LinkedIn unveiled some details about their approach to feature engineering to enable rapid experimentation which contains some very unique innovations.
The scale of the machine learning problems that an organization like LinkedIn deals with results incomprehensible for data scientists. Building an maintaining a single, effective machine learning models is hard enough so imagine coordinating the execution of thousands of machine learning programs to achieve a cohesive experience. Feature engineering is one of the key element to allow rapid experimentation of machine learning programs. For instance, let’s assume that a LinkedIn member is described using 100 features and that the content feed rendered in the member’s homepage is powered by 50+ machine learning models. Assuming that every second, there are tens of thousands of people loading their LinkedIn pages, the number of feature computations required is something like the following:
(number of features) X (number of concurrent LinkedIn members) X (number of machine learning models) > 100 X 10000 X 50 > 50,000,000 per second
That number is just unfathomable to most organizations starting their machine learning journey. Such a scale requires representing features in a flexible and easy to interpret manner that can be reused across different infrastructures such as Spark, Hadoop, database systems and others. The latest version of LinkedIn’s feature architecture introduces the concept of typed features to represent features in an expressive and reusable format. This idea arose from challenges with the previous version of LinkedIn’s machine learning inference and training architecture.
The First Version
Like any large, agile organization, LinkedIn’s machine learning architecture evolved across different disparate infrastructures. For instance, the following figure represents the feature architecture for LinkedIn’s online and offline inference infrastructures based on Spark and Hadoop respectively.
The online feature architecture was optimized for universality representing strings to store categoricals and a single value type of floats. This design incurred an efficiency cost in representing integer counts, categoricals with known domains, and interacted features. On the other hand, the HDFS feature snapshot was optimized for simple offline joins, was specific per feature rather than uniform, and did not take into account online systems. The constant translation between the different types of feature representations introduced regular friction in the possible experimentation with features and challenges replicating updates across the different systems.

Typed Features
To address some of the limitations of the initial feature architecture, LinkedIn introduced a new way of storing features throughout our systems in a single format of tensors with feature-specific metadata. Tensors are a standard computation unit used across most of the popular deep learning frameworks such as TensorFlow or PyTorch. From that perspective, the use of tensors facilitate the implementation of complex linear algebra operations without sacrificing the underlying format. Most data scientists are familiar with the tensor structure so the new representation results relatively easy to incorporate in machine learning programs.
One thing that is important to notice is that the new LinkedIn structure is designed specifically for features and not relying on a generic data type format like Avro. By building on top of tensors, features are always serialized in the same generic schema. This allows for flexibility in quickly adding new features to systems without changing any APIs. This is achievable thanks to the metadata, which maps what previously would have been space-inefficient strings or custom-defined schemas to integers.
The following code illustrates the definition of a feature using LinkedIn’s new typed feature schema. Concretely, defines a feature “historicalActionsInFeed” that will list historical actions a member has taken on the feed. The feature metadata information is defined inside the flagship namespace, with names and versions. This allows for any system to look up the feature in the metadata system using the urn urn:li:(flagship,historicalActionsInFeed,1,0). From this feature definition, there are two important dimensions, which include a categorical listing of different action types in “feedActions” as well as a discrete count representing different time windows in a member’s history.
// Feature definition:
historicalActionsInFeed: {
doc: "Historical interactions on feed for members. go/linkToDocumentation"
version: "1.0"
dims: [
feedActions-1-0,
numberOfDays-1-0
]
valType: INT
availability: ONLINE
}
//////////
// Dimension definitions:
feedActions: {
doc: "The actions a user can take on main feed"
version: "1.0"
type: categorical : {
idMappingFile: "feedActions.csv"
}
}
numberOfDays: {
doc: "Count of days for historical windowing"
type: discrete
}
//////////
// Categorical definition (feedActions.csv):
0, OUT_OF_VOCAB
1, Comment
2, Click
3, Share
The Second Version
Having a new feature and metadata representation model in place makes distribution the new challenge. How to effectively distribute new features across thousands of machine learning models and dozens of infrastructure components. The answer was simpler than expected. LinkedIn created a single, textual source of truth for each metadata type that is stored under source control and published as an artifact library. How clever! Any machine learning system can pull the desired metadata constructs by simply declaring a dependency. Additionally, the LinkedIn typed feature solution includes a metadata resolution library that operates against different feature stores.
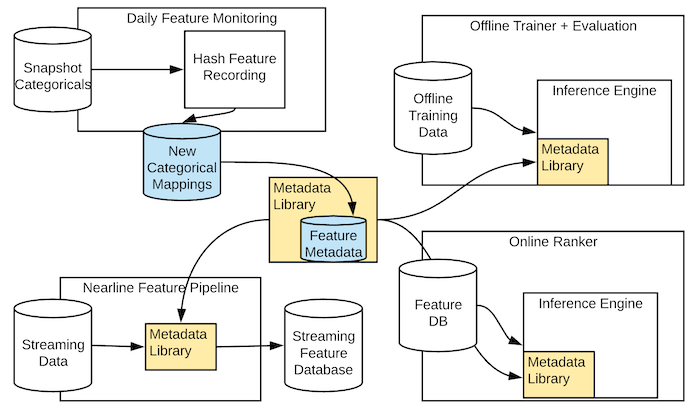
LinkedIn new type feature architecture includes some interesting ideas that can streamline feature engineering for large scale machine learning systems. By using tensors are the underlying computation unit, Linked has created a feature representation that is easily pluggable into any machine learning frameworks. Additionally, the use of metadata can enrich the representation of the feature. Early reports indicate that the new typed feature architecture has increased the performance of LinkedIn’s inference systems for over 20% which is a remarkable number at that scale. It would be interesting to see some of these ideas open sourced in the near future.
Original. Reposted with permission.
Related:
- 4 Tips for Advanced Feature Engineering and Preprocessing
- Microsoft Research Unveils Three Efforts to Advance Deep Generative Models
- The Hitchhiker’s Guide to Feature Extraction