 A step-by-step guide for creating an authentic data science portfolio project
A step-by-step guide for creating an authentic data science portfolio project
 A step-by-step guide for creating an authentic data science portfolio project
A step-by-step guide for creating an authentic data science portfolio projectEspecially if you are starting out launching yourself as a Data Scientist, you will want to first demonstrate your skills through interesting data science project ideas that you can implement and share. This step-by-step guide shows you how to do go through this process, with an original example that explores Germany’s biggest frequent flyer forum, Vielfliegertreff.
By Felix Vemmer, Operational Intelligence Data Analyst at N26.

As an inspiring data scientist, building interesting portfolio projects is key to showcase your skills. When I learned coding and data science as a business student through online courses, I disliked that datasets were made up of fake data or were solved before like Boston House Prices or the Titanic dataset on Kaggle.
In this blog post, I want to show you how I develop interesting data science project ideas and implement them step by step, such as exploring Germany’s biggest frequent flyer forum Vielfliegertreff. If you are short on time, feel free to skip to the conclusion TLDR.
Step 1: Choose your passion topic that is relevant
As a first step, I think about a potential project that fulfills the following three requirements to make it the most interesting and enjoyable:
- Solving my own problem or burning question.
- Connected to somerecent event to be relevant or especially interesting.
- Has not been solved or covered before.
As these ideas are still quite abstract, let me give you a rundown of how my three projects fulfilled the requirements:
Overview of my own data science portfolio projects fulfilling the three outlined requirements.
As a beginner, do not strive for perfection, but choose something you are genuinely curious about and write down all the questions you want to explore in your topic.
Step 2: Start scraping together your own dataset
Given that you followed my third requirement, there will be no dataset publicly available, and you will have to scrape data together yourself. Having scraped a couple of websites, there are 3 major frameworks I use for different scenarios:
Overview of the 3 major frameworks I use for scraping.
For Vielfliegertreff, I used scrapy as a framework for the following reasons:
- There was no JavaScript enabled elements that were hiding data.
- The website structure was complex, having to go from each forum subject, to all the threads and from all the treads to all post website pages. With scrapy you can easily implement complex logic yielding requests that lead to new callback functions in an organized way.
- There were quite a lot of posts, so crawling the entire forum will definitely take some time. Scrapy allows you to asynchronously scrape websites at an incredible speed.
To give you just an idea of how powerful scrapy is, I quickly benchmarked my MacBook Pro (13-inch, 2018, Four Thunderbolt 3 Ports) with a 2,3 GHz Quad-Core Intel Core i5 that was able to scrape around 3000 pages/minute:

Scrapy scraping benchmark. (Image by Author)
To be nice and not to get blocked, it is important that you scrape gently, by for example, enabling scrapy’s auto-throttle feature. Furthermore, I also saved all data to an SQL lite database via an items pipeline to avoid duplicates and turned on to log each URL request to make sure I do not put more load on the server if I stop and restart the scraping process.
Knowing how to scrape gives you the freedom to collect datasets by yourself and teaches you important concepts about how the internet works, what a request is, and the structure of HTML/XPath.
For my project, I ended up with 1.47 GB of data which was close to 1 million posts in the forum.
Step 3: Cleaning your dataset
With your own scraped messy dataset, the most challenging part of the portfolio project comes, where data scientists spend on average 60% of their time:
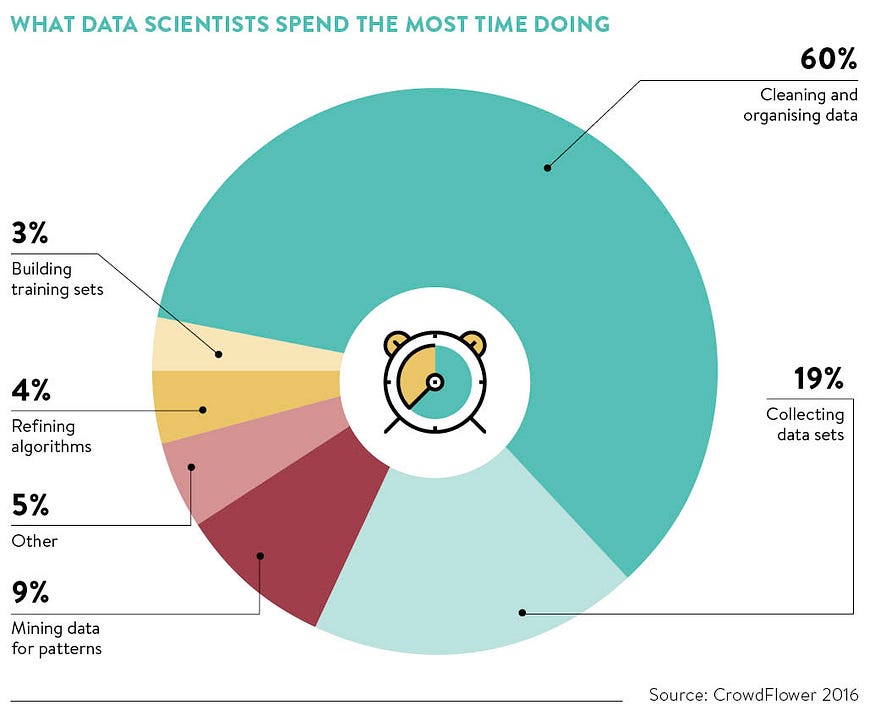
Image by CrowdFlower 2016.
Unlike clean Kaggle datasets, your own dataset allows you to build skills in data cleaning and show a future employer that you are ready to deal with messy real-life datasets. Additionally, you can explore and take advantage of the Python ecosystem by leveraging libraries that solve some common data cleaning tasks that others solved before.
For my dataset from Vielfliegertreff, there were a couple of common tasks like turning the dates into a pandas timestamps, converting numbers from strings into actual numeric data types, and cleaning a very messy HTML post text to something readable and usable for NLP tasks. While some tasks are a bit more complicated, I would like to share my top 3 favourite libraries that solved some of my common data cleaning problems:
- dateparser: Easily parse localized dates in almost any string formats commonly found on web pages.
- clean-text: Preprocess your scraped data with clean-text to create a normalized text representation. This one is also amazing to remove personally identifiable information, such as emails or phone numbers etc.
- fuzzywuzzy: Fuzzy string matching like a boss.
Step 4: Data Exploration and Analysis
When completing the Data Science Nanodegree on Udacity, I came across the Cross-Industry Standard Process for Data Mining (CRISP-DM), which I thought was quite an interesting framework to structure your work in a systematic way.
With our current flow, we implicitly followed the CRISP-DM for our project:
Expressing business understanding by coming up with the following questions in step 1:
- How is COVID-19 impacting online frequent flyer forums like Vielfliegertreff?
- What are some of the best posts in the forums?
- Who are the experts that I should follow as a new joiner?
- What are some of the worst or best things people say about airlines or airports?
And with the scraped data, we are now able to translate our initial business questions from above into specific data explanatory questions:
- How many posts are posted on a monthly basis? Did the posts decrease at the beginning of 2020 after COVID-19? Is there also some sort of indication that fewer people joined the platform not being able to travel?
- What are the top 10 number of posts by the number of likes?
- Who is posting the most and also receives, on average, the most likes for the post? These are the users I should regularly follow to see the best content.
- Could a sentiment analysis on every post in combination with named entity recognition to identify cities/airports/airlines lead to interesting positive or negative comments?
For the Vielfliegertreff project, one can definitely say that there has been a trend of declining posts over the years. With COVID-19, we can clearly see a rapid decrease in posts from January 2020 onwards when Europe was shutting down and closing borders, which also heavily affected travelling:
Posts created by month. (Chart by Author)
Also, user sign-ups have gone down over the years, and the forum seemed to see less and less of its rapid growth since the start in January 2009:
Sign up numbers of users over the months. (Chart by author)
Last but not least, I wanted to check what the most liked post was about. Unfortunately, it is in Germany, but it was indeed a very interesting post, where a German guy was allowed to spend some time on a US aircraft carrier and experienced a catapult take off in a C2 airplane. The post has some very nice pictures and interesting details. Feel free to check it out here if you can understand some German:

Sample picture from the most liked post on Vielfliegertreff (Image by fleckenmann).
Step 5: Share your work via a blog post or web app
Once you are done with those steps, you can go one step further and create a model that classifies or predicts certain data points. For this project, I did not attempt further to use machine learning in a specific way, although I had some interesting ideas about classifying the sentiment of posts in connection with certain airlines.
In another project, however, I modeled a price prediction algorithm that allows a user to get a price estimate for any type of tractor. The model was then deployed with the awesome streamlit framework, which can be found here (be patient with loading, as it might load a bit slower).
Another way to share your work is like me through blog posts on Medium, Hackernoon, KDNuggets, or other popular websites. When writing blog posts about portfolio projects or other topics, such as awesome interactive AI applications, I always try to make them as fun, visual, and interactive as possible. Here are some of my top tips:
- Include nice pictures for easy understanding and to break up some of the long text.
- Include interactive elements, like tweets or videos that let the user interact.
- Change boring tables or charts for interactive ones through tools and frameworks like airtable or plotly.
Conclusion & TLDR
Come up with a blog post idea that answers a burning question you had or solves your own problem. Ideally, the timing of the topic is relevant and has not been analysed by anyone else before. Based on your experience, website structure, and complexity, choose a framework that matches the scraping job best. During data cleaning, leverage existing libraries to solve painful data cleaning tasks like parsing timestamps or cleaning text. Finally, choose how you can best share your work. Both an interactive deployed model/dashboard or a well written medium blog post can differentiate you from other applicants on the journey to become a data scientist.
Original. Reposted with permission.
Bio: Felix Vemmer is a Data Analyst at N26 focusing on creating interesting data sets and projects through web scraping and machine learning.
Related: