10 Use Cases for Privacy-Preserving Synthetic Data
This article presents 10 use-cases for synthetic data, showing how enterprises today can use this artificially generated information to train machine learning models or share data externally without violating individuals' privacy.
By Elise Devaux, Statice
Fast-evolving data protection laws are constantly reshaping the data landscape. The organizational ability to overcome sensitive data usage restrictions while safeguarding customer privacy will be a key driver of tomorrow’s successful businesses. This blog presents ten concrete applications for privacy-preserving synthetic data that could help businesses maintain a competitive advantage:
- Cloud migration
- Internal data sharing
- Data retention
- Data analysis
- Data testing
- AI/ML model training
- 3rd party data sharing
- Product development
- Data monetization
- Data publication
With the appropriate privacy guarantees, privacy-preserving synthetic data is a type of anonymized data. Thus, it falls out of the scope of personal data protection laws. This, in turn, reduces for organizations the restrictions associated with the use of sensitive data while safeguarding individuals’ privacy. It’s particularly valuable in heavily regulated industries, as we’ll see through the following use-cases.
The lifecycle of value creation with synthetic data
More and more, data is becoming the central element driving value and growth within enterprises. In almost every data silo, and at every stage of the data lifecycle, enterprises have the ability to generate value. However, data hardly flows inside organizations, hindered by burdensome compliance and data governance processes. As a result, the use of synthetic data stretches along the data lifecycle. From data integration to data dissemination, it brings an alternative to leverage data.
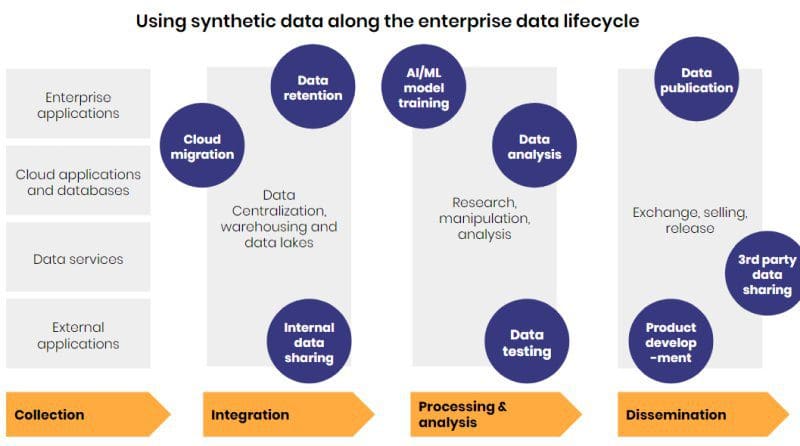
1. Cloud migration
Moving sensitive data to cloud infrastructures involve intricate compliance processes for enterprises. Assuring data safety, while guaranteeing its integrity for upcoming uses, can be time-intensive and costly, when possible at all. Because it embeds a privacy-by-design principle, Statice’s synthetic data allows enterprises to migrate samples, or complete data assets into cloud environments more easily. This saves time and money for enterprises that gain in data agility.
2. Internal data sharing
Privacy processes and internal controls slow down and sometimes prevent ideal data flows within organizations. Getting internal access to data can take weeks, or even longer when it is not clear which data points are required. The use of synthetic data samples, or complete datasets, liberates enterprises from the hurdles associated with getting sensitive data outside of a given silo. They can share internal sources and aggregate data faster, which in turn leads to a greater ability to leverage data.
3. Data retention
The regulation of data retention has been a hot topic in Europe in the last decade. Today, the GDPR insists upon limiting how long and how much personal data businesses store. Additionally, national laws often regulate the retention for data of a certain nature, such as telecommunications or banking information. The problem is that certain analyses require the storage of data for a longer period, infringing on such regulations. For example, annual seasonality analyses would require at least two years of data. In such cases, synthetic data offers a way to comply with data retention laws while enabling otherwise impossible long-term analysis.
4. Data testing
In test environments, lacking useful test data can slow down the development of new systems and prevent realistic testing. Here as well, synthetic data offers an alternative to production data. Because it mimics the statistical property of production data, synthetic data can be used to test new products and services, validate models or test performances. This resource is easily and quickly accessible, allowing for greater data agility and faster time-to-production in software development.
5. Data analysis
On one side, using partially masked data can impact the quality of analysis and presents strong re-identification risks. On the other side, getting systematic consent for secondary use of data is a tedious process, especially considering today’s volumes of data and the prevailing consumer sentiment toward data processing. Privacy-preserving synthetic data helps balance this privacy and utility dilemma. Enterprises can run analysis on synthetic data generated in a privacy-preserving way from customer data without privacy or quality concerns. In turn, this helps data-driven enterprises take better decisions.
6. AI/ML model training
With the same logic, finding significant volumes of compliant data to train machine learning models is a challenge in many industries. Using privacy-preserving synthetic data to power machine learning models can be a more scalable approach that also preserves data privacy. Multiple businesses already validated the use of privacy-preserving machine learning, producing meaningful results when building and training models with synthetic data. This an opportunity for enterprises to scale the use of machine learning and benefits in a secure way.
7. Product development
Data is an essential resource for product and service development. Once privacy-preserving synthetic data has been made available into an enterprise warehouse, engineers and data scientists can easily access and use it. Enterprises can create and make available data repositories that don’t represent a privacy breach, making resources available for product and service development. This in turn generates value for them as they are able to capitalize on their existing data to develop and innovate.
8. Data monetization
Packaging and selling data to third parties is now strongly regulated. Privacy-preserving synthetic data offers an opportunity to build revenue from data streams that are otherwise too sensitive to use for such purposes under normal circumstances. Organizations get to build new data-derived revenue streams at will, without risking individual privacy.
9. Data sharing
Exchanging data with third parties is part of what is driving enterprises’ innovation today. But whether to share analytics with clients, co-develop products with partners, or being able to send data to offshore sites, enterprises often struggle with the inherent challenges of sensitive data sharing. To avoid these time-consuming processes and increase their agility, enterprises can use privacy-preserving synthetic data.
10. Data publication
For enterprises hosting hackathons or seeking to share data with external stakeholders, it is crucial to ensure that no personal information is exposed. The infamous Netflix prize case illustrates the risks of releasing poorly anonymized data. With privacy-preserving synthetic data, enterprises have a guarantee of safeguarding the privacy of individuals.
In today’s highly regulated environment, enterprises must find ways of unlocking the value of data if they want to remain competitive. Privacy-preserving synthetic data is a safe and compliant alternative to the use of sensitive data that can give enterprises a significant competitive advantage. From internal data sharing to data monetization, enterprises can generate additional value, which can be decisive in competitive markets.
Bio: Elise Devaux (@elise_deux) is a tech enthusiast digital marketing manager, working at Statice, a startup specialized in synthetic data as a privacy-preserving solution.
Original. Reposted with permission.
Related:
- 10 Steps for Tackling Data Privacy and Security Laws in 2020
- Scikit-Learn & More for Synthetic Dataset Generation for Machine Learning
- Synthetic Data Generation: A must-have skill for new data scientists