Beyond Pipelines: Graphs as Scikit-Learn Metaestimators
Create manageable and scalable machine learning workflows with skdag.
Scikit-learn provides us with a flexible framework for defining machine learning (ML) tasks, but its support for composing those tasks into a larger workflow are often too limited for the messy world of production. skdag offers a more powerful task composition approach which allows you to get much more out of your machine learning tools.
The Scikit-Learn approach to machine learning is popular for a reason. It provides ML practitioners with a common language to describe and implement many tasks. Let’s briefly go over some key parts of that language:
- Estimator — an estimator is an object that takes in data and learns something from it in its
fit()method. - Transformer — a type of estimator that filters or modifies its input data in some way via its
transform()method. - Predictor — a type of estimator that derives some kind of inference from the input data, via the
predict()method. - Metaestimator — an estimator which takes one or more estimators as input parameters and does something with them. Metaestimators can be used for a range of tasks including hyperparameter optimisation (e.g.
GridSearchCV), model ensembling (e.g.StackingClassifier) or workflow composition (Pipeline).
The metaestimators for workflow composition focus on simplicity: simplicity of both the composition interface and of the composition itself. Here’s a quick example that creates a small pipeline:
The clear interface makes it easy to see what’s going on here. We start off by filling in any missing values in our input data with the feature mean, we then perform some SVD dimensionality reduction before training a random forest regressor to make some predictions. The beauty of the Pipeline metaestimator is that it can be treated as an estimator itself which just runs all of the relevant methods, quietly chaining together the inputs and outputs of each step:
Real-life problems are rarely solved with a model this simple though. Let’s take a deeper look at features in the diabetes dataset, which are used to predict a measure of disease progression after one year:
…age, sex, body mass index, average blood pressure, and six blood serum measurements
These features are quite varied. Does it really make sense to perform the exact same pre-processing on all of them? Probably not. Here’s how we can process some features differently using only what sklearn gives us:
To treat each feature differently we need to bring in a new estimator, ColumnTransformer, and start nesting things to get the desired behaviour of different imputation strategies, along with some SVD but only on the blood serum tests. Our code is rapidly becoming less readable and less manageable.
Replacing Pipelines with Graphs
Even this relatively small example shows that pipelines sacrifice too much flexibility in the name of simplicity. What we need is an approach that keeps our code simple but doesn’t force our workflows to be simple. Such an approach exists: directed acyclic graphs (DAGs).
Many production frameworks used by industry define ML workflows as DAGs for just these reasons, but they lack the tight integration with the scikit-learn API that can make pipelines so easy to use and also come with a lot of extra overhead, required for other things like delayed dependencies and distributed processing. These features are not needed for many of the use cases that scikit-learn excels at, such as small-scale experimentation and defining model architectures (which may then be run in some of the aforementioned frameworks). This is where skdag comes in (pip install skdag). skdag is a small extension for scikit-learn that implements DAG metaestimators. This allows it to go beyond pipelines and column transformers in several ways. Let’s demonstrate by recreating our previous workflow in skdag:
With the DAG approach, no matter how complex our workflow is the code will always be a simple list of steps, each one defining what its dependencies are. Dependencies can simply be a list of step names, or if we only wish to take certain columns from the output of a step, we can provide a dictionary of step name to columns. Another benefit of using skdag is that it allows you to easily visualise the workflow with dag.show() which can be very useful for verifying complex workflows do what we expect:
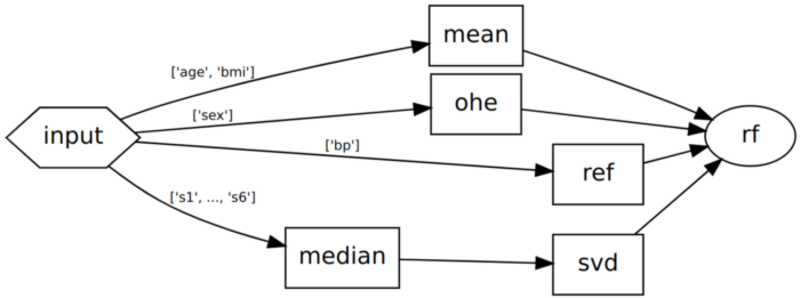
skdag-generated workflow visualisation.
Another benefit of using DAGs is the ability to understand dependencies better. In the above DAG, we can see that mean, ohe, ref and median don’t depend on one another so in theory there is no reason we couldn’t perform them all at the same time. One small change in our DAG creation allows us to do this in practice. Replacing make_dag() with make_dag(n_jobs=-1) will tell the DAG to run steps in parallel wherever possible.
Model Stacking
Let’s say we want to make our workflow even more complex. Instead of using a single random forest regressor to make our predictions, let’s use a diverse variety of models and then stack them together to create a final prediction. Model stacking is where we take the predictions from multiple models, and use them as inputs to a final meta-learner which is usually a very simple model that simply combines the results together, deciding how much weight to apply to each model.
Implementing stacking for our example in scikit-learn requires yet another metaestimator: the StackingRegressor. A DAG however can handle this pattern natively, so we simply need to include our stacking logic in the graph definition:
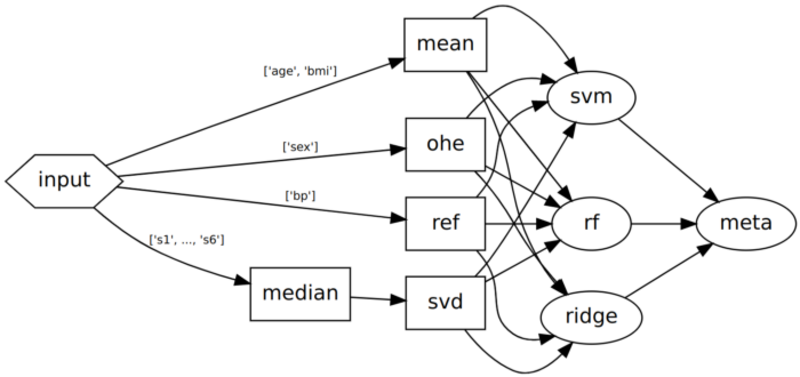
DAG for the stacked model. Note that unlike pipelines, skdag does not have any restriction on predictors appearing mid-workflow.
By adding a couple of simple, readable steps we have constructed a DAG that would be complex and difficult to maintain using only scikit-learn’s linear components.
Hopefully this small demo shows you the benefits of using DAGs instead of pipelines to create manageable, maintainable machine learning workflows — and that skdag will become another useful member of your toolkit!
Original. Reposted with permission.
Big O is a machine learning engineer and author of skdag. Big O works in the tech industry implementing machine learning solutions, specialising in human-machine interactions and recommender systems.