Build a Reproducible and Maintainable Data Science Project: A Free Online Book
This free online book is a fantastic resource on how to structure, manage, and maintain your real-world data science projects.
Determining how to structure, manage, and maintain your data science project are a series of nontrivial tasks which, if performed properly, can go a long way towards making your life easier as your project unfolds and matures. Aiming to ensure reproducibility adds an additional layer of complexity and difficulty, but can help contribute to a project's longevity and credibility.
Where does one find comprehensive resources on practically ensuring the reproducibility and maintainability of data science projects?
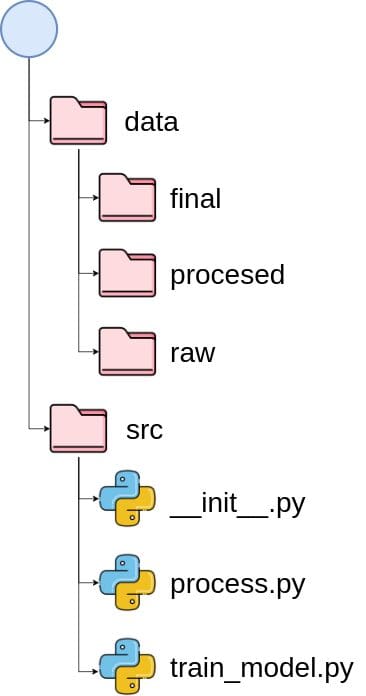
Python project file structure (source: Build a Reproducible and Maintainable Data Science Project by Khuyen Tran)
Khuyen Tran has put together a fantastic resource in the free online book titled, rather appropriately, Build a Reproducible and Maintainable Data Science Project.
This book introduces Python tools for developing efficient workflows for reproducible and maintainable data science projects. We introduce best practices and tools which enable data scientists to be able to adapt to the ever growing demand in complexity, while ensuring that their systems are reliable.
That all sounds great, you're thinking, but what does this really mean? To gain some insight into what is offered by the book, I suggest you take a quick look at section 2.1, How to Structure a Data Science Project for Readability and Transparency. You'll get a quick understanding of how the book is structured, what it will be covering, the manner in which it does so, and the appreciation Tran has for standards and best practices (and following them). You will find an easy to read, well-structured and informative resource awaits you.
Tran's book and the accompanying Data Science Cookie Cutter template lean on the following Python tools in order to accomplish its goals:
- Cookiecutter
- Poetry
- Git
- DVC
- Hydra
- Prefect
- pre-commit plugins
- pdoc
- and more
I'm a big fan of Poetry, so right off the bat I'm happy that Tran made the choice to use this in the project (NB: a pip version of the project does exists for those who prefer). Poetry is a masterful Python dependency management tool with numerous features above and beyond pip. You can find out more about Poetry here.
Importance is also placed on testing, configuration file management, project installation, data and model management, and code conformity and organization. In short, whatever, you should be doing to ensure your code is reproducible and maintainable, Tran covers in this book. Not only are the concepts and practice covered, however, the accompanying GitHub repository holds a project that helps perform the entire set of tasks.

Pre-commit tasks (source: Build a Reproducible and Maintainable Data Science Project by Khuyen Tran)
Ensure your code conforms to the PEP-8 style guide? Covered.
Version your datasets and store them online? Check.
Strip notebook outputs before commits? Yes.
Document your code as you go? You bet!
Tran's free online book is a useful resource for beginners and seasoned practitioners alike. Employing the methods found within will certainly improve the reliability of your code, the maintainability of your implementations, and the reproducibility of your projects, all while enabling increased complexity.
Don't let the aspects of your project that you can have complete control over — namely structure and implementation — be your undoing; follow the blueprint Tran lays out in this book to help ensure that you build a reproducible and maintainable data science project.
Matthew Mayo (@mattmayo13) is a Data Scientist and the Editor-in-Chief of KDnuggets, the seminal online Data Science and Machine Learning resource. His interests lie in natural language processing, algorithm design and optimization, unsupervised learning, neural networks, and automated approaches to machine learning. Matthew holds a Master's degree in computer science and a graduate diploma in data mining. He can be reached at editor1 at kdnuggets[dot]com.