Microsoft Open Sources ZeRO and DeepSpeed: The Technologies Behind the Biggest Language Model in History
The two efforts enable the training of deep learning models at massive scale.
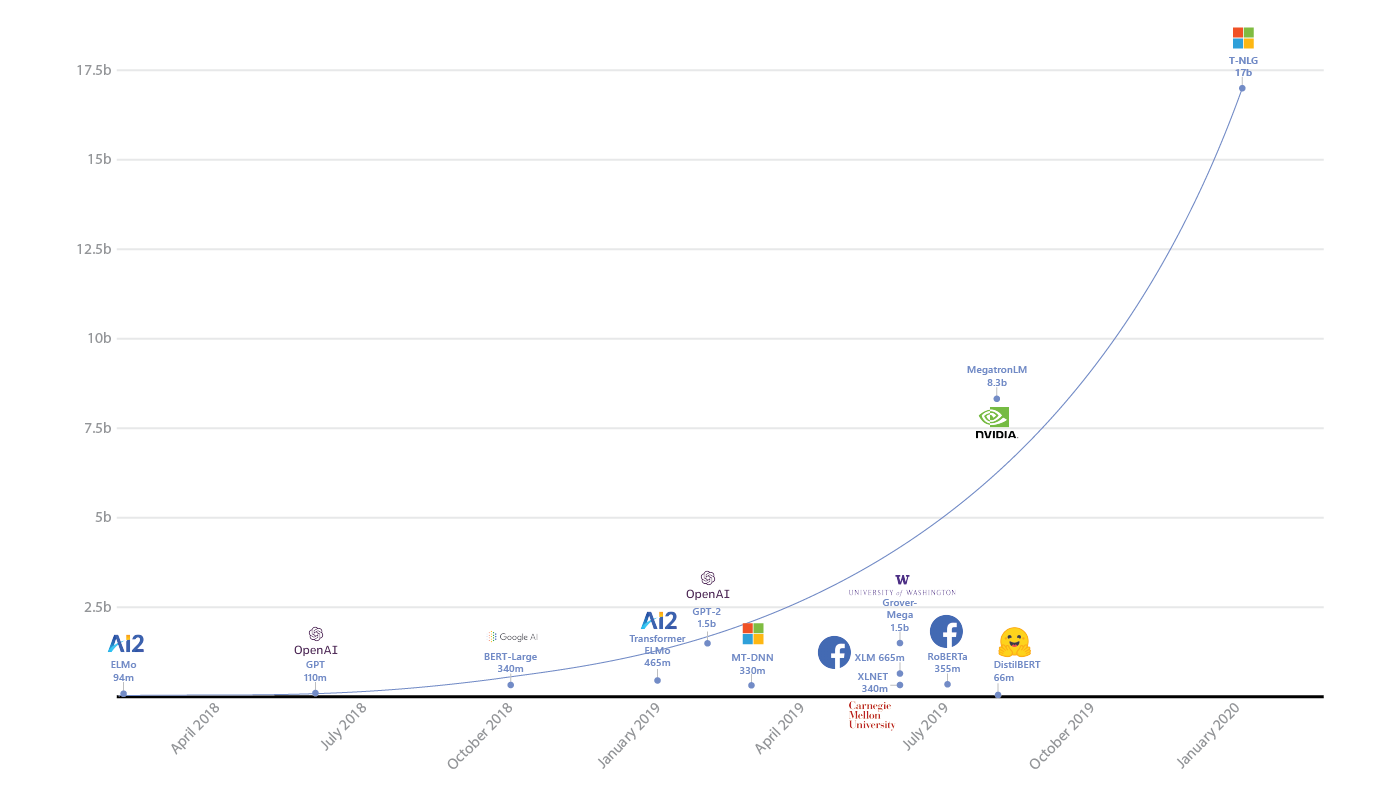
Earlier this week, the deep learning community was astonished when Microsoft Research unveiled the Turing Natural Language Generation (T-NLG) model which is considered the largest natural language processing(NLP) model in the history of artificial intelligence(AI). With 17 billion parameters, T-NLG outperforms other massive deep learning language models (LM), such as BERT and GPT-2. It’s even hard to comprehend the computational effort that took to train such a large model. Well, together with the announcement, Microsoft also open sourced the technologies that made possible to train T-NLG in the form of an open source library called DeepSpeed which includes a new parallelized optimizer called ZeRO.
When comes to natural language models, bigger is literally better. T-NLG is a Transformer-based generative language model, which means it can generate words to complete open-ended textual tasks. In addition to completing an unfinished sentence, it can generate direct answers to questions and summaries of input documents. In natural language tasks, the bigger the model and the more diverse and comprehensive the pretraining data, the better it performs at generalizing to multiple downstream tasks even with fewer training examples. It is easier to build a large multi-task model language than training new models for individual language tasks.
How big is T-NLG exactly? In addition to the 17 billion parameters, T-NLG model has 78 Transformer layers with a hidden size of 4256 and 28 attention heads. The architecture represents a massive leap forward in the evolution of large NLP models as illustrated in the following figure:
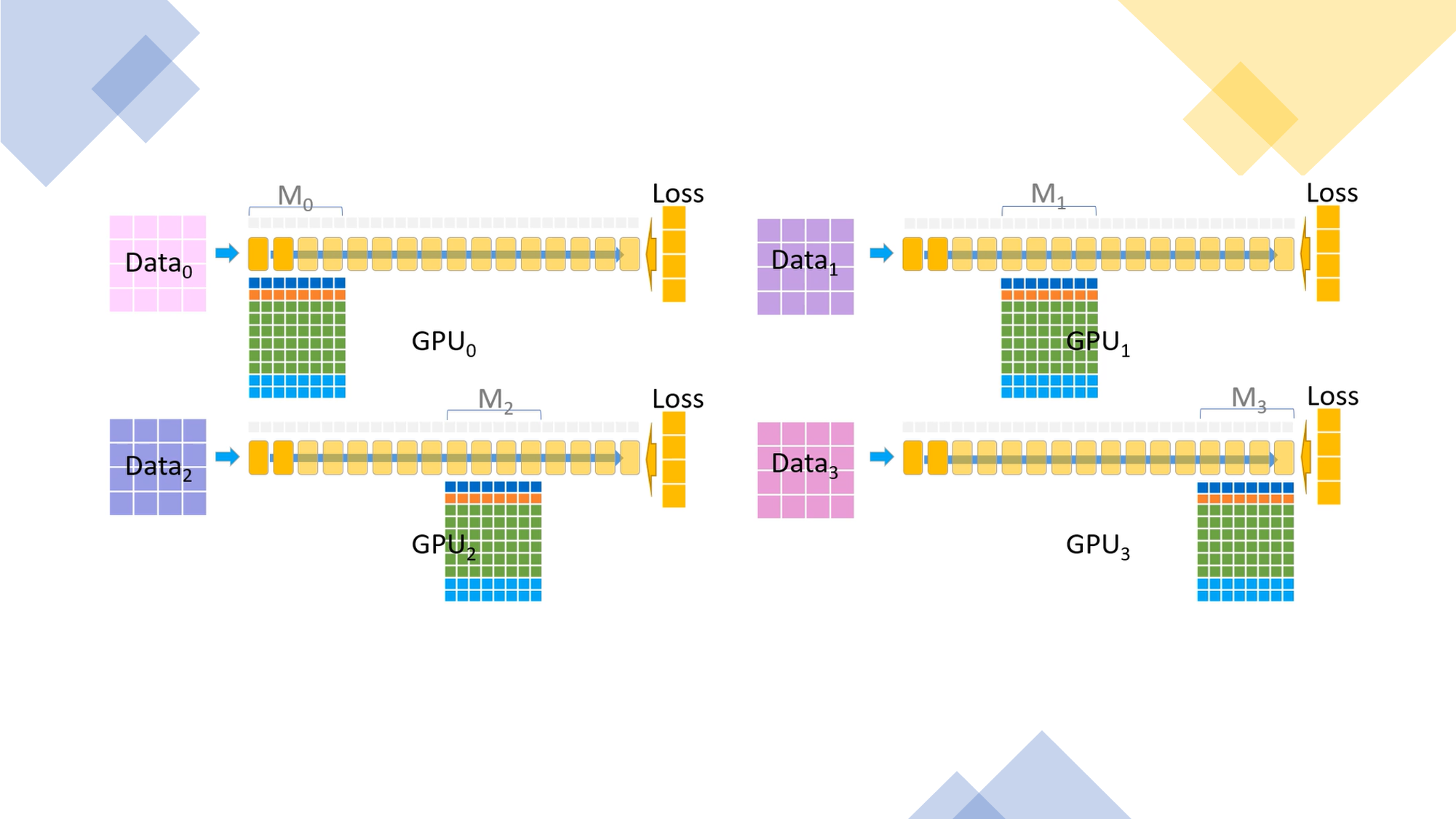
T-NLG is not also impressive in terms of size and performance but about its training processes. While architecting massive NLP models is certainly doable with today’s technology, the cost of training such large models results prohibited for most organizations. The process of scaling training is based on two fundamental parallelization vectors: data parallelism and model parallelism. Data parallelism focuses on scaling training on a single node/device while model parallelism looks for distributing training across multiple nodes. However, both techniques come with their own set of challenges:
- Data parallelism does not help reduce memory footprint per device: a model with more than 1 billion parameters runs out of memory even on GPUs with 32GB of memory.
- Model parallelism does not scale efficiently beyond a single node due to fine-grained computation and expensive communication. Model parallelism frameworks frequently require extensive code integration that may be model architecture specific.
To overcome these challenges, Microsoft Research developed its own optimizer to parallelized the training of large deep learning models.
Enter ZeRO
Zero Redundacy Optimizer(ZeRO) is an optimization module that maximizes both memory and scaling efficiency. The details behind ZeRO were outlined in a research paper published simultaneously with the release of T-NLG. Conceptually, tries to address the limitations of data parallelism and model parallelism while achieving the merits of both. ZeRO uses an approach called ZeRO-powered data parallelism removes the memory redundancies across data-parallel processes by partitioning the OGP model states across data parallel processes instead of replicating them, and it retains the compute/communication efficiency by retaining the computational granularity and communication volume of data parallelism using a dynamic communication schedule during training. This method reduces per-device memory footprint of a model linearly with the increase in data parallelism degree while maintaining the communication volume close to that of the default data parallelism. Additionally, the ZeRO-powered data parallelism can be combined with any of the traditional model parallelism methods to optimize performance even further.
From an algorithmic perspective, ZeRO has three main stages that correspond to the partitioning of optimizer states, gradients, and parameters respectively.
- Optimizer State Partitioning (Pos) — 4x memory reduction, same communication volume as data parallelism
- Add Gradient Partitioning (Pos+g) — 8x memory reduction, same communication volume as data parallelism
- Add Parameter Partitioning (Pos+g+p) — Memory reduction is linear with data parallelism degree Nd. For example, splitting across 64 GPUs (Nd = 64) will yield a 64x memory reduction. There is a modest 50% increase in communication volume.

The first implementation of ZeRO was included in an new open source library focused on distributed training.
DeepSpeed
Microsoft’s DeepSpeed is a new open source framework focused on optimizing the training of massively large deep learning models. The current release includes the first implementation of ZeRO as well as other optimization methods. From a programming standpoint, DeepSpeed is built on top of PyTorch and provides a simple API that allows engineers to leverage training parallelization techniques with just a few lines of code. DeepSpeed abstracts all of the difficult aspects of large scale training, such as parallelization, mixed precision, gradient accumulation, and checkpoints allowing developers to focus on the construction of the models.
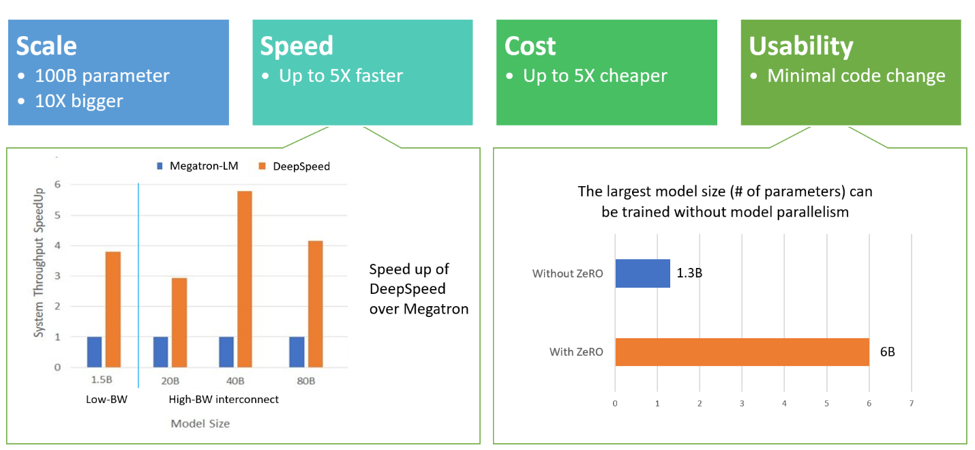
From the functional standpoint, DeepScale excels at four key aspects:
- Scale: DeepSpeed provides system support to run models up to 100 billion parameters which represents a 10x improvement compared to other training optimization frameworks.
- Speed: In the initial tests, DeepSpeed showed 4x-5x higher throughput than other libraries.
- Cost: Models could be trained using DeepSpeed at three times less cost than alternatives.
- Usability: DeepSpeed does not require refactoring PyTorch models and could be used with just a few lines of code.
Turing-NLG has been an impressive milestone for the deep learning community but one that could have stayed as a nice research effort. By open sourcing DeepSpeed and the first implementation of ZeRO, Microsoft is helping to streamline the training of large deep learning models and the implementation of more comprehensive conversational applications.
Original. Reposted with permission.
Related:
- Microsoft Open Sources Jericho to Train Reinforcement Learning Using Linguistic Games
- Inside The Machine Learning that Google Used to Build Meena: A Chatbot that Can Chat About Anything
- Amazon Uses Self-Learning to Teach Alexa to Correct its Own Mistakes