We Tuned 4 Classifiers on the Same Dataset: None Actually Improved
We tuned four classifiers on student performance data with proper nested cross-validation and statistical testing. The result? Tuning changed nothing.

Image by Author
# Introducing the Experiment
Hyperparameter tuning is often touted as a magic bullet for machine learning. The promise is simple: tweak some parameters for a few hours, run a grid search, and watch your model’s performance soar.
But does it actually work in practice?

Image by Author
We tested this premise on Portuguese student performance data using four different classifiers and rigorous statistical validation. Our approach utilized nested cross-validation (CV), robust preprocessing pipelines, and statistical significance testing — the whole nine yards.
The result? performance dropped by 0.0005. That is right — tuning actually made the results slightly worse, though the difference was not statistically significant.
However, this is not a failure story. It is something more valuable: evidence that in many cases, default settings work remarkably well. Sometimes the best move is knowing when to stop tuning and focus your efforts elsewhere.
Want to see the full experiment? Check out the complete Jupyter notebook with all code and analysis.
# Setting Up the Dataset

Image by Author
We used the dataset from StrataScratch’s “Student Performance Analysis” project. It contains records for 649 students with 30 features covering demographics, family background, social factors, and school-related information. The objective was to predict whether students pass their final Portuguese grade (a score of ≥ 10).
A critical decision in this setup was excluding the G1 and G2 grades. These are first- and second-period grades that correlate 0.83–0.92 with the final grade, G3. Including them makes prediction trivially easy and defeats the purpose of the experiment. We wanted to identify what predicts success beyond prior performance in the same course.
We used the pandas library to load and prepare the data:
# Load and prepare data
df = pd.read_csv('student-por.csv', sep=';')
# Create pass/fail target (grade >= 10)
PASS_THRESHOLD = 10
y = (df['G3'] >= PASS_THRESHOLD).astype(int)
# Exclude G1, G2, G3 to prevent data leakage
features_to_exclude = ['G1', 'G2', 'G3']
X = df.drop(columns=features_to_exclude)
The class distribution showed that 100 students failed (15.4%) while 549 passed (84.6%). Because the data is imbalanced, we optimized for the F1-score rather than simple accuracy.
# Evaluating the Classifiers
We selected four classifiers representing different learning approaches:
- logistic regression: Linear baseline
- random forest: Ensemble method
- XGBoost: Gradient boosting
- support vector machine (SVM): Kernel-based approach

Image by Author
Each model was initially run with default parameters, followed by tuning via grid search with 5-fold CV.
# Establishing a Robust Methodology
Many machine learning tutorials demonstrate impressive tuning results because they skip critical validation steps. We maintained a high standard to ensure our findings were reliable.
Our methodology included:
- No data leakage: All preprocessing was performed inside pipelines and fit only on training data
- Nested cross-validation: We used an inner loop for hyperparameter tuning and an outer loop for final evaluation
- Appropriate train/test split: We used an 80/20 split with stratification, keeping the test set separate until the end (i.e., no "peeking")
- Statistical validation: We applied McNemar's test to verify if the differences in performance were statistically significant
- Metric selection: We prioritized the F1-score for imbalanced classes rather than accuracy
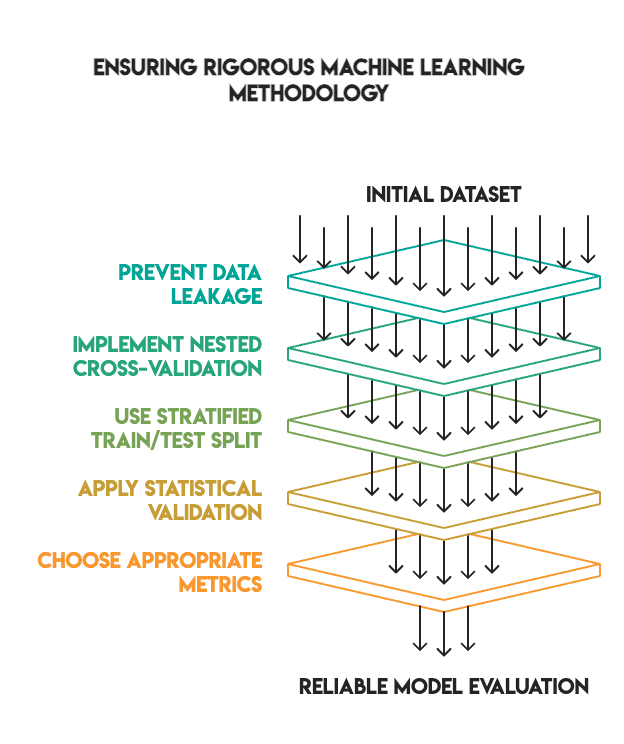
Image by Author
The pipeline structure was as follows:
# Preprocessing pipeline - fit only on training folds
numeric_transformer = Pipeline([
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())
])
categorical_transformer = Pipeline([
('imputer', SimpleImputer(strategy='most_frequent')),
('onehot', OneHotEncoder(handle_unknown='ignore'))
])
# Combine transformers
from sklearn.compose import ColumnTransformer
preprocessor = ColumnTransformer(transformers=[
('num', numeric_transformer, X.select_dtypes(include=['int64', 'float64']).columns),
('cat', categorical_transformer, X.select_dtypes(include=['object']).columns)
])
# Full pipeline with model
pipeline = Pipeline([
('preprocessor', preprocessor),
('classifier', model)
])
# Analyzing the Results
After completing the tuning process, the results were surprising:
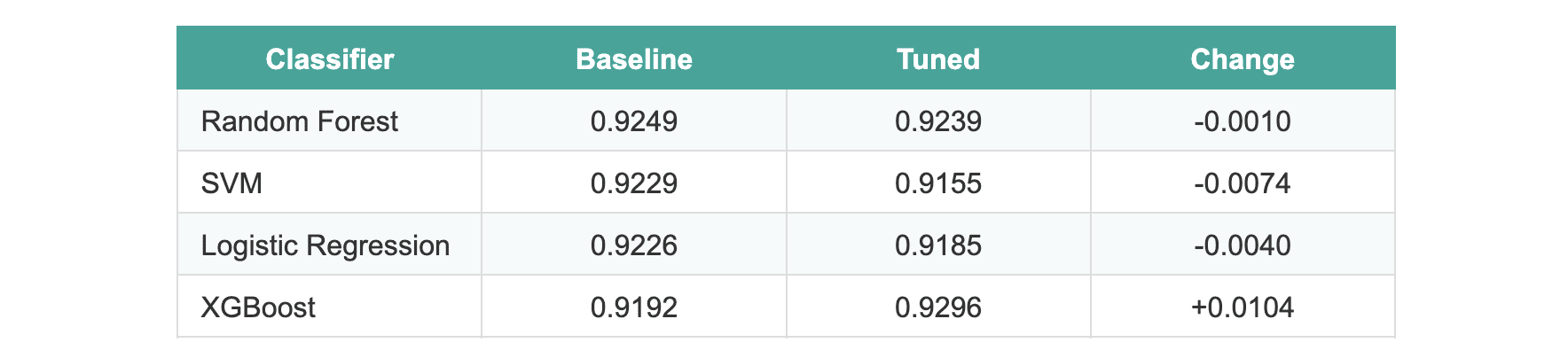
The average improvement across all models was -0.0005.
Three models actually performed slightly worse after tuning. XGBoost showed an improvement of approximately 1%, which appeared promising until we applied statistical tests. When evaluated on the hold-out test set, none of the models exhibited statistically significant differences.
We ran McNemar's test comparing the two best-performing models (random forest versus XGBoost). The p-value was 1.0, which translates to no significant difference between the default and tuned versions.
# Explaining Why Tuning Failed

Image by Author
Several factors explain these results:
- Strong defaults. scikit-learn and XGBoost ship with highly optimized default parameters. Library maintainers have refined these values over years to ensure they work effectively across a wide variety of datasets.
- Limited signal. After removing the G1 and G2 grades (which would have caused data leakage), the remaining features had less predictive power. There simply was not enough signal left for hyperparameter optimization to exploit.
- Small dataset size. With only 649 samples split into training folds, there was insufficient data for the grid search to identify truly meaningful patterns. Grid search requires substantial data to reliably distinguish between different parameter sets.
- Performance ceiling. Most baseline models already scored between 92–93% F1. There is naturally limited room for improvement without introducing better features or more data.
- Rigorous methodology. When you eliminate data leakage and utilize nested CV, the inflated improvements often seen in improper validation disappear.
# Learning From the Results
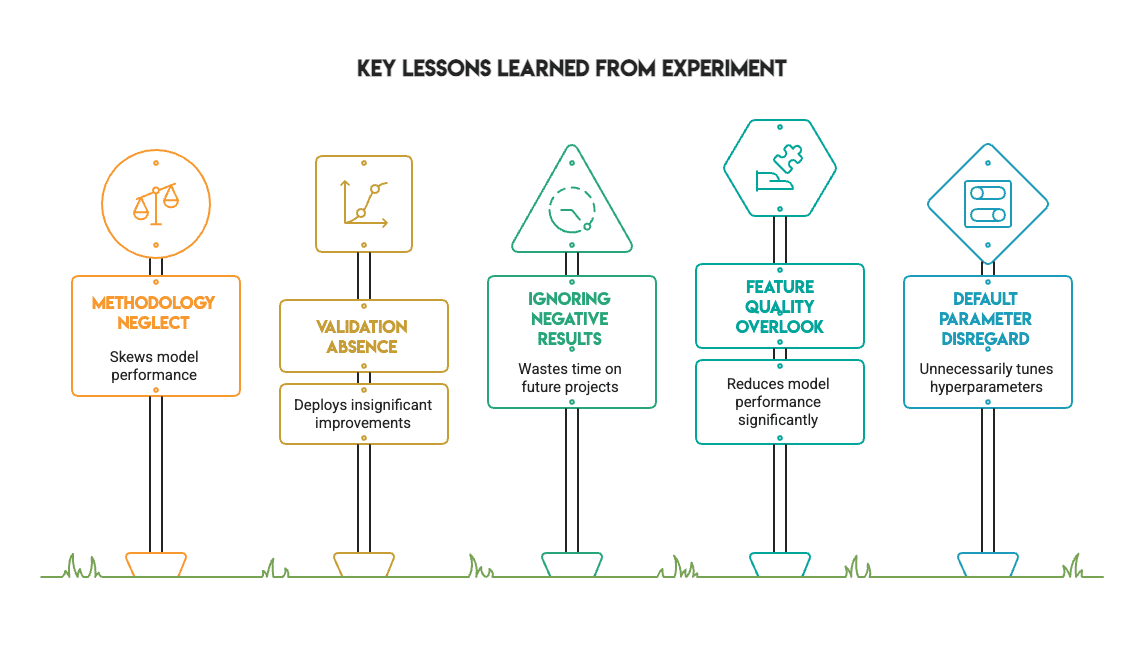
Image by Author
This experiment provides several valuable lessons for any practitioner:
- Methodology matters more than metrics. Fixing data leakage and using proper validation changes the outcome of an experiment. The impressive scores obtained from improper validation evaporate when the process is handled correctly.
- Statistical validation is essential. Without McNemar's test, we might have incorrectly deployed XGBoost based on a nominal 1% improvement. The test revealed this was merely noise.
- Negative results have immense value. Not every experiment needs to show a massive improvement. Knowing when tuning does not help saves time on future projects and is a sign of a mature workflow.
- Default hyperparameters are underrated. Defaults are often sufficient for standard datasets. Do not assume you need to tune every parameter from the start.
# Summarizing the Findings
We attempted to boost model performance through exhaustive hyperparameter tuning, following industry best practices and applying statistical validation across four distinct models.
The result: no statistically significant improvement.

Image by Author
This is *not* a failure. Instead, it represents the kind of honest results that allow you to make better choices in real-world project work. It tells you when to stop hyperparameter tuning and when to shift your focus toward other critical aspects, such as data quality, feature engineering, or gathering additional samples.
Machine learning is not about achieving the highest possible number through any means; it is about building models that you can trust. That trust stems from the methodological process used to build the model, not from chasing marginal gains. The hardest skill in machine learning is knowing when to stop.
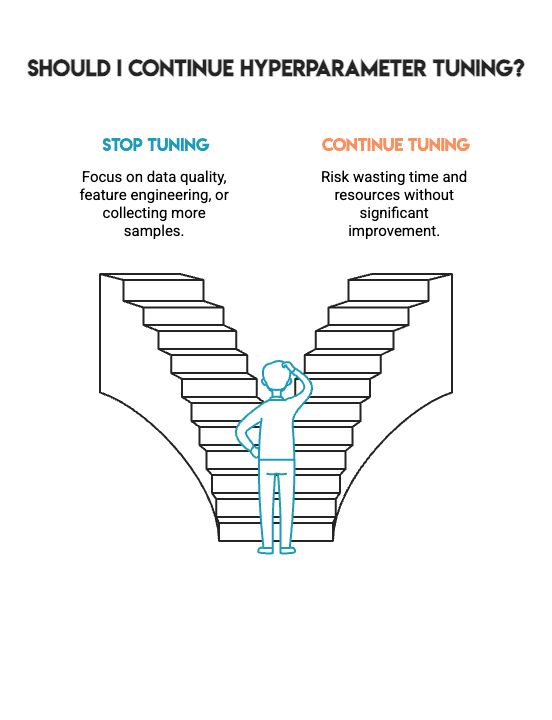
Image by Author
Nate Rosidi is a data scientist and in product strategy. He's also an adjunct professor teaching analytics, and is the founder of StrataScratch, a platform helping data scientists prepare for their interviews with real interview questions from top companies. Nate writes on the latest trends in the career market, gives interview advice, shares data science projects, and covers everything SQL.