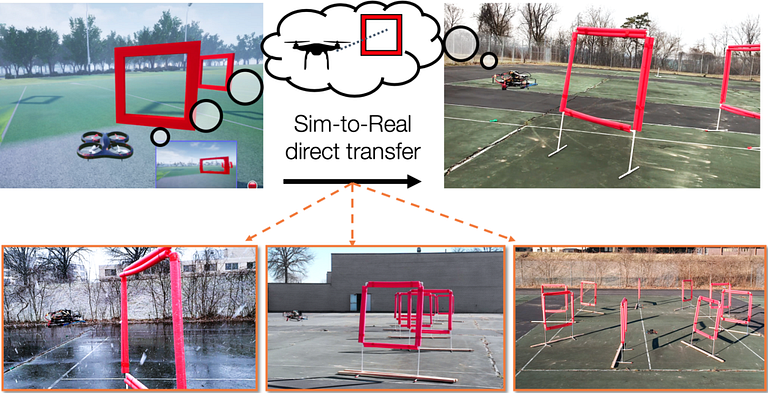
Microsoft Research Uses Transfer Learning to Train Real-World Autonomous Drones
The new research uses policies learned in simulations in real world drone environments.

Perception-Action loops are at the core of most our daily life activities. Subconsciously, our brains use sensory inputs to trigger specific motor actions in real time and this becomes a continuous activity that in all sorts of activities from playing sports to watching TV. In the context of artificial intelligence(AI), perception-action loops are the cornerstone of autonomous systems such as self-driving vehicles. While disciplines such as imitation learning or reinforcement learning have certainly made progress in this area, the current generation of autonomous systems are still nowhere near human skill in making those decisions directly from visual data. Recently, AI researchers from Microsoft published a paper proposing a transfer learning method to learn perception-action policies from in a simulated environment and apply the knowledge to fly an autonomous drone.
The challenge of learning which actions to take based on sensory input is not so much related to theory as to practical implementations. In recent years, methods like reinforcement learning and imitation learning have shown tremendous promise in this area but they remain constrained by the need of large amounts of difficult-to-collect labeled real world data. Simulated data, on the other hand, is easy to generate, but generally does not render safe behaviors in diverse real-life scenarios. Being able to learn policies in simulated environments and extrapolate the knowledge to real world environments remains one of the main challenges of autonomous systems. To advance research in this area, the AI community has created many benchmarks for real world autonomous systems. One of the most challenging is known as first person view drone racing.
The FPV Challenge
In first-person view(FPV) done racing, expert pilots are able to plan and control a quadrotor with high agility using a potentially noisy monocular camera feed, without comprising safety. The Microsoft Research team attempted to build an autonomous agent that can control a drone in FPV racing.
From the deep learning standpoint, one of the biggest challenges in the navigation task is the high dimensional nature and drastic variability of the input image data. Successfully solving the task requires a representation that is invariant to visual appearance and robust to the differences between simulation and reality. From that perspective, autonomous agents that can operate on environments such as FPV racing require to be trained in simulated data that learn policies that can be used in real world environments.
A lot of the research to solve challenges such as FPV racing has focused on augmenting a drone with all sorts of sensors that can help model the surrounding environment. Instead, the Microsoft Research team aimed to create a computational fabric, inspired by the function of a human brain, to map visual information directly to correct control actions. To prove that, Microsoft Research used a very basic quadrotor with a front facing camera. All processing is done fully onboard with a Nvidia TX2 computer, with 6 CPU cores and an integrated GPU. An off-the-shelf Intel T265 Tracking Camera provides odometry, and image processing uses the Tensorflow framework. The image sensor is a USB camera with 830 horizontal FOV, and we downsize the original images to dimension 128 x 72.

The Agent
The goal of the Microsoft Research team was to train an autonomous agent in a simulated environment and apply the learned policies to real world FPV racing. For the simulation data, Microsoft Research relied on AirSim, a high-fidelity simulator for drones, cars and other transportation vehicles. The data generated by AirSim was used during the training phase and then deployed the learned policy in the real world without any modification.
To bridge the simulation-reality gap, Microsoft Research relied on cross-modal learning that use both labeled and unlabeled simulated data as well as real world datasets. The idea is to train in high dimensional simulated data and learn a low-dimensional policy representation that can be used effectively in real world scenarios. To accomplish that, Microsoft Research leveraged the Cross-
Modal Variational Auto Encoder (CM-VAE) framework which uses an encoder-decoder pair for each data modality, while constricting all inputs and outputs to and from a single latent space. This method allows to incorporate both labeled and unlabeled data modalities into the training process of the latent variable.
Applying this technique to FPV environments requires different data modalities. The first data modality considered the raw unlabeled sensor input (FPV images), while the second characterized state information directly relevant for the task at hand. In the case of drone racing, the second modality corresponds to the relative pose of the next gate defined in the drone’s coordinate frame. Each data modality is processed by an encoder-decoder pair using the CM-VAE framework which allows the learning of low-dimensional polices.
The architecture of the autonomous FPV racing agent is composed of two main steps. The first step focuses on learning a latent state representation while the goals of the second step is to learn a control policy operating on this latent representation. The first component or control system architecture receives monocular camera images as input and encodes the relative pose of the next visible gate along with background features into a low-dimensional latent representation. This latent representation is then fed into a control network, which outputs a velocity command, later translated into actuator commands by the UAV’s flight controller
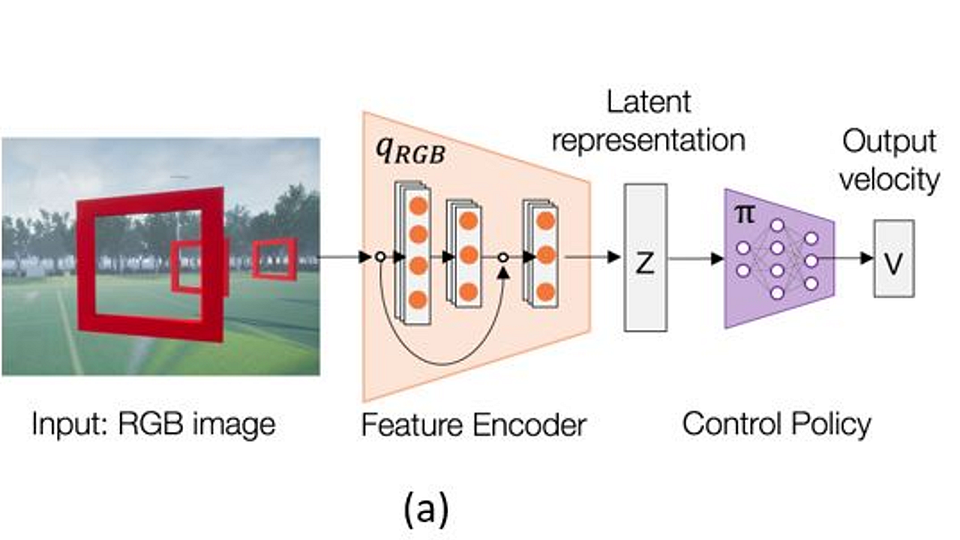
Dimensionality reduction is an important component of the Microsoft Research approach. In FPV racing, effective dimensionality reduction technique should be smooth, continuous and consistent and be robust to differences in visual information across both simulated and real images. To accomplish that, the architecture incorporates a CM-VAE method in which each data sample is encoded into a single latent space that can be decoded back into images, or transformed into another data modality such as the poses of gates relative to the UAV.

The resulting architecture provides was able to reduce high dimensional representations based on 27,468 variables to the most essential 10 variables. Despite only using 10 variables to encode images, the decoded images provided a rich description of what the drone can see ahead, including all possible gates sizes and locations, and different background information.

Microsoft Research tested the autonomous drone in all sorts of FPV racing environments including some with extreme visually-challenging conditions: a) indoors, with a blue floor containing red stripes with the same red tone as the gates, and Fig. 8 b-c) during heavy snows. The following video highlights how the autonomous drone was able to complete all challenges using lower dimensional image representations.
Even though the Microsoft Research work was specialized in FPV racing scenarios, the principles can be applied to many other perception-action scenarios. This type of technique can help to accelerate the development of autonomous agents that can be trained in simulated environments. To incentivize the research, Microsoft open sourced the code of the FPV agents in GitHub.
Original. Reposted with permission.
Related:
- Exploring TensorFlow Quantum, Google’s New Framework for Creating Quantum Machine Learning Models
- Microsoft Open Sources ZeRO and DeepSpeed: The Technologies Behind the Biggest Language Model in History
- The State of Transfer Learning in NLP