 The Rise of the Machine Learning Engineer
The Rise of the Machine Learning Engineer
 The Rise of the Machine Learning Engineer
The Rise of the Machine Learning EngineerThe evolution of Big Data into machine learning applications ushered in an exciting era of new roles and skillsets that became necessary to implement these technologies. With the Machine Learning Engineer being such a crucial component today, where the evolution of this field will take us tomorrow should be fascinating.
By Edward Bullen, Head of Data Engineering and Data Science at Telstra.

In the beginning — the Data Scientist
At the start of the 2010s, the hype around Big Data really took off. As the expectations around advanced analytics and analyzing unstructured data grew, the role of “Data Scientist” appeared on the upward slope of the Gartner hype-cycle (see figure below).
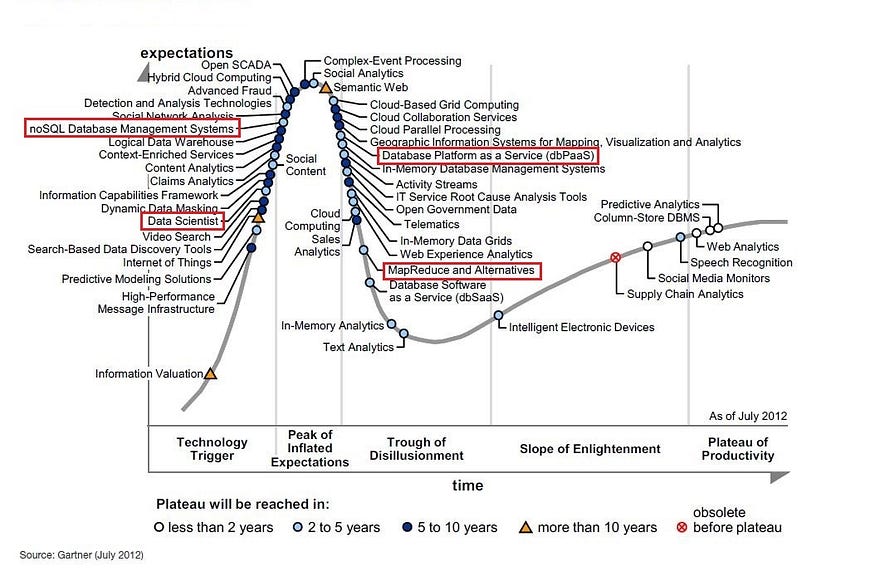
At the same time, challenges with implementing various important new data platforms referenced in the Gartner graphic were starting to become apparent (i.e., Map Reduce and other distributed systems and Database Platform as a Service), and these start to appear on the downward slope of the same Gartner hype-cycle. These platforms didn’t magically provide the Data Scientists with the data they required, and it became clear that a lot of design and engineering was required to align these data-platforms with what the Data Scientists needed. Also, a huge amount of hype and expectation was developing around NoSQL databases, but this mainly focused on the needs of web-scale applications and agile development rather than the needs of data analysis.
Where most people have got to — halfway there
This disconnect between the Data and the Analytics led to disillusionment, frustration, and inability to deliver many data science and analytics projects as the data part was missing.
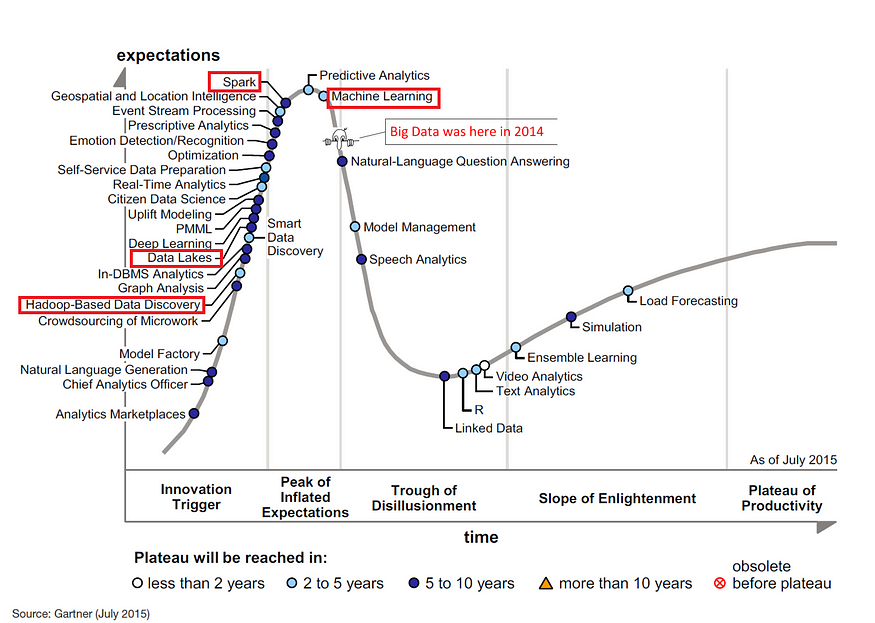
By 2015 Big Data had been dropped off the hype-cycle (i.e., see https://www.datasciencecentral.com/profiles/blogs/big-data-falls-off-the-hype-cycle), and the world of analytics and data science was pinning its hope on new data platform technologies such as Apache Spark and Data Lakes.
Enter the Data Engineer
As a result, the role of the Data Engineer was born, and demand for this position soared — by 2020, according to https://www.itjobswatch.co.uk/, 1.5% of all IT jobs in the UK were related to Data Engineering — to put this in perspective, 1.2% of all IT jobs were advertised for Web Development:
Interestingly at the same time, back in 2015, hopes and expectations for Machine Learning were judged to be at a peak. Machine Learning offered a way to put all this data to work.
A new problem to solve — how do we get this into production?

Heath Robinson’s pancake-making machine.
As the role of the data engineer matured and these experts got to work fixing all the data sourcing and processing problems for the data scientists, a new issue arose — how to get all those machine learning models deployed into production (i.e., get them running real parts of the business), now that the Data Scientists had access to the data they needed?
By 2019 the focus on Machine Learning had moved up a level and on to a whole separate Gartner Hype-Cycle with multiple types of machine learning and AI techniques and use-cases considered: https://twitter.com/kdnuggets/status/1234871536391245824
Enter the Machine Learning Engineer
To have a machine learning solution that is valuable to the business or research institute or NGO where it is deployed, it needs to:
- Integrate with live data sources
- Be reliable, robust, and accurate
- Actually be usable by other people — probably many other people and applications.
Ultimately a machine learning or “AI” solution is just a software product that applies algorithms or maths to some data.
To achieve an integrated robust and scalable software product, software source control and automated test frameworks for merging changes and updates into releases will be required. This allows a team of people to collaborate on a complete product that goes beyond a concept that is demonstrated by a data-scientist in a Jupyter (IPython) notebook.
Also, this needs to be underpinned by an architecture that can cater for hardware and network failures and scale to meet demand.
Finally, the nature of the domain means that the application will be heavily data-centric with more complex requirements in this area than the typical web application or transactional system. There are likely to be many bulk data aggregation requirements and complex data-feature engineering aspects, perhaps coupled with a high-volume data-streaming context.
To achieve this, someone must straddle the multiple disciplines of Data Architecture and Engineering, Data Science and Statistics and DevOps or Software Engineering — the role of Machine Learning Engineer is born:

A Machine Learning Engineer doesn’t just Build, they also Design.
With a hybrid knowledge across multiple domains, the machine learning engineer is a critical part of the design process, not just the implementation.
Often small compromises at the data science and modelling stage can lead to huge efficiencies at the data-layer. Also, understanding the context of the coding approach taken by the data scientist will help with translation into the production-code deployment. Conversely, being able to feed back the constraints of the code deployment platform and the data-processing platform to the data scientist in language that makes sense to the data scientist allows this to be factored into the analysis and modelling approach.
In this way, the introduction of the machine learning engineer breaks down the inter-disciplinary silos and finally leads to the promised land of a machine learning application delivering value from the data provided by the data engineer and analysed by the data scientist.
Original. Reposted with permission.
Related: