Fraud through the eyes of a machine
Data structured as a network of relationships can be modeled as a graph, which can then help extract insights into the data through machine learning and rule-based approaches. While these graph representations provide a natural interface to transactional data for humans to appreciate, caution and context must be applied when leveraging machine-based interpretations of these connections.
By Jakub Karczewski, Machine Learning Engineer.
Context
There are many approaches to determining whether a particular transaction is fraudulent. From rule-based systems to machine learning models - each method tends to work best under certain conditions. Successful anti-fraud systems should reap the benefits of all the approaches and utilize them where they fit the problem best.
The notion of networks and connection analysis in the world of anti-fraud systems is paramount since it helps uncover hidden characteristics of transactions that are not retrievable any other way. In this blog post, we will try to shed some light on the way networks are created and then used to detect fraudulent transactions.
Networks in fraud detection
Let’s consider a transaction - one of the basic entities in the world of online payments. Each transaction can be described by a set of attributes. In Nethone, we gather over 5,000 data points per transaction, but for the sake of simplicity, let’s focus on a few common ones like:
- what are the characteristics of the payment (amount, card token),
- who initiated the transaction (name, email),
- on which device (IP address, device OS, browser cookies)
Having those exemplary transaction attributes in mind, we can now pass on to the stage of network building. The network (or graph) is a set of nodes (“dots”) connected by edges (“lines”). In the world of online payments, the nodes can be either transactions or specific values of transactions’ attributes. The edges can represent various relations but in this case, let’s focus on the most common one: sharing the attribute value. Let’s use this simple network as an example:
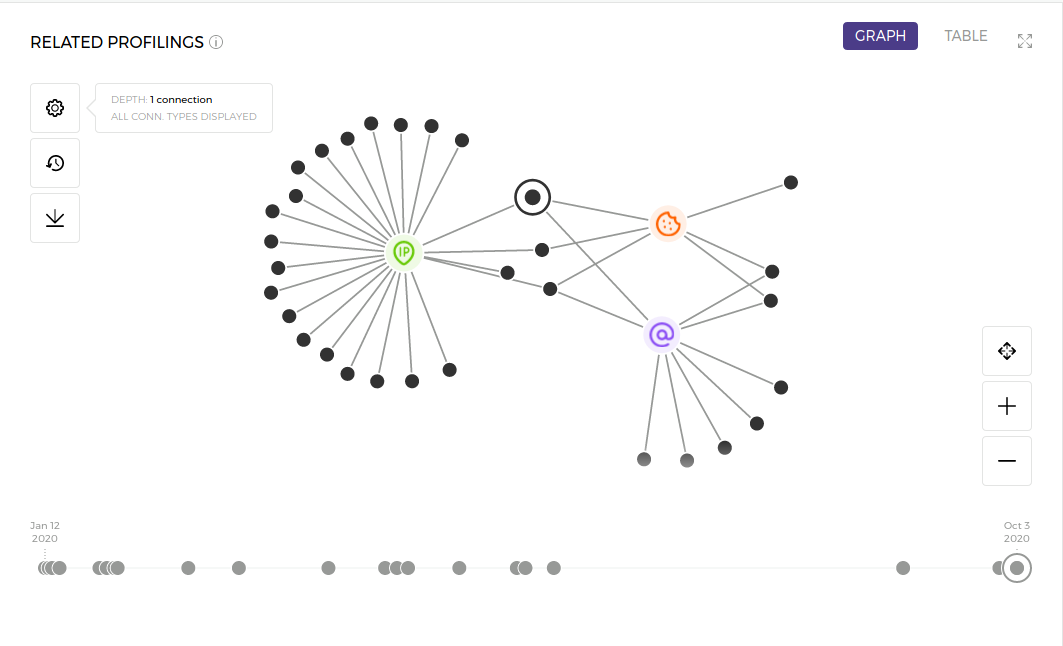
Fig. 1 - Simple network.
We can see that the processed transaction (“dot with halo”) shares an IP address (green node), email address (purple node), and cookie (orange node) value with several other transactions (black nodes). The procedure for creating such a network is pretty simple:
- Extract values of attributes of the processed transaction (like IP address, cookie, email, etc.).
- Find other transactions that share some of the attributes’ values.
- Plot them and connect to the processed transaction via intermediary nodes representing particular attribute values.
In short, it’s all about connecting transactions using some attribute as a matching key. This approach, although simple in principle, provides valuable context.
Once the graph is created, we can query it for various properties. We can check what the longest path is or how many nodes connect to a particular node representing, for example, IP address. After extracting the network's features, we can then feed them to rule-based systems or ML models - as mentioned in the beginning - as a hybrid approach works best.
Visualization of fraud attack
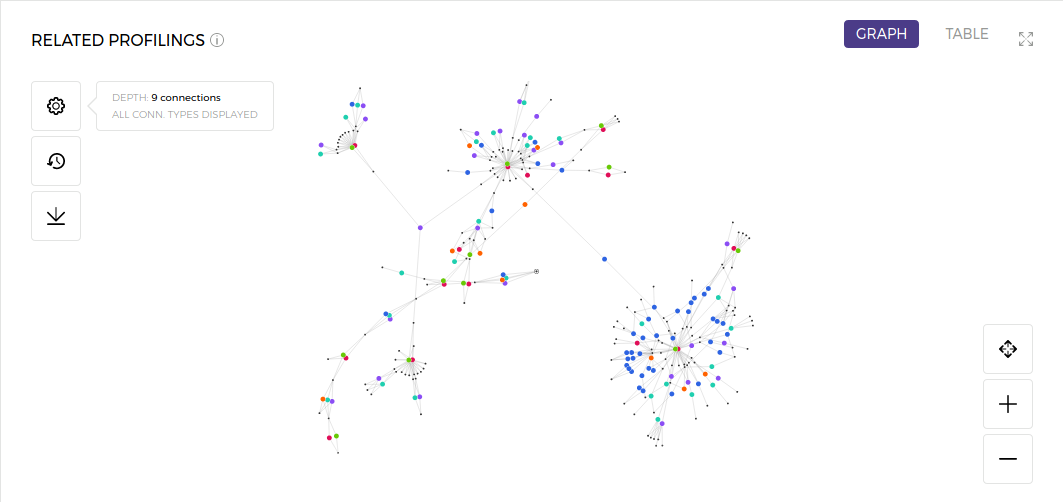
Fig. 2 - Extended network - carding scheme.
This network was constructed using a different seed transaction and expanded with an increased depth parameter. It means that now we can connect transactions related to the processed one - taking an analogy from the world of social interactions, we can analyze “friends of friends of friends… etc.” so transactions related to different related transactions. This way, we can broaden our scope and gather more insight. Let’s zoom in and look into some of the clusters.

Fig. 3 - Suspicious connections via card token.
At first glance, we can see that one email and IP address (red and green nodes) are connected to many different credit card tokens (blue nodes). Since it’s quite rare for people to possess a great number of credit cards, this type of network might be an example of carding fraud. In such attacks, fraudsters use stolen credit card credentials to perform numerous transactions. We can distinguish between normal traffic and carding patterns (few people, numerous cards, and transactions) easily when having data structured as a network. After querying our graph and encountering a risky pattern, we can add suspicious attribute values to blacklists. This way, if they are ever encountered by our system, transactions will be automatically flagged as risky.
Benefits and challenges of connection analysis
We can extract a lot of insight from connection analysis, but they don’t come for free - there are additional challenges as well. On the one hand, studying connections in networks built from transactional, tabular data might help us uncover relationships that are hard to extract when keeping the data flat. The structure of a network and how it changes in time can be a very rich source of information, as well as a human-friendly interface to our data.
On the other hand, there are no hard rules about what is and is not fraudulent behavior. If we can see multiple transactions coming out of a common IP address, then it can mean a fraud attack, but it can also mean employees using their corporate, proxied network to make purchases. It’s important to take as many factors in as possible - missing out on some may cause serious distortions in the way we perceive the data through our networks. A good example of a crucial factor is time - someone making a 10th transaction on the same day and cleaning browser cookies after each one will look exactly the same as a legitimate user making a 10th purchase in the same year, whose cookies naturally expire between consequent transactions.
Context is everything.
Original. Reposted with permission.
Related: