How to get started managing data quality with SQL and scale
Silent data quality issues are the biggest problem facing data teams today, who are flying blind with no systems or processes in place to monitor and detect bad data before it has a downstream impact.
By Tom Baeyens, CTO and Co-Founder, Soda.io
Why data management?
In the last three years I’ve transitioned from being a software engineer to a data engineer. I fell into the area of data management when Maarten Masschelein, my fellow co-founder at Soda, and I started working together to solve the problem of data issues that are silent and undetected. Coming from a software engineering background, writing unit tests and monitoring applications in production is a given but in data, it’s quite different. Whilst most organizations are aware they should test, there is no strategy in place and they just don’t know how to start addressing the problem which leaves their systems exposed and can result in serious downstream issues for the data products they are building.
With more and more products being built using data as the core input, it’s never been more important to test and monitor the quality of data being used. And so we set about building a data observability platform that enables organizations to discover, prioritize and resolve data issues.
Define good data quality
We started with Soda SQL, made available in February 2021. It’s our first open source data testing, monitoring and profiling tool for data-intensive environments. It works with your existing data engineering workflows to create a quick and easy way to define what good quality data means to your business. This enables data engineers to define tests and protect against the silent data issues that go undetected in datasets, data lakes, and data warehouses.
Open source to the rescue
Soda SQL is an open source tool with simple Command Line Interface (CLI) and Python library to test your data through metric collection. It utilizes YAML config files as input to prepare SQL queries that run tests on tables in a database to compute a wide range of metrics and tests. It's super easy to find invalid, missing, or unexpected data. Because Soda SQL leverages --you guessed it-- SQL, the data can stay where it is and existing compute engines can be leveraged.
If tests fail, Soda SQL allows you to stop the pipeline and prevent bad data from causing damage. As metrics are computed, diagnostic information is captured as well to help with the analysis if a data issue is detected. Steps can then be taken to prioritize and collaboratively resolve issues as one data team. Soda SQL can be used manually on its own or integrated with a data orchestration tool to schedule scans and automate actions based on scan results.
You can check out the 5-minute tutorial on how to get started but here’s a quick example:
- Simple metrics and tests can be configured in scan YAML configuration files. An example of the contents of such a file is as follows:

- Based on these configuration files, Soda SQL will scan your data each time new data arrived like this:

Bring everyone closer to the data
We have just released Soda Cloud, which is a web application where the Soda SQL metrics and test results can be monitored over time. Soda Cloud creates transparency from engineers to other people in the data team. With this collaboration data teams get ahead of the silent data issues. Soda Cloud extends Soda SQL and the two work together seamlessly.
First of all Soda Cloud extends Soda SQL with a metrics database so that measurements and test results can be visualized over time. This enables monitoring change over time and anomaly detection on all of the metrics.
These visualizations and data profiles already create transparency between different people in the larger data team. All people in the data team get to see what data is actually present, what tests are performed.
But the Soda Cloud goes one step further. It enables non-technical people to build and maintain their own monitors in a simple UI with a 3-step wizard. This is important because it removes the bottleneck to monitoring the domain knowledge that Subject Matter Experts have. If they don't need to involve data engineers to get their domain logic tested, that means a lot more of that domain knowledge will be used to define what good data looks like. And as a result, a lot more bad data will be captured preventing various kinds of damages.
Soda Cloud prescriptively solves the problem of discovering the silent data issues, by giving data teams a central platform to track and score the health of data across core quality dimensions.
Data and analytics engineers are equipped with a way to test data each and every time it transforms to ensure data pipelines are reliable. Via Soda SQL, data production can be stopped and quarantined. Soda Cloud visualizes the health of data sets and acts as a communication hub for data issues.
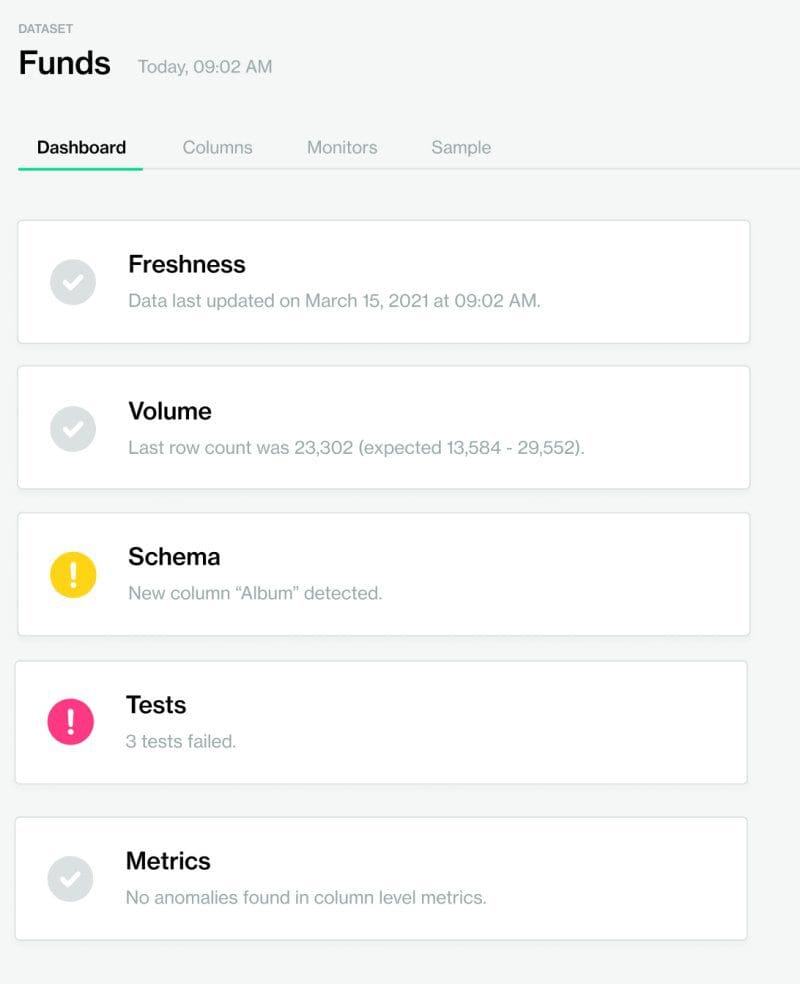
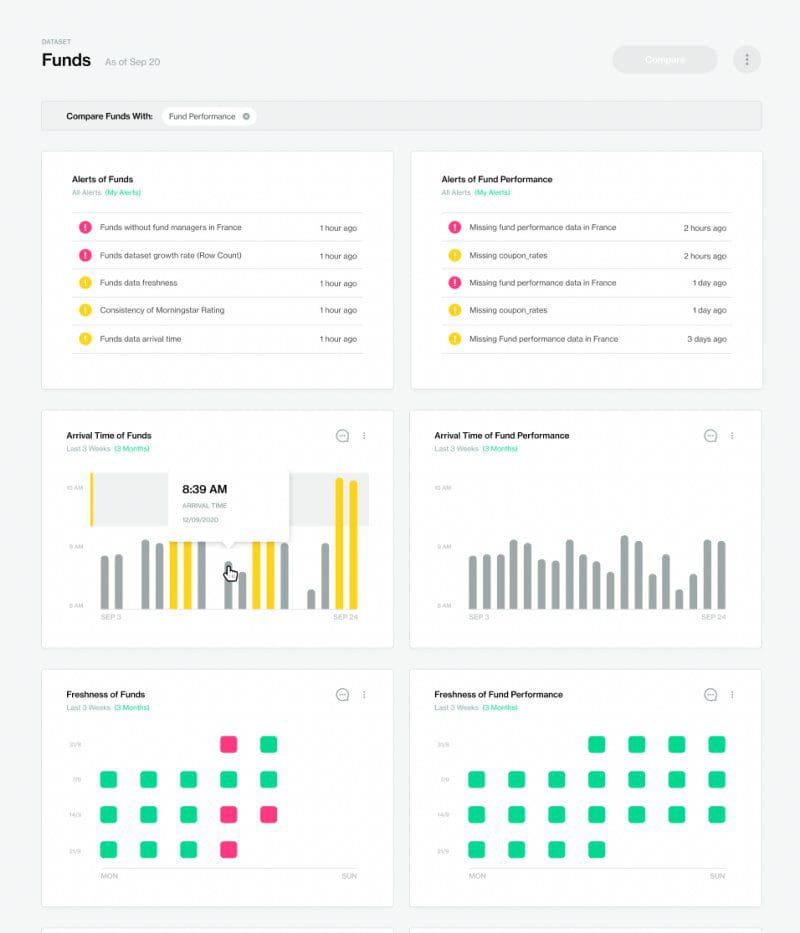
Data consumers and producers can now easily align on what’s important, what’s expected, and what to measure so that data remains fit for purpose. We’ve also built integrations with email and Slack to ensure the right people are alerted, at the right time to diagnose, prioritize and resolve the data issues.
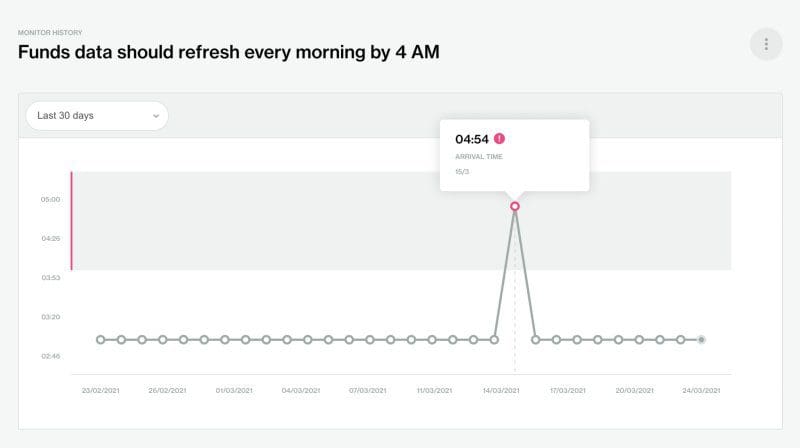
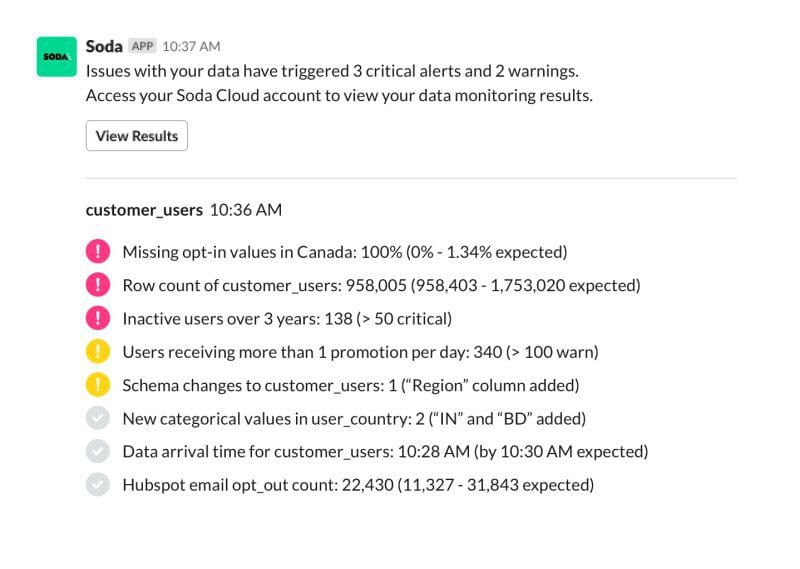
We’re on a mission to bring everyone closer to the data, as we believe that data quality is a team sport. Everyone who has a stake in the data (and we think that’s everyone in the business nowadays), needs to understand it, trust it, and stay on top of it.
My main responsibility at Soda is to ensure data engineers love using our products and help them solve real problems quickly. We help solve the problem with a combination of a cloud platform and a set of open source developer tools, that give data teams the configurability they need to create end-to-end observability.
Good quality data is for everyone. Access Soda SQL on GitHub and Soda Starter, our free trial, on Soda.io (extended to June 30, 2021). Our Slack Community and Docs contain best practices and helpful resources.
Get ahead of the silent data issues. Good luck!