Data Preparation and Raw Data in Machine Learning
In this article, I will describe the data preparation techniques for machine learning.
With the massive amounts of data available, analytics and machine learning (ML) are increasingly used to extract critical information that can be used for many different things.
For example, it is possible to automatically identify credit card fraud by studying how users interact with an eCommerce website. But this only works if all the relevant data has been prepared in a way that makes it amenable to machine learning algorithms.
In this article, I will describe the data preparation techniques for machine learning.
Raw Data
Raw data refers to the unprocessed, original data that is collected by computers. It is often very large in volume and complex to analyze.
In machine learning, raw data is typically collected from large groups of people or sensors that gather information about an object or event.
When combined with a specific type of algorithm, raw data can help computers predict events and make decisions without human involvement.
Data Preparation
Data preparation is the process of cleaning data, which includes removing irrelevant information and transforming the data into a desirable format. Data preparation is an essential step in the machine learning process because it allows the data to be used by the machine learning algorithms to create an accurate model or prediction.
In short, you need to collect some raw data, and then need to process it to make it understandable for ML Models.
Importance of Data Preparation
The type of data you use for your model greatly impacts the outcome of your model. If the data has small discrepancies or missing information, then it can have a great impact on your model's accuracy. Therefore, it is essential to have quality data that you can use to train your models.
In practice, researchers have found that 80% of the total data engineering effort is devoted to data preparation. As a result, the field of data mining has placed great emphasis on developing techniques for obtaining high-quality data. (Zhang, Shichao and Zhang, Chengqi and Yang, Qiang, 2003)
The data preparation is critical in three ways:
- Real-world data may be noisy or impure
- Elevated processing systems require accurate data
- Data integrity yields high-quality trends (Zhang, Shichao and Zhang, Chengqi and Yang, Qiang, 2003)
Moreover, data preparation produces a narrower dataset than the source, which can boost data collection performance dramatically.
Problems in the Raw Data
There may be many problems in the raw data such as noise, data redundancy, inconsistent data, heterogeneous data, etc. (Machine learning on big data: Opportunities and challenges, 2017). Some of them are explained below:
Data Redundancy
Duplication can happen when the same piece of data appears multiple times. The presence of duplicate data samples in your ML system, left unaddressed, can result in suboptimal performance.
Data redundancy is the result of having multiple sources of information that contain identical data. Data redundancy is not always an issue, but it can cause issues in several scenarios.
Noisy Data
Raw data can be noisy. Sometimes missing or incorrect values, or outliers, can skew the rest of your data. There are a number of challenges that come with noisy data. The traditional solutions don’t always work with big data. They aren’t scalable, and the advantages of big data can be lost if you apply simple solutions like mean, which doesn’t account for all the complexity of the data.
Incorrect or missing values caused by faulty sensors can be replaced by using predictive analysis.
Data Heterogeneity
Big data consists of lots of information, which includes text, audio, and video files. These files are stored in different places, and they are in a format that's easy to use. Since they are collected from lots of places (like cell phone videos on YouTube), they can give you different views on the same thing. These views are heterogeneous because they have been collected from people in different groups.
If you want to learn something new, experts say that it is best to get information coming from multiple sources at the same time.
Data Preparation Techniques
There are two data preparation techniques: Traditional and Machine Learning Techniques.
Traditional data pre-processing and preparation is labor-intensive, costly, and error-prone; machine learning (ML) algorithms can reduce this reliance by learning from massive, diverse, and real-time datasets. (Bhatnagar, Roheet, 2018)
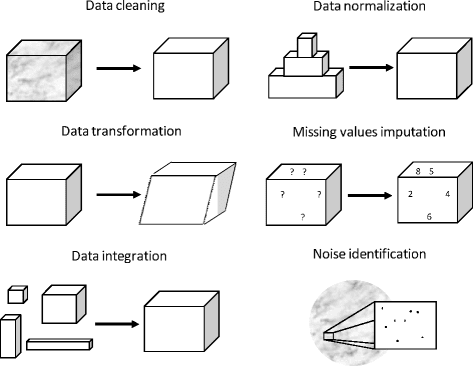
Figure 1 Tasks involved in Data Preparation (source (García, S., Ramírez-Gallego, S., Luengo, J., 2016))
ML Methods for Data Processing
Instance Reduction
To remove instances from large data sets, a process called instance reduction can be used. Instance reduction reduces the quantity of information by removing instances from data sets or by generating new ones. Instance reduction allows researchers to decrease the size of very large data sets without decreasing the knowledge and quality of information they can extract from them.
Imputation of Missing Values
There are different approaches to tackling the problem of missing values. First, we can discard instances that have missing values. But this is rarely beneficial because we are ignoring significant information. Another approach is to attribute the missing values. This is usually done using machine learning techniques that model the probability functions of the data set. Max-likelihood procedures can then be applied to find the best imputation model.
Paxata, Trifacta, Alteryx, Databricks, Qubole, and Google AI are some of the most powerful tools for data preparation.
Conclusion
Three common data preprocessing steps are
- Formatting: Arranging the Data in a desirable file format
- Cleaning: Removal of incomplete and inconsistent data
- Sampling: Taking small portions of data for fast processing
Navigating the world of data can be confusing for some, but hopefully, this guide has offered you a better understanding of the difference between raw and processed data. The first step in learning how to prepare your data will depend on what type of data you are using. However, making sure that your data is as accurate and clean as possible is important when it comes to modeling. Make sure to always keep these data preparation tips in mind while beginning any statistical project, whether simple or complex.
References
- Bhatnagar, Roheet. (2018). Machine Learning and Big Data Processing: A Technological Perspective and Review.
- García, S., Ramírez-Gallego, S., Luengo, J. (2016). Big data preprocessing: methods and prospects. Big Data Anal 1.
- Machine learning on big data: Opportunities and challenges. (2017). Neurocomputing, 350-361.
- Zhang, Shichao and Zhang, Chengqi and Yang, Qiang. (2003). Data Preparation for Data Mining. Applied Artificial Intelligence, 375-381.
Neeraj Agarwal is a founder of Algoscale, a data consulting company covering data engineering, applied AI, data science, and product engineering. He has over 9 years of experience in the field and has helped a wide range of organizations from start-ups to Fortune 100 companies ingest and store enormous amounts of raw data in order to translate it into actionable insights for better decision-making and faster business value.