Inside The Machine Learning that Google Used to Build Meena: A Chatbot that Can Chat About Anything
Meena is one of the major milestones in the history of NLU. How did Google build it?

It seems that every year Google plans to shock the artificial intelligence(AI) world with new astonishing progress in natural language understanding(NLU) systems. Last year, the BERT model definitely stole the headlines of the NLU research space. Just a few weeks into 2020, Google Research published a new paper introducing Meena, a new deep learning model that can power chatbots that can engage in conversations about any domain.
NLU has been one of the most active areas of research of the last few years and have produced some of the most widely adopted AI systems to date. However, despite all the progress, most conversational systems remain highly constrained to a specific domain which contrasts with our ability as humans to naturally converse about different topics. In NLU theory, those specialized conversational agents are known as closed-domain chatbots. The alternative is an emerging area of research known as open-domain chatbots that focuses on building conversational agents that chat about virtually anything a user wants. If effective, open-domain chatbots might be a key piece in the journey to humanize computer interactions.
Despite the excitement around open-domain chatbots, the current implementation attempts still have weaknesses that prevent them from being generally useful: they often respond to open-ended input in ways that do not make sense, or with replies that are vague and generic. With Meena, Google ventures tries to address some of these challenges by building an open-domain chatbot that can chat about almost anything.
Before building Meena, Google had to solve a non-trivial challenge that is often ignored in open-domain chatbot systems. A key criterion to evaluate the quality of an open-domain chatbot is the fact that its dialogs feel natural to human. That idea seems intuitive but also incredibly subjective. How can we measure the human-likeness of a dialog? To address that challenge, Google started by introducing a new metric as the cornerstone of the Meena chatbot.
Sensibleness and Specificity Average
Sensibleness and Specificity Average(SSA) is a new metric for open-domain chatbots that h captures basic, but important attributes for human conversation. Specifically, SSA tries to quantify two key aspects of human-conversations:
- making sense.
- being specific.
Sensibleness arguably covers some of the most basic aspects of conversational human-likeness, such as common sense and logical coherence. Sensibleness also captures other important aspects of a chatbot, such as consistency. However, being sensible is not enough. A generic response (ex: I don’t know) can be sensible, but it is also boring and unspecific. Such responses are frequently generated by bots that are evaluated according to metrics like sensibleness alone. Specificity is the second metric that can help quantify human-likeness of a conversational interaction. For instance, A says, “I love tennis,” and B responds, “That’s nice,” then the utterance should be marked, “not specific”. That reply could be used in dozens of different contexts. However, if B responds, “Me too, I can’t get enough of Roger Federer!” then it is marked as “specific”, since it relates closely to what is being discussed.
SSA →f(Sensibleness, Specificity)
The actual mathematical formulation of the SSA metric is pretty sophisticated but the initial experiments conducted by Google showed a strong correlation with the human-likeness of a chatbot. The following figure shows that correlation for different chatbots(blue dots).
Having formulated a quantifiable metric to evaluate human-likeness, the next step was to build an open-domain chatbot optimized for that metric.
Meena
Meena is an end-to-end, neural conversational model that learns to respond sensibly to a given conversational context. Surprisingly, Meena does not rely on a brand-new architecture but leverages the Evolved Transformer Architecture(ET) pioneered by Google last year.
ET
As its name indicates, ET is an optimization over traditional Transformer architectures that are common in NLU tasks. The optimizations were the results of applying neural architecture search(NAS) to a series of Transformer models used in NLU scenarios.
At first glance, ET looks like most Transformer neural network architectures. It has an encoder that encodes the input sequence into embeddings and a decoder that uses those embeddings to construct an output sequence; in the case of translation, the input sequence is the sentence to be translated and the output sequence is the translation. However, ET adds some interesting changes to Transformer models. The most interesting of those is convolutional layers at the bottom of both its encoder and decoder modules that were added in a similar branching pattern in both places. This optimization is particularly interesting because the encoder and decoder architectures are not shared during the NAS, so this architecture was independently discovered as being useful in both the encoder and decoder, speaking to the strength of this design. Whereas the original Transformer relied solely on self-attention, the Evolved Transformer is a hybrid, leveraging the strengths of both self-attention and wide convolution.

Meena and ET
A way to think about Meena is as a massive ET architecture. Meena has a single ET encoder block and 13 Evolved Transformer decoder blocks as illustrated below. The encoder is responsible for processing the conversation context to help Meena understand what has already been said in the conversation. The decoder then uses that information to formulate an actual response. Through tuning the hyper-parameters, we discovered that a more powerful decoder was the key to higher conversational quality.
One of the things that Meena demonstrates is that, when it comes to open-domain chatbots, size matters. For decades the AI research community has been debating whether in order to reach a point where a model can carry out high-quality, multi-turn conversations with humans, we could simply take an end-to-end model and make it bigger — by adding more training data and increasing its parameter count — or is it necessary to combine such a model with other components? Meena showed that massively large end-to-end models can achieve human like performance in conversational interactions.
How big is Meena? Well, the first version of Meena reportedly has 2.6 billion parameters and is trained on 341 GB of text, filtered from public domain social media conversations. To put that in context, compared to an existing state-of-the-art generative model, OpenAI GPT-2, Meena has 1.7x greater model capacity and was trained on 8.5x more data.
The initial tests with Meena showed that the chatbot was able to engage in conversations across a large variety of topics achieving high levels of SSA.

One of the most surprising discoveries during the Meena research was the correlation exhibited between the SSA metric and the well-known perplexity performance indicator in NLU models. Conceptually, perplexity measures the uncertainty of a language model. The lower the perplexity, the more confident the model is in generating the next token (character, subword, or word). During tests, the SSA metric and its individual factors(specificity and sensibleness) showed strong correlations to perplexity in open-domain chatbots.
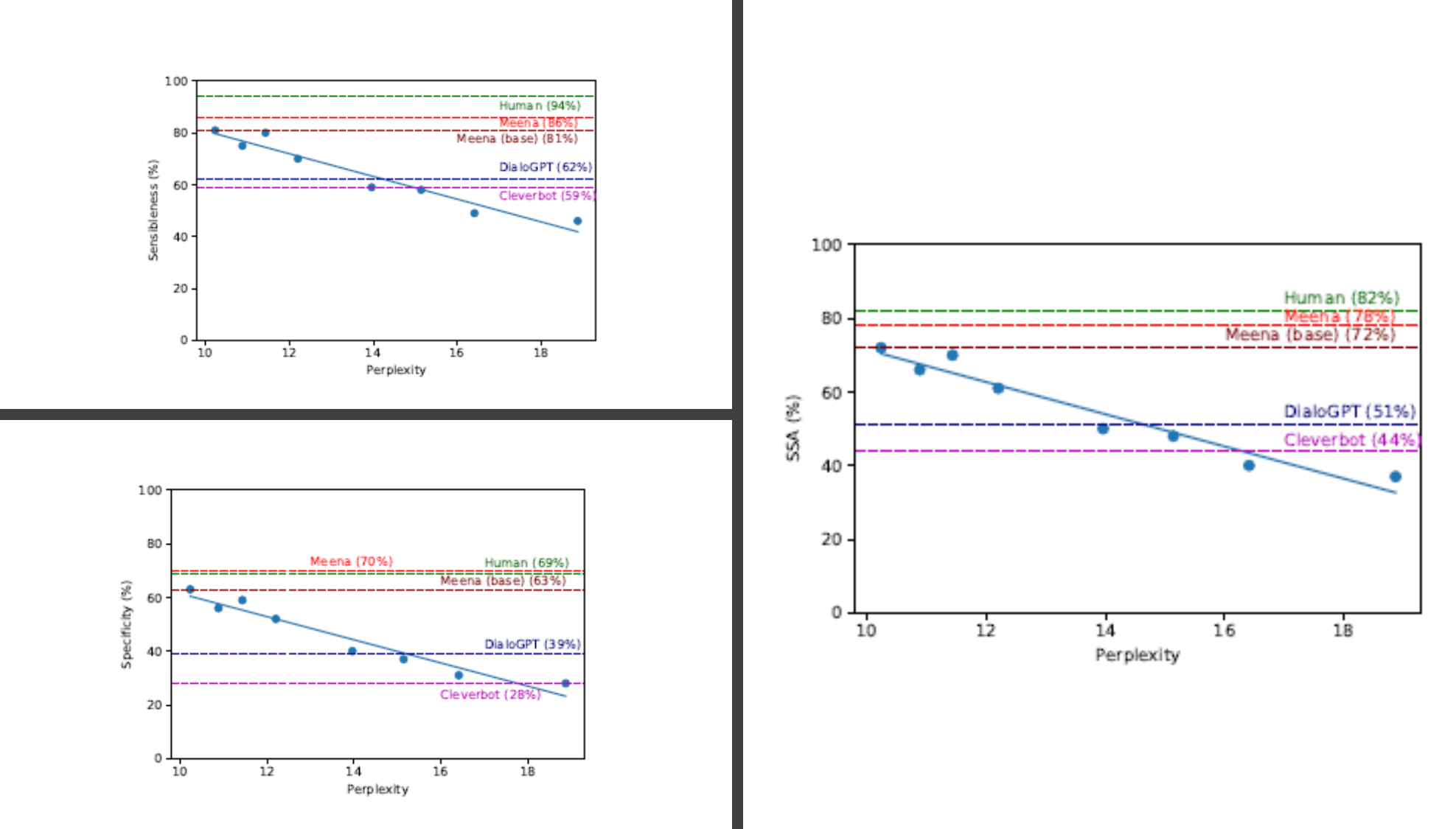
Given its performance requirements, Meena is out of reach for most organizations. However, it is unquestionable that Meena represents a major milestone in the implementation of conversational interfaces. In addition to the model itself, Meena contributed the SSA metric that take us closer to evaluate the human-likeness of chatbot interactions. In the future, we should see other human-like conversation attributes like humor or empathy added to the SSA metric. Similarly, we should expect to see new open-domain chatbots build on some of the principles of Meena to power the next generation of conversational interfaces.
Original. Reposted with permission.
Related:
- Let’s Build an Intelligent Chatbot
- NLP vs. NLU: from Understanding a Language to Its Processing
- Amazon Uses Self-Learning to Teach Alexa to Correct its Own Mistakes