Data Governance and Observability, Explained
Let’s dive in and understand the ins and outs of data observability and data governance - the two keys to a more robust data foundation.
Data governance and data observability are increasingly being adopted across organizations since they form the foundation of an elaborate yet easy to maneuver data pipeline. Two to three years ago, the objective of organizations was to create enough proof of concept to buy the client’s trust for AI-based products, and even a simple AI feature was a differentiating factor. It could easily give an edge over the competition.
However, in today’s landscape, AI-based features are the talk of the town and have become a necessity to stay in the competition. This is why organizations today focus on building a solid foundation so that data solutions are seamless and as efficient as the production of regular software.
So, let’s dive in and understand the ins and outs of data observability and data governance - the two keys to a more robust data foundation.
What is Data Observability?
Data Observability is a relatively new term, and it addresses the need to keep ever-growing data in check. With growing innovation and wide adoption across the corporate world, the tech stacks that host data solutions are becoming more efficient. Still, at the same time, they are also becoming more complex and elaborate, which makes them difficult to maintain.
The most common issue that organizations are facing is data downtime. Data downtime is the period during which the data is unreliable. It can be in terms of erroneous data, incomplete data, or data discrepancies across different sources. Without reliable data, there can be no hope for state-of-the-art solutions.
This is where data observability comes into the picture to make data maintenance manageable. This recent and growing need has led to the emerging field of observability engineering, which has three high-level components. In simple terms, these components are formats used by data observability to aggregate data:
- Metrics: Metrics are cumulative measures of data measured over a given time range.
- Logs: Logs are records of events that happened across different points in time.
- Traces: Traces are records of related events spread across a distributed environment.
Why is Data Observability necessary?
Data observability gives the added advantage of predicting data behavior and anomalies, which helps developers to set up resources and prepare in advance. Data observability’s key capability is to figure out the root cause or the reason that led to the recorded data performance. For instance, if the sensitivity score of a fraud detection model is relatively low, data observability will go deep into the data to analyze the why behind the relatively low score.
This capability is crucial because, unlike in regular software where most of the outcome is under the code’s control, in ML software, most of the outcome is beyond the solution’s control. This is because data is the independent factor that can even make the solution invalid with just one anomalous event. An example of such a data disruption will be the pandemic that disrupted employment rates, stock trends, voting behavior, and much more.
It is also highly likely that the solution that works consistently well on a given data group (say, data from a particular state) fails terribly on another data group.
Therefore, understanding the why behind the performances becomes the top priority while assessing the output of any data solution.
How is Data Observability different from Data Monitoring?
Observability is often referred to as Monitoring 2.0, but it is a much larger superset of monitoring. Observability works more like an engineer’s assistant to figure out if the system is working the way it was designed to by taking into account the deep underlying states of the system. Let’s go over a few points that differentiate observability from monitoring:
Context
Observability does not just track/monitor given pulses in the system. It also takes into account the context of those pulses that affect the functioning.
Depth
Monitoring tracks surface level pulses of the system to understand performance. In contrast, observability takes note of traces (or related events), makes the necessary links, and overall tracks the deep internal state of the system.
Action
While the output of monitoring is primarily numbers that reflect the performance or resource consumption of the system, the output of observability is action recommendation. For example, monitoring will point out that the system has consumed 100 GB of memory. In contrast, observability will state if the memory consumption has been sub-optimal and if the developer’s intervention is needed for optimization.
ML monitoring vs. ML observability
Observability has been a part of the DevOps framework for a long time. However, the need for it is increasingly evident in the MLOps community as well. Furthermore, as data gets more complex, data pipelines become more elaborate and challenging to track. So, while we integrate observability into the machine learning world, defining the critical differences between ML monitoring and ML observability is important.
The core elements of observability are reflected end to end in ML observability. ML monitoring just collects data on the solution’s high-level outputs or success metrics such as sensitivity and accuracy. After that, it sends alerts based on pre-programmed thresholds.
On the other hand, ML Observability delves deeper and looks for the reasons behind the recorded performance. Finally, it gets down to the root cause by evaluating the data behavior linking insights across validation, test, and incoming data.
The Pillars of Data Observability
Data observability is the sum of a few key features or pillars that run in parallel to improve data health:
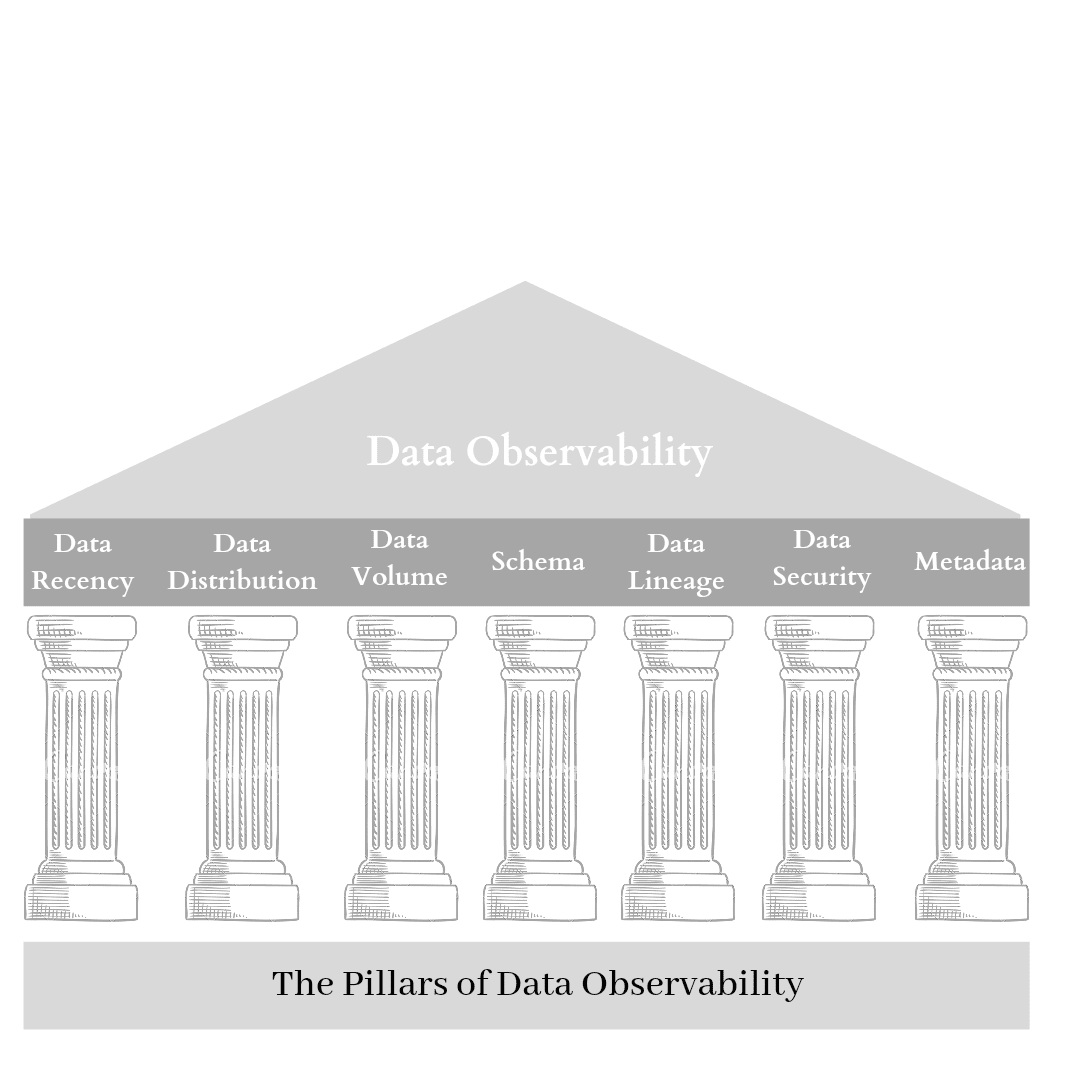
Fig 1: The Pillars of Data Observability | Image created by Author
Data Recency
As is widely known, any ML solution is only as good as the data. Therefore, it is crucial to ensure the data is fresh since old and irrelevant data is a burden to the organization’s resources, hardware, and workforce. Data observability seeks to provide the best route to update the data tables and also helps to decide the optimal frequency of updates.
Data Distribution
Data distribution is one of the most fundamental concepts of ML and is, therefore, highly regarded as one of the pillars of data observability. Data distribution is the way to understand if the data at hand is within the desired range. In other words, it is a way to check if the data sampling has been done right.
Data Volume
As the name suggests, data volume is nothing but a track of the volume of data with incoming and outgoing data transactions. Therefore, sudden rise or fall in the data volume should be tracked, and proper functioning of all the available data sources must be ensured.
Schema
The schema is the framework where the data is stored. Every data schema is accessed by multiple teams in any organization, each with a different level of access (edit, view, etc.). Therefore, changes to data are unavoidable and must be tracked with proper data versioning facilities in place. Factors such as who made the changes, when and why they made the changes should be accounted for. Also, simultaneous changes can lead to data discrepancies if the schema is not equipped to handle such cases.
Data lineage
Data lineage, in simple words, is the story of the data. It narrates how data went from point A to point B. Was it because of changes in incoming data sources, differences in data processing in the schema, or manual changes? A robust data lineage can answer such questions and more. The primary objective of tracking the data lineage is to know exactly where to attend if the data breaks. Since machine learning pipelines are complex due to the involvement of multiple experiments, experiment tracking tools and platforms come in extremely handy to understand the use and journey of data across several experiments, models, and data versions.
Data privacy and security
As discussed before, data access often varies across teams and individuals. Data security and privacy are some of the top indicators to ensure the health of the data. One rookie mistake in data updates or data in the wrong hands can disrupt the entire data lineage and can become a massive cost for the organization.
Metadata
Metadata is information on the data. Data observability being a superset of data monitoring, does not just look into the data to track down the root cause of disruptions, but it also observes the metadata to find trends in how the data changes. Metadata stores ensure that metadata from every critical ML stage is tracked and stored in an easily readable and accessible fashion to establish reliable and reproducible machine learning pipelines.
The pillars of data observability are vital while building and managing the foundations of the company’s data backbone.
How can a good data observability solution help your organization?
While selecting a data observability solution, the pillars of data observability must be kept in mind. A good solution can improve the health of the organization’s data ecosystem significantly. Some of the ways a good solution can help change the organization’s dynamics are:
Avoiding data issues proactively
Since data observability keeps track of changes in data behavior through metadata and performance checks, it can alert the ML engineers in advance to prevent a critical data situation by launching proactive fixes.
Assistance with mappings
A good data observability solution does not need to be told which indicators it needs to monitor. In fact, with the help of ML models, it aids in identifying the key indicators, dependencies, variables, incoming and outgoing resources. Metadata store and experiment tracking capabilities are necessary for maintaining mappings with high clarity.
Monitoring data-at-rest
Data-at-rest does not have to be loaded for data observability to monitor it. This saves huge costs by saving on resources like memory, processors, and of course, time. This also allows the data solution to become scalable without compromising performance.
Context
One of the key capabilities of data observability is to find the root cause by tracing and making apt connections between the data and the results. When you have an AI assistant that points out how a particular row is has an error and why, it brings context into the picture and enables speedy fixes in data issues.
Security
Security, one of the pillars of data observability, is naturally one of the key concerns since it can cause massive disruptions in data. Data observability, therefore, ensures optimal security and compliance.
Automatic configuration
A data observability solution uses ML models to assess the data, metadata, and the ML solution to figure out factors such as the environment, key metrics, and plausible crises like performance dropping below a particular threshold. Therefore, it eliminates the need to maintain and figure out complex rules that almost always change.
Easy fit
A good data observability solution is flexible and easily integrable into the pre-existing ML stack. Unless the ML-stack is poorly organized, the team need not make any changes or re-write the modules. This is good because it saves many resources. It also allows the advantage of evaluating different solutions and of finding the right fit quickly.
Data observability is a vast field, and the above points have only addressed the common concerns. So, for now, let’s dive into data governance to see how it fits into creating the picture-perfect data pipeline.
What is Data Governance?
Data governance is a set of standards and rules that strive to maintain data quality across the entire data pipeline. Since emerging technologies like AI and ML are heavily dependent on data which is an independent variable, it is crucial to certify the quality of the data.
It is important to note that data governance is not about data management but about building strategies and policies around optimal execution and assigning the right roles and responsibilities.
Benefits of data governance
In today’s ever-increasing competition among data solutions, data governance is a must-have. The benefits below will throw better light on why this is so:

Fig 2: Benefits of Data Governance | Image created by Author
End-to-end view
Data governance strives towards a single truth when it comes to data. However, data is often shared across various teams and stakeholders in newly evolving organizations without any tracking in place. This leads to multiple data versions resulting in data discrepancies and unsatisfied end-customers. A single source of truth with a 360-degree view for all teams is the key to resolving the above issues.
Better data quality
Data governance ensures that data is complete and the data sources are reliable. It also takes care of the correctness of data.
Data map
Multiple teams often access data that is used for a particular solution for other purposes. For instance, the consultation team might access the data dump to resolve an escalation. Therefore, to prevent any confusion, a consistent key is needed that can be referred to by all stakeholders or users.
Better data management
Data governance levels up the pre-existing data management methodologies by introducing the latest techniques and automation to drive efficiency and reduce errors.
Security
Data governance takes care of the data security concerns as well as resolves all compliance requirements. This leads to the least disruption in the end-to-end data pipeline since security concerns are major roadblocks and take very long to get resolved.
Data governance challenges
Data governance is a relatively new discipline, so organizations face a few common challenges during the initial setup stage. Some of them are:
Lack of business understanding
Data is often considered to be owned and managed entirely by the IT/dev team. This has a major flaw since the IT team does not have an end-to-end business perspective and cannot make the critical calls. Therefore, there are gaps during data gathering when the customer provides the necessary data or even when the data is collected from other sources.
With missing features that only a well-rounded business team can identify, the data is suboptimal. Unless the business understanding is integrated, there will also be considerable gaps when the stakeholders convey the results.
Inability to identify pain points
The job of data governance is to fix the problems in a data pipeline. However, if the actors cannot identify the priorities and pain points, data governance standards can take longer because of trial and error loops.
Lack of flexibility
Data management often requires multiple approvals for various actions. For example, while processing a client request, it can turn out that the client’s data will take up considerable space, which is over the available hardware limit. This kick-starts a chain of approvals across the hierarchy. Even though it is a simple process, it is inefficient because of the heavy impact on time.
Budget constraints
Data solutions often need elaborate resources like loads of memory and high processing power. Unfortunately, these resources can be off-limits to the team, especially in organizations where the data teams are still new and evolving. To make up for the lack of budget and resources, a subpar workaround has to be devised, affecting the data ecosystem’s health.
If we dive deeper, a lot of new and different challenges will be uncovered. Every organization has a different personality and faces a diverse range of challenges. The key is to get started and resolve the issues as they come.
Data governance tools
While considering which data governance tool to opt for, it is best to start with cost-efficient and quick options. Therefore, reliable open source solutions or cloud-based platforms that do heavy lifting are perfect for testing out the ground. The heavy lifting includes easy addition of new features, simple integration, instantly available hardware or server capabilities, and much more.
Let’s look into some of the points that you should consider while narrowing down on a data governance tool:
- Improves data quality: A data governance tool should clean, optimize and validate the data with no intervention.
- Manages data seamlessly: The tool should integrate efficient ETL (Extract Transform Load) processes such that the data lineage can be easily tracked.
- Documents the data: Documentation is the most underrated performer in any process, even when it retains and relays the most value to the team. Documenting data is necessary such that the reproducibility, searchability, access, relevance, and connections can improve.
- Has high transparency: The tool should provide high transparency to whoever is managing or using it. It should act like an assistant that aids the user in performing the tasks by clearly pointing out the tasks, communication points, and impact of inaction.
- Reviews data: Data, data trends, access points, and data health keeps changing and need to be closely monitored. Therefore periodic reviews can keep the data up to date and free from plausible breakdowns.
- Captures data: A data governance tool should automatically discover, identify, and capture key data points.
- Provides sensitive insights: A data governance tool should make sense of the data and ultimately provide key insights that can help frame the next steps in the data pipeline.
Overall, while selecting a data governance tool, ease of use should also be one of the primary concerns since high friction between the users and the tool will eventually slow down the processes.
15 data governance best practices
Even though the best practices are subjective and depend on the organization's present status, here are the top fifteen common data governance practices to get started:
- Get started: Take the first step and start small by building an incremental plan.
- Define goals: The incremental plan must have clear goals assigned not just to the participants of data governance but also to each process and stage. The objectives, of course, need to be realistic, attainable and launched in the right direction.
- Ensure accountability through ownership: Assigning goals is, however, not enough, and each actor of data governance needs to own processes and pledge their success. The best way to certify ownership could be to link performance KPIs with the processes.
- Emphasize team growth: For the team to progress and for the individual players to be at par with each other performance-wise across hierarchies, the high-level process owners should be directly responsible for the low-level process owners. This can again ignite accountability, teamwork, and, therefore, higher efficiency.
- Involve stakeholders: The insight of business stakeholders is of utmost importance to ensure that they contribute their bit without any vagueness or confusion. Therefore, it is best to educate them about the data governance architecture.
- Integrate business understanding: Understanding the business goals and the organization’s objectives is essential to building the organization’s data backbone. For example, is the company aiming for short-term success or long-term endurance? What are the compliance requirements binding on the company? What is the percentage of profits the company expects from its data solutions? Such data must be collected before strategizing the data governance policies.
- Fitting into the framework: Data governance must be sensibly integrated into the pre-existing framework and infrastructure of the organization. A major disruption is not recommended unless the organization is a startup and can afford to shuffle processes.
- Prioritize: There are tons of issues that will surface during the implementation of data governance. It should be the call of the leadership to identify the problems that need to be solved at the earliest and the ones that can wait.
- Standardize: Standardizing the data pipeline can be a costly process in the initial stages, but it is a massive cost-saver in the long term. Standardizing helps in various aspects, including removing data discrepancies, one-time data onboarding, fewer back and forths in communication, efficient use of available hardware, and much more.
- Define metrics: We get what we measure, and it holds even in the case of data governance. Identify the key metrics that can define the success and failure of the process, and choose the thresholds very carefully. Ensure that the metrics are directly related to the business KPIs and outcomes. This will help the business teams to understand the metrics better.
- Business proposal: Have a business proposal ready with the advantages and benefits that data governance can bring to the organization. Budget negotiations, top and bottom line objects, and saved time should be estimated and presented to the authorities.
- Seamless communication: Ensure seamless communication between teams since efficient communication is the key lever that runs every process. Often inter-team communications are complex since people are not sure whom to contact for a given purpose. Make sure that process owners are defined, and the assignments are highly transparent so that individuals can quickly figure out the point of contact.
- Ensure compliance: Pre-planned strategies that adhere to compliance rules are great for a smooth run. However, an unexpected compliance issue midway in a process can be complicated to deal with and will most definitely take a lot of time.
- Bring in Experts: A team of learners and experts is optimum to drive efficiency. Experts from external sources bring in additional knowledge of data governance from the industry, and the internal players collaborate with them to give a 360-degree view of the organization’s dynamics. The two types of knowledge, when combined, can inspire brilliant perspective and insights.
- Have a Plan B: Consider situations where a budget request is not approved, or a vital resource fails. Jot down the quickest and high-quality workarounds for situations like these.
Overall, it is important to remember that one size does not fit all. So, it is great to take note of the industry’s best practices, but it is not recommended to shy away from experimentation to find the practices that suit your organization and culture the most!
Final Thoughts
Data reliability is a growing concern because of the unending volume of data and the increasing number of unreliable sources. Therefore, data being the lead actor in the performance of ML solutions needs to have great vitality. Even state-of-the-art solutions can fail if good quality data is not backing them up.
Organizations have started to realize this after executing multiple POCs in data solutions during the first few years of the AI age. Unfortunately, the result was solutions that work well for a given set of data for a given time but soon fail and become irrelevant even with retraining. This is why developers want to understand the causes behind the failures, which can demonstrably happen through active monitoring and in-depth analysis.
Both data governance and data observability have therefore become vital in today’s fast-paced competitive environment. Even though they are relatively new disciplines, they intersect with some well-established fields such as cloud data architecture, virtual frameworks, machine learning, and more. The adoption rate across industries is set to bring them to the forefront very soon. Until then, let’s get to building the foundation for what is coming!
Reference
https://towardsdatascience.com/what-is-data-observability-40b337971e3e
https://www.montecarlodata.com/beyond-monitoring-the-rise-of-observability/
https://www.montecarlodata.com/the-26-things-your-data-observability-platform-must-do/
https://www.montecarlodata.com/the-new-rules-of-data-quality/
https://www.montecarlodata.com/data-observability-in-practice-using-sql-1/
https://www.montecarlodata.com/demystifying-data-observability/
https://www.montecarlodata.com/data-observability-the-next-frontier-of-data-engineering/
https://www.montecarlodata.com/what-is-data-observability/
https://www.eckerson.com/articles/data-observability-a-crucial-property-in-a-dataops-world
https://blog.layer.ai/experiment-tracking-in-machine-learning/
https://profisee.com/data-governance-what-why-how-who/
https://www.talend.com/resources/what-is-data-governance/
https://bi-survey.com/data-governance
Samadrita Ghosh is a Product Marketing Manager at Censius