Let’s Build an Intelligent Chatbot
Check out this step by step approach to building an intelligent chatbot in Python.
In the article Build your first chatbot using Python NLTK we wrote a simple python code and built a chatbot. The questions and answers were loosely hardcoded which means the chatbot cannot give satisfactory answers for the questions which are not present in your code. So our chatbot is considered not an intelligent bot.
Here in this article, we will build a document or information-based chatbot that will dive deep into your query and based on that it's going to respond.
Introduction
A chatbot (also known as a talkbot, chatterbot, Bot, IM bot, interactive agent, or Artificial Conversational Entity) is a computer program or an artificial intelligence which conducts a conversation via auditory or textual methods. Such programs are often designed to convincingly simulate how a human would behave as a conversational partner, thereby passing the Turing test. Chatbots are typically used in dialog systems for various practical purposes including customer service or information acquisition. — Wikipedia
Chatbots are hot today. Who doesn't know about them? Chatbots are seen as the future way of interacting with your customers, employees and all other people out there you want to talk to. The essence is that this communication is a dialogue. Contrary to just publishing the information, people who use a chatbot can get to the information they desire more directly by asking questions.

What do Chatbots do?
Chatbots are relevant because of the following reasons:
- They make available to people, the right information at the right time, right place and most importantly only when they want.
- About 90% of our time on mobile is spent on email and messaging platforms. So it makes sense to engage customers using chatbots instead of diverting them to a website or a mobile app.
- The advancements in artificial intelligence, machine learning, and natural language processing, allowing bots to converse more and more, like real people.
With chatbots, firms can be available 24/7 to users and visitors. Now, the sales and customer service teams can focus on more complex tasks while the chatbot guides people down the funnel.

Modern chatbots do not rely solely on text, and will often show useful cards, images, links, and forms, providing an app-like experience.
Depending on way bots are programmed, we can categorize them into two variants of chatbots: Rule-Based (dumb bots) & Self Learning (smart bots).
- Rule-Based Chatbots: This variety of bots answer questions based on some simple rules that they are trained on.
- Self-Learning Chatbots: This variety of bots rely on Artificial Intelligence(AI) & Machine Learning(MI) technologies to converse with users.
Self-learning Chatbots are further divided into Retrieval based and Generative.
Retrieval based
Retrieval based bots work on the principle of directed flows or graphs.The bot is trained to rank the best response from a finite set of predefined responses. The responses here are entered manually, or based on a knowledge base of pre-existing information.
Eg. What are your store timings?
Answer: 9 to 5 pm
These systems can be extended to integrate with 3rd Party systems as well.
Eg. Where is my order?
Answer: It’s on its way and should reach you in 10 mins
Retrieval based bots are the most common types of chatbots that you see today. They allow bot developers and UX to control the experience and match it to the expectations of our customers. They work best for goal-oriented bots in customer support, lead generation and feedback. We can decide the tone of the bot, and design the experience, keeping in mind the customer’s brand and reputation.
Generative
Another method of building chatbots is using a generative model. These chatbots are not built with predefined responses. Instead, they are trained using a large number of previous conversations, based upon which responses to the user are generated. They require a very large amount of conversational data to train.
Generative models are good for conversational chatbots with whom the user is simply looking to exchange banter. These models will virtually always have a response ready for you. However, in many cases, the responses might be arbitrary and not make a lot of sense to you. The chatbot is also prone to generating answers with incorrect grammar and syntax.
Chatbot building
There are a few things you need to know before moving forward. Natural Language Processing(NLP) using NLTK, TF-IDF and Cosine similarity.
Natural Language Processing(NLP) using NLTK
Natural language processing (NLP) is the ability of a computer program to understand human language as it is spoken. NLP is a component of artificial intelligence (AI).
The development of NLP applications is challenging because computers traditionally require humans to “speak” to them in a programming language that is precise, unambiguous and highly structured, or through a limited number of clearly enunciated voice commands. Human speech, however, is not always precise — it is often ambiguous and the linguistic structure can depend on many complex variables, including slang, regional dialects, and social context.
Natural Language Toolkit(NLTK)
NLTK is a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning, wrappers for industrial-strength NLP libraries, and an active discussion forum.
TF-IDF
We will compute the Term Frequency-Inverse Document Frequency (TF-IDF) vectors for each document. This will give you a matrix where each column represents a word in the overview vocabulary (all the words that appear in at least one document).
TF-IDF is the statistical method of evaluating the significance of a word in a given document.
TF — Term frequency(tf) refers to how many times a given term appears in a document.
IDF — Inverse document frequency(idf) measures the weight of the word in the document, i.e if the word is common or rare in the entire document.
The TF-IDF intuition follows that the terms that appear frequently in a document are less important than terms that rarely appear.
Fortunately, scikit-learn gives you a built-in TfIdfVectorizer class that produces the TF-IDF matrix quite easily.
Cosine similarity
Now we have this matrix, we can easily compute a similarity score. There are several options to do this; such as the Euclidean, the Pearson, and the cosine similarity scores. Again, there is no right answer to which score is the best.
We will be using the cosine similarity to calculate a numeric quantity that denotes the similarity between the two words. You use the cosine similarity score since it is independent of magnitude and is relatively easy and fast to calculate (especially when used in conjunction with TF-IDF scores). Mathematically, it is defined as follows:
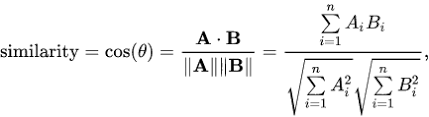
Since we have used the TF-IDF vectorizer, calculating the dot product will directly give us the cosine similarity score. Therefore, we will use sklearn's linear_kernel() instead of cosine_similarities() since it is faster.
Let's start coding…
So we’ll copy data from this website. The dataset contains everything related to Human Resource Management. Copy and paste the whole data in a text format. We’ll train our model based on this data and then check how well the model performs. Apart from this, I have also included Wikipedia python library so you can ask anything.
Importing all the required libraries.
import nltk
import random
import string
import re, string, unicodedata
from nltk.corpus import wordnet as wn
from nltk.stem.wordnet import WordNetLemmatizer
import wikipedia as wk
from collections import defaultdict
import warnings
warnings.filterwarnings("ignore")
nltk.download('punkt')
nltk.download('wordnet')
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity, linear_kernel
Load the dataset and convert every text into lowercase.
data = open('/../../chatbot/HR.txt','r',errors = 'ignore')
raw = data.read()
raw = raw.lower()
Let us check what our data looks like.
raw[:1000] 'human resource management is the process of recruiting, selecting, inducting employees, providing orientation, imparting training and development, appraising the performance of employees, deciding compensation and providing benefits, motivating employees, maintaining proper relations with employees and their trade unions, ensuring employees safety, welfare and healthy measures in compliance with labour laws of the land.\nhuman resource management involves management functions like planning, organizing, directing and controlling\nit involves procurement, development, maintenance of human resource\nit helps to achieve individual, organizational and social objectives\nhuman resource management is a multidisciplinary subject. it includes the study of management, psychology, communication, economics and sociology.\nit involves team spirit and team work.\nit is a continuous process.\nhuman resource management as a department in an organisation handles all aspects of employees and has various functi'
Data pre-processing
Let us now start with data cleaning and preprocessing by converting the entire data into a list of sentences.
sent_tokens = nltk.sent_tokenize(raw)
Our next step is to normalize these sentences. Normalization is a process that converts a list of words to a more uniform sequence. This is useful in preparing the text for later processing. By transforming the words to a standard format, other operations are able to work with the data and will not have to deal with issues that might compromise the process.
This step involves word tokenization, Removing ASCII values, Removing tags of any kind, Part-of-speech tagging, and Lemmatization.
def Normalize(text):
remove_punct_dict = dict((ord(punct), None) for punct in string.punctuation)
#word tokenization
word_token = nltk.word_tokenize(text.lower().translate(remove_punct_dict))
#remove ascii
new_words = []
for word in word_token:
new_word = unicodedata.normalize('NFKD', word).encode('ascii', 'ignore').decode('utf-8', 'ignore')
new_words.append(new_word)
#Remove tags
rmv = []
for w in new_words:
text=re.sub("</?.*?>","<>",w)
rmv.append(text)
#pos tagging and lemmatization
tag_map = defaultdict(lambda : wn.NOUN)
tag_map['J'] = wn.ADJ
tag_map['V'] = wn.VERB
tag_map['R'] = wn.ADV
lmtzr = WordNetLemmatizer()
lemma_list = []
rmv = [i for i in rmv if i]
for token, tag in nltk.pos_tag(rmv):
lemma = lmtzr.lemmatize(token, tag_map[tag[0]])
lemma_list.append(lemma)
return lemma_list
So the data preprocessing part is over now let's define welcome notes or greetings that means if a user provides is a greeting message, the chatbot shall respond with a greeting as well based on keyword matching.
welcome_input = ("hello", "hi", "greetings", "sup", "what's up","hey",)
welcome_response = ["hi", "hey", "*nods*", "hi there", "hello", "I am glad! You are talking to me"]
def welcome(user_response):
for word in user_response.split():
if word.lower() in welcome_input:
return random.choice(welcome_response)
Generate chatbot response
To generate a response from our chatbot for input questions, the concept of document similarity will be used. As I have already discussed the TFidf vectorizer is used to convert a collection of raw documents to a matrix of TF-IDF features and to find the similarity between words entered by the user and the words in the dataset we will use cosine similarity.
We define a function generateResponse() which searches the user’s input words and returns one of several possible responses. If it doesn’t find the input matching any of the keywords then instead of giving just an error message you can ask your chatbot to search Wikipedia for you. Just type “tell me about any_keyword”. Now if it doesn't find anything in Wikipedia the chatbot will generate a message “No content has been found”.
def generateResponse(user_response):
robo_response=''
sent_tokens.append(user_response)
TfidfVec = TfidfVectorizer(tokenizer=Normalize, stop_words='english')
tfidf = TfidfVec.fit_transform(sent_tokens)
#vals = cosine_similarity(tfidf[-1], tfidf)
vals = linear_kernel(tfidf[-1], tfidf)
idx=vals.argsort()[0][-2]
flat = vals.flatten()
flat.sort()
req_tfidf = flat[-2]
if(req_tfidf==0) or "tell me about" in user_response:
print("Checking Wikipedia")
if user_response:
robo_response = wikipedia_data(user_response)
return robo_response
else:
robo_response = robo_response+sent_tokens[idx]
return robo_response#wikipedia search
def wikipedia_data(input):
reg_ex = re.search('tell me about (.*)', input)
try:
if reg_ex:
topic = reg_ex.group(1)
wiki = wk.summary(topic, sentences = 3)
return wiki
except Exception as e:
print("No content has been found")
Finally defining the chatbot user conversation handler.
Note: The program will exit if you type Bye, shutdown, exit or quit.
flag=True
print("My name is Chatterbot and I'm a chatbot. If you want to exit, type Bye!")
while(flag==True):
user_response = input()
user_response=user_response.lower()
if(user_response not in ['bye','shutdown','exit', 'quit']):
if(user_response=='thanks' or user_response=='thank you' ):
flag=False
print("Chatterbot : You are welcome..")
else:
if(welcome(user_response)!=None):
print("Chatterbot : "+welcome(user_response))
else:
print("Chatterbot : ",end="")
print(generateResponse(user_response))
sent_tokens.remove(user_response)
else:
flag=False
print("Chatterbot : Bye!!! ")
Now, let us test our chatbot and see how it responds.
Screenshots of conversation with Chatterbot:


Now if you want your chatbot to search Wikipedia, just type
“tell me about ****”

That was pretty cool, isn't it? Though the results were not precise at least we reached a milestone :)
Conclusion: The future of chatbots
The future of Chatbots is very bright. With so much advancement in the Artificial Intelligence sector, chatbots are the future with zero doubt. The current chatbot that we just built is obviously not the future I am talking about as this is just a stepping stone in chatbot building.
The future chatbot will not be just a Customer Support agent, it will be an advance assistant for both the business and consumer.
We as humans are not fond of doing repetitive boring tasks. So in the future companies will hire AI Chatbot for the tasks which are repetitive and don’t require creativity. With AI Chatbot taking over repetitive boring tasks, Companies will utilize their human resources for more creative tasks. With this, we can expect more amazing things coming up to us in the future.
Also, Human doesn’t like storing up contents (mugging up) in their mind. And today with the Internet they can leverage that part. So tasks that require storing the information (data) can be transferred to AI Chatbot.
Well, that's all for this article hope you guys have enjoyed reading this it, feel free to share your comments/thoughts/feedback in the comment section.
Please reach me out over LinkedIn for any query.

Thanks for reading!!!
Bio: Nagesh Singh Chauhan is a Big data developer at CirrusLabs. He has over 4 years of working experience in various sectors like Telecom, Analytics, Sales, Data Science having specialisation in various Big data components.
Original. Reposted with permission.
Related:
- Deep Learning for NLP: Creating a Chatbot with Keras!
- BERT is changing the NLP landscape
- Getting Started with Automated Text Summarization