Amazon Uses Self-Learning to Teach Alexa to Correct its Own Mistakes
The digital assistant incorporates a reformulation engine that can learn to correct responses in real time based on customer interactions.

Digital assistant such as Alexa, Siri, Cortana or the Google Assistant are some of the best examples of mainstream adoption of artificial intelligence(AI) technologies. These assistants are getting more prevalent and tackling new domain-specific tasks which makes the maintenance of their underlying AI particularly challenging. The traditional approach to build digital assistant has been based on natural language understanding(NLU) and automatic speech recognition(ASR) methods which relied on annotated datasets. Recently, the Amazon Alexa team published a paper proposing a self-learning method to allow Alexa correct mistakes while interacting with users.
The rapid evolution of language and speech AI methods have made the promise of digital assistants a reality. These AI methods have become a common component of any deep learning framework allowing any developer to build fairly sophisticated conversational agents. However, the challenges are very different when operating at the scale of a digital assistant like Alexa. Typically, the accuracy of the machine learning models in these conversational agents is improved by manually transcribing and annotating data. However, this task become incredibly expensive and time consuming when you need to implement it across different domains and tasks. As a result, AI researchers have started exploring techniques such as semi-supervised learning or reinforcement learning to improve the retraining processes of conversational agents. The Alexa team decided to go on a slightly different direction by leveraging a not-very-well-known deep learning discipline.
Self-Learning and Alexa
The term self-learning is one of those overloaded terms in the deep learning space. Conceptually, self-learning refers to systems that can automatically learn from interactions with their environment sometimes without an external reward signal. Based on that generic definition, is not surprising that people often mix self-learning with similar disciplines such as unsupervised learning or reinforcement learning. To avoid getting into a debate about terminology, I would prefer to explain how self-learning relates to the Alexa experience.
The key idea of bringing self-learning to Alexa is to build an architecture that proposed automatically detects the errors, generate reformulations and deploys fixes to the runtime system to correct different types of errors occurring in different components of the system. Consider the example utterance, ”play maj and dragons”. Now, without reformulation, Alexa would inevitably come up with the response, ”Sorry, I couldn’t find maj and dragons”. Some customers give up at this point, while others may try enunciating better for Alexa to understand them: ”play imagine dragons”. These real time reformulations can be used to retrain Alexa in order to improve future interactions.
Absorbing Markov Chains
To build a real time reformulation engine, the Alexa team innovated upon on a well-established machine learning technique known as Markov chains. A Markov chain models a dynamic system as a sequence of states, each of which has a certain probability of transitioning to any of several other states. Often, Markov chains aren’t really chains; the sequences of states can branch out to form more complex networks of transitions. Alexa’s self-learning engine is based on a variation of this method known as absorbing Markov chains(AMC).
Conceptually, AMCs are Markov chains with two distinctive properties:
- It has a final state, with zero probability of transitioning to any other.
- The final state is accessible from any other system state.
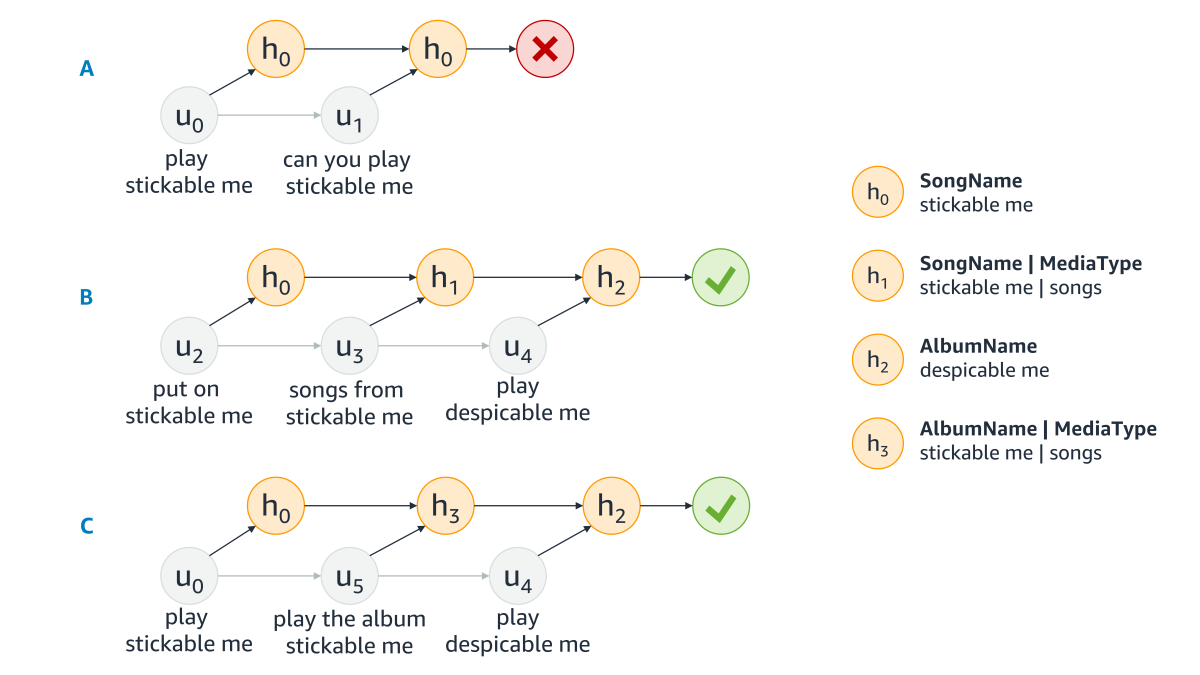
Alexa’s self-learning engine model sequences of rephrased requests as absorbing Markov chains. There are two absorbing states, success and failure, and our system identifies them from a variety of clues. For instance, if the customer says “Alexa, stop” and issues no further requests, or if Alexa returns a generic failure response, such as, “Sorry, I don’t know that one”, the absorbing state is a failure. If, on the other hand, the final request is to play a song, which is then allowed to play for a substantial amount of time, the absorbing state is a success. These principles are outlined in the following diagram. The absorbing states are represented by a success checkmark or failure(X) while the customer utterance(u0, u1, u2) translate into corresponding states in the chain (h0, h1, h2).
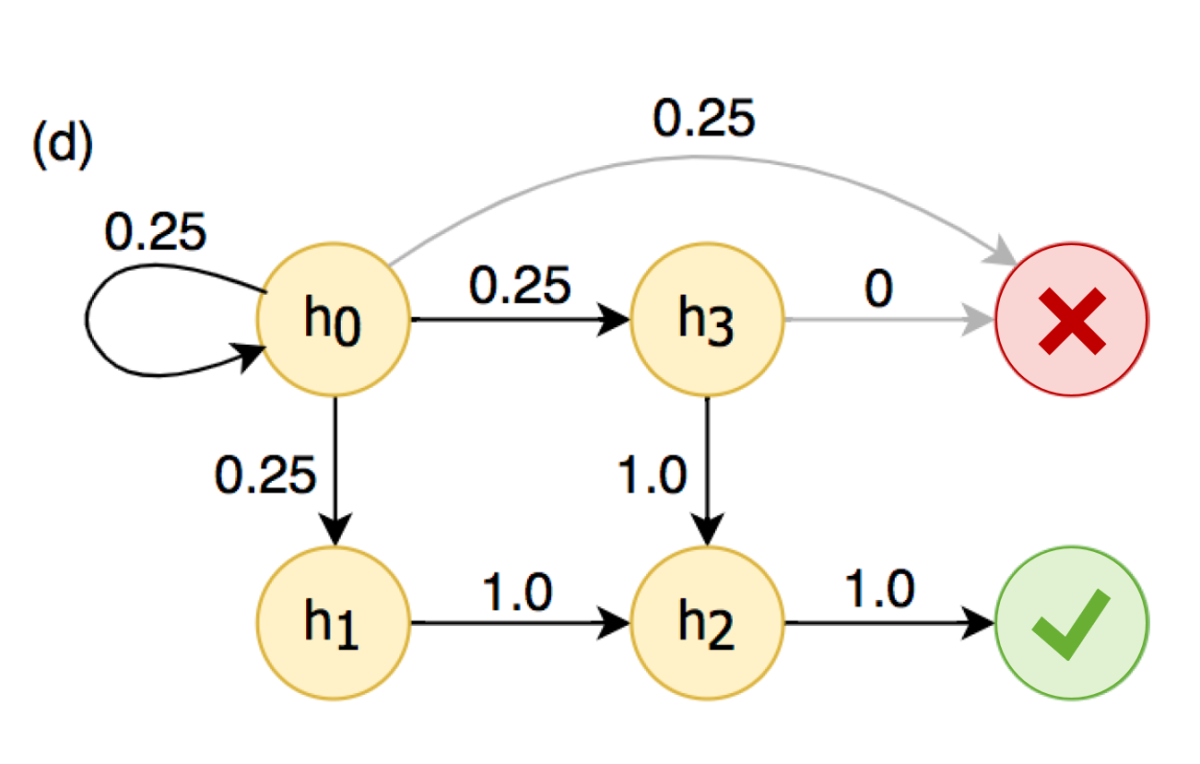
The first step in Alexa’s self-learning reformulation algorithm is to construct an AMC using millions of customer interactions. The next step is to calculate the frequency with which any given state would follow any other, across all the absorbing Markov chains. In the example at left, for instance, h0 has a 25% chance of being followed by each of h0, h1, h3, and the absorbing failure state. The result of this process is a new Markov chain in which the transition probabilities between states are defined by the frequency with which a given state follows another in our data.
Having the aggregated AMC, the self-learning model simply needs to identify the path that leads with highest probability to the success state. The penultimate state in the path — the one right before the success state — is the one that the system should use to overwrite the first state in the path. In the example above, for instance, the system would learn to overwrite h0, h1, and h3 all of which misinterpret the customer as having said “stickable me”, with h2 (AlbumName = “Despicable Me”).
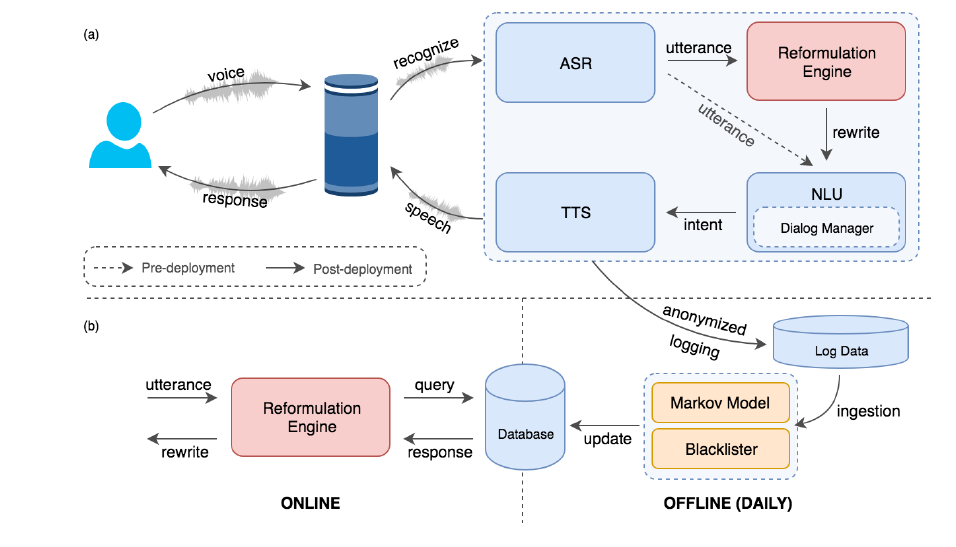
To incorporate the self-learning reformulation engine into the Alexa system, the team relied on a very simple architecture. The Alexa conversational AI system follows a rather well-established architectural pattern of cloud-based digital voice assistants comprising of ASR, NLU systems with a built-in dialog manager, and a text-to-speech (TTS) system. In this architecture, the team added a self-learning reformulation engine that first intercepts the utterance being passed onto the NLU system and rewrites it with our reformulation engine. After that, the engine passes the rewrite of the original utterance back to NLU for interpretation, restoring the original data flow. The reformulation engine is essentially implements rather lightweight micro-services architecture that encapsulates the access to a high-performance, low-latency database, which is queried with the original utterance to yield its corresponding rewrite candidate.
Even though the paper describing Alexa’s self-learning model was just published, the system has been in production for over a year and has been correcting several millions of requests per week. During that period, the Alexa team estimates that the self-learning model has reduced customer frictions by over 30%. Certainly, the idea of self-learning reformulation agents can become an important component of conversational agents in order to fix errors without relying on human intervention. We should expect to see further innovation in this area in the near future.
Original. Reposted with permission.
Related:
- Amazon Gets Into the AutoML Race with AutoGluon: Some AutoML Architectures You Should Know About
- Microsoft Introduces Project Petridish to Find the Best Neural Network for Your Problem
- Microsoft Open Sources Jericho to Train Reinforcement Learning Using Linguistic Games