Microsoft Research Unveils Three Efforts to Advance Deep Generative Models
Optimus, FQ-GAN and Prevalent bring new ideas to apply generative models at large scale.
Generative models have been an important component of machine learning for the last few decades. With the emergence of the deep learning, generative models started being combined with deep neural networks creating the field of deep generative models(DGMs). DGMs hold a lot of promise for the deep learning field as they have the ability of synthesizing data from observation. This feature can result key to improve the training of large scale models without requiring large amounts of data. Recently, Microsoft Research unveiled three new projects looking to advance research in DGMs.
One of the biggest questions surrounding DGMs is whether they can be applied with large-scale datasets. In recent years, we have seen plenty of examples of DGMs applied in a relatively small scale. However, the deep learning field is gravitating towards a “bigger is better” philosophy when comes to data and we are regularly seeing new models being trained in unfathomably big datasets. The idea of DGMs that can operate at that scale is one of the most active areas of research in the space and the focus of the Microsoft Research projects.
Types of DGMs
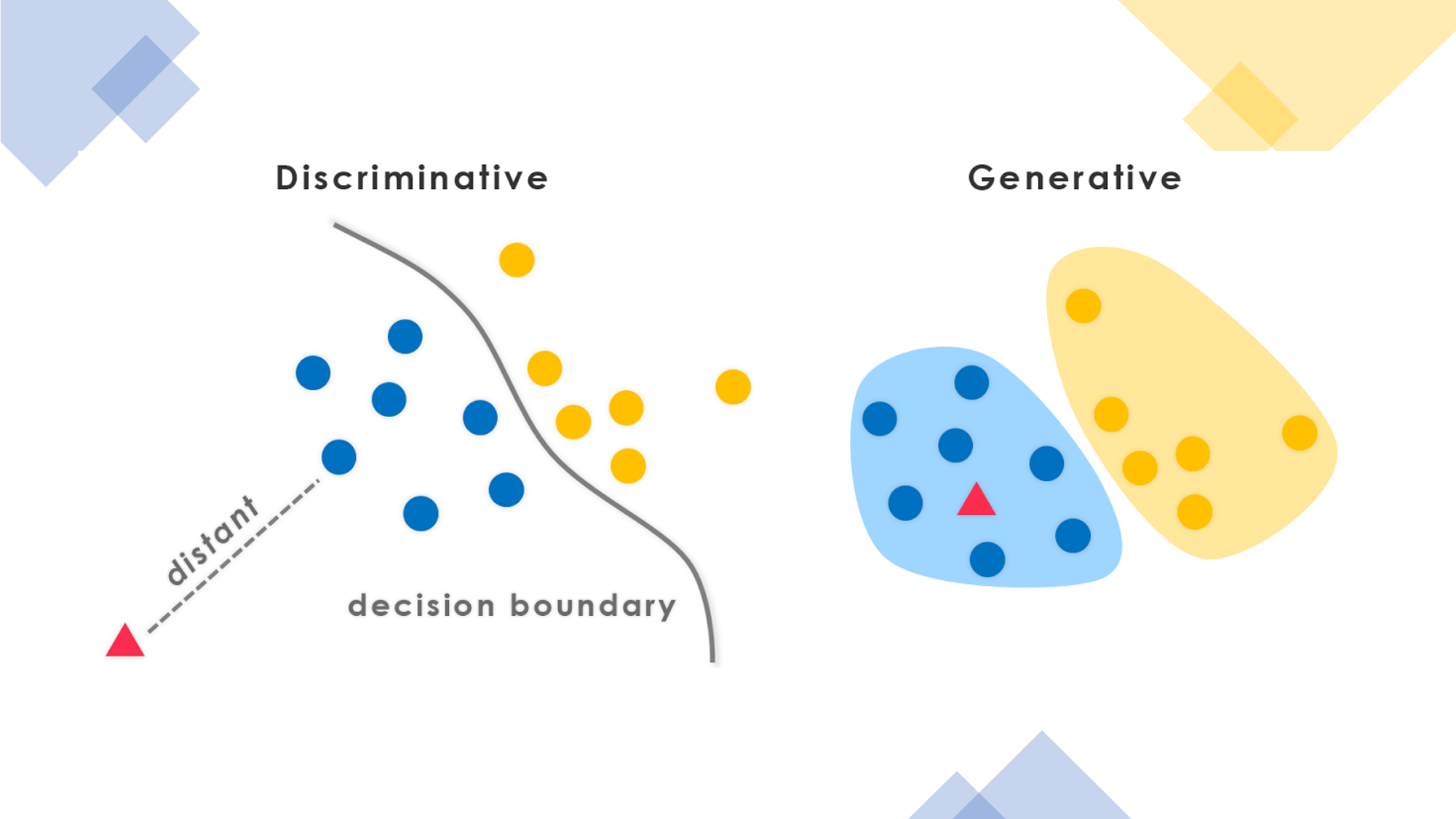
A good way to understand DGMs is to contrast it with its best-known complement: discriminative models. Often described as siblings: generative and discriminative models encompass the different ways in which we learn about the world. Conceptually, generative models can attempt to generalize everything they see whether discriminative models learn the unique properties in what they see. Both discriminative and generative models have strengths and weaknesses. Discriminative algorithms tend to perform incredibly well in classification tasks involving high quality datasets. However, generative models have the unique advantage that can create new datasets similar to existing data and operate very efficiently in environments that lack a lot of labeled datasets.
The essence of generative models was brilliantly captured in a 2016 blog post by OpenAI in which they stated that:
“Generative models are forced to discover and efficiently internalize the essence of the data in order to generate it.”
In that same blog post, OpenAI outlined a taxonomy for categorizing DGMs which included three main groups:
I. Variational Autoencoders: An encoder-decoder framework that allows to formalize this problem in the framework of probabilistic graphical models where we are maximizing a lower bound on the log likelihood of the data.
II. Autoregresive Models: This type of model factorize the distribution of the training data into conditional distributions effectively modeling every individual dimension of the dataset from previous dimensions.
III. Generative Adversarial Networks: A generator-discriminator framework that uses an adversarial game to generate the data distributions.
In recent years, we have seen major advancements applying DGMs to large scale models such as OpenAI GPT-2 or Microsoft’s Turing-NLG. These models followed similar learning principles: self-supervised pre-training with task-specific fine-tuning. The biggest question remains whether DGMs can be systematized for large-scale learning tasks. In that regard, Microsoft Research recently unveiled three major research efforts.
Optimus
In the paper Optimus: Organizing sentences with pre-trained modeling of a universal latent space, Microsoft Research introduces a large-scale VAE model for natural language tasks. Optimus provides an innovative DGM that can be both a powerful generative model and an effective representation learning framework for natural language.
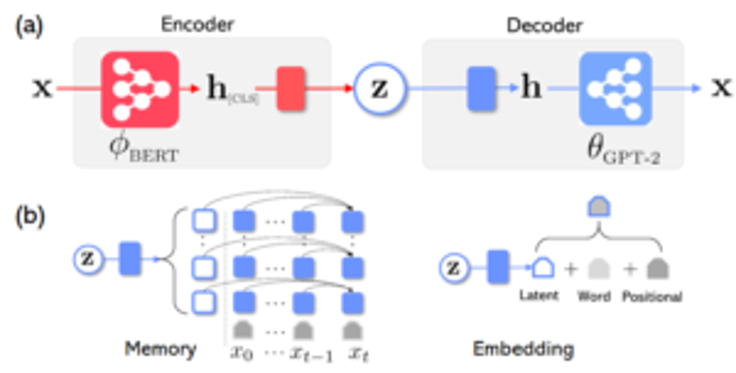
Traditionally, large scale pre-trained natural language models have been specialized in a single role. Models such as GPT-2 or Megatron have proven to be powerful decoders while models like BERT exceled as large scale encoders. Optimus combines both approaches in an novel architecture shown below:
The Optimus architecture includes a BERT-based encoder and a GPT-2-based decoder. To connect BERT and GPT-2, Optimus used two different approaches. The first approach the latent variable (z) is represented as an additional memory-vector for the decoder to attend. Alternatively, the second approach adds the latent variable(z) is added on the bottom embedding layer the decoder and directly used in every decoding step.
The initial tests in Optimus showed key advantages over existing pre-trained language models:
- Language Modeling: Compared with all existing small VAEs, Optimus shows much better representation learning performance, measured by mutual information and active units.
- Guided Language Generation: Optimus showed unique capabilities to guide language generation at a semantic level.
- Low-Resource Language Understanding: By learning unique feature patterns, Optimus showed better classification performance and faster adaption than alternative models.
FQ-GAN
In the paper Feature Quantization Improves GAN Training, Microsoft Research proposed a new DGM approach to image generation. FQ-GAN’s innovation relies on representing images in a discrete space rather than a continuous space.
Training with large datasets has been one of the main challenges of generative adversarial networks(GANs). Part of that challenge has been attributed to the fact that GANs rely on a non-stationary learning environment that depend on mini-batch statistics to match the features across different image regions. Since the mini-batch only provides an estimate, the true underlying distribution can only be learned after passing through a large number of mini-batches.
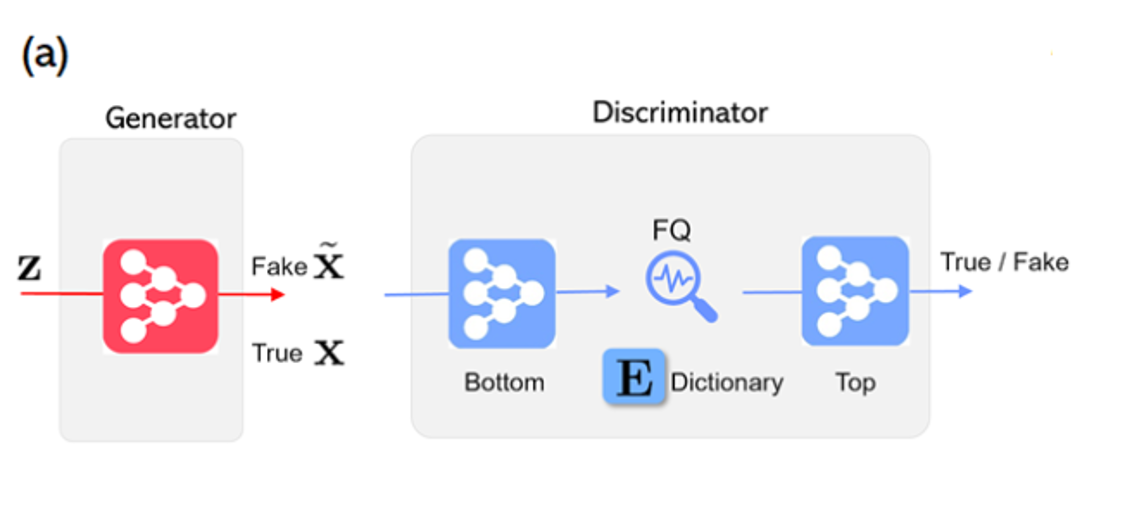
To address this challenge, FQ-GAN proposes the use of feature quantization (FQ) in the discriminator. A dictionary is first constructed via moving-averaged summary of features in recent training history for both true and fake data samples. This enables building a large and consistent dictionary on-the-fly that facilitates the online fashion of GAN training. Each dictionary item represents a unique feature prototype of similar image regions. By quantizing continuous features in traditional GANs into these dictionary items, the proposed FQ-GAN forces true and fake images to construct their feature representations from the limited values, when judged by discriminator. This alleviates the poor estimate issue of mini-batches in traditional GANs. The following diagram illustrate the main components of the FQ-GAN architecture:
The initial tests with FQ-GAN showed that the proposed model can improve image generation across diverse large-scale tasks. The FQ module proved to be effective in matching features in large training datasets. The principles of FQ-GAN can be easily incorporated into existing GAN architectures.
Prevalent
In the paper Towards Learning a Generic Agent for Vision-and-Language Navigation via Pre-training, Microsoft Research introduces Prevalent, a DGM agent that can navigate a visual environment following language instructions. The challenge that Prevalent addresses is a classic one: training deep learning agents in multi-modal inputs is nothing short of a nightmare.
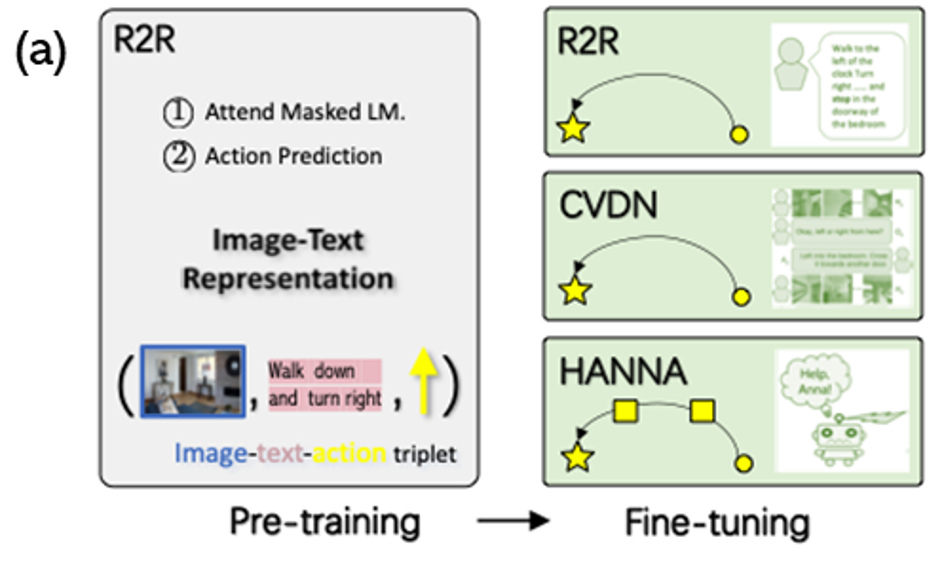
To address the multi-modal input challenge, Prevalent proposes to pre-train an encoder to align language instructions and visual states for joint representations. The image-text-action triplets at each time step are independently fed into the model, which is trained to predict the masked word tokens and next actions, thus formulating the visual and language navigation pre-training in the self-learning paradigm.
To model the visual and language navigation tasks, Prevalent relied on three fundamental datasets: : Room-to-room (R2R), cooperative vision-and-dialog navigation (CVDN), and “Help, Anna!” (HANNA). R2R is an in-domain task, where the language instruction is given at the beginning, describing the full navigation path. CVND and HANNA are out-of-domain tasks; the former is to navigate based on dialog history, while the latter is an interactive environment, where intermediate instructions are given in the middle of navigation.
The Prevalent architecture collects the image-text-action triplets are collected from the R2R dataset and fine-tuned for the tasks in the R2R, CVDN and HANNA environments. The result is an agent that is able to not only master the three environment but to effectively generalize knowledge for unseen environments and tasks.
DGMs are a key element to scale deep learning models. Microsoft Research efforts with Optimus, FQ-GAN and Prevalent present new ideas that can be incorporated into the new generation of DGM models. Microsoft Research open sourced the code related to this efforts together with the research papers.
Original. Reposted with permission.
Related:
- Microsoft Open Sources ZeRO and DeepSpeed: The Technologies Behind the Biggest Language Model in History
- Which Face is Real? Applying StyleGAN to Create Fake People
- Microsoft Research Uses Transfer Learning to Train Real-World Autonomous Drones