11 Questions About Data Engineers: What’s the profession about, and where’s it heading?
I hope my answers will be useful to novice data engineers and anyone interested in data engineering.
I switched to data engineering from development in 2017. Previously I had worked for ten years in desktop development, backend (mainly Java), and a little bit of frontend. Despite my strong IT experience, it wasn't easy at first to figure out what data engineers do, how they differ from database administrators, how they're connected to data analytics, and what they have to do with Big Data.
It was the magic of the phrase “Big Data” that determined what I'm doing now (this link provides a well-established definition of Big Data with the triad “Volume, Variety, Velocity” + an informative video from Amazon AWS). For me, the Big Data field looked like a challenge that I had to accept.
I became more interested in distributed systems, scalable technologies, and clouds, and went to conferences where relevant Big Data products like Hadoop, Kafka, Spark, etc. were analyzed. Colleagues who worked with Big Data appeared around me, and I flooded them with questions. Sometimes the answers I received weren't entirely clear, which further fueled my curiosity.

The first release of Hadoop — the first publicly available platform for storing and processing arrays of data from distributed sources, calculated in petabytes — took place in 2006. Soon, business began to consider Big Data to be something applicable in practice. Over the next decade, most business media called Big Data nothing less than a "revolution" and a "coup."
Yet over the last two or three years, the magical influence of Big Data has weakened: data engineering has actually absorbed and made this area commonplace, at least among IT specialists. Big Data is everywhere, and if business data is not Big today, it will become Big tomorrow. At the same time, attention to data professions has only grown, and they are in no less demand than, say, Java developers. Furthermore, data engineers earn more on average than backend developers (data scientists are valued even higher, and we'll understand why later in this article).
Today I see developers and other IT specialists around me who have the same questions about data engineering that I had 6-7 years ago. Here I've tried to answer the most popular ones, and in an accessible way. I don't pretend to be inclusive, and I understand perfectly well that other people have already written more fully and more interestingly about some aspects of the profession — that's why there are so many links in the text.
I hope my answers will be useful to novice data engineers and anyone interested in data engineering.
In a Nutshell: Who is a Data Engineer?
A data engineer is a person who makes data accessible to the customer. To do this, the data engineer understands exactly how to collect the necessary data, and sets up a process that may include:
- data collection: bank transactions, loyalty system registrations, customer geolocation, sensor readings on airplanes, etc.;
- clearing data from errors and repetitions — ensuring the required data quality;
- data transformation and aggregation;
- data storage;
- correct and fast delivery at the request of the customer.
The key concept here is a data warehouse: we upload data to it, transform it there, and unload it from there for analysis. As a rule, the storage is relational, but, unlike transactional database management systems, it is used for analytical loads (OLAP).
What does this mean? Transactional loads are characterized by relatively small portions of written data and reading, along with a potentially large number of users. With analytical loads, the situation is the opposite: there are large portions of written data and reading, along with a limited number of users. This is one of the nuances of the profession.
There are many options for modeling repositories, such as classical, Kimball or Inmon organization, or more modern methods, like Data Vault. There are also non-strictly relational storage options, such as Data Lake or Lakehouse — for them you need to build separate pipelines for data collection, and for their pre-formation and loading into storage.
The choice of storage, tools for working with data, data processing speed, and scaling capabilities are all the concern of a data engineer. The data administrator is usually the one responsible for ensuring that the configured pipeline works without interruptions for a month, a year and beyond. This person fixes problems and improves productivity. Most data engineers can do this too, but ideally it's not their responsibility.
How exactly the data will be used after being provided should also not, ideally, be the concern of a data engineer. The main thing is to adapt the storage to the daily load and type of data.
How is a Data Engineer Related to Data Analysts?
Remember, data engineers make data accessible. They collect data from various sources, systematize it, process it, and say: "Here's the data, who needs it — take it from here." For example, business users, such as managers, can take the data. But ideally, a data analyst would take the data first.
A data analyst's task is to interpret and visualize data, to figure out what business value can be extracted. Data analysts use patterns in data to answer business questions, make forecasts, and make recommendations. We can say that data analysts directly influence business decision-making.
Accordingly, data analysts set tasks for the data engineer, such as where to get the data for analysis, what to clean up, and what to correct. Sometimes a data engineer conducts the primary interpretation of data, and a data analyst prepares his or her own data. But often these powers do not overlap. Nevertheless, a highly qualified data analyst understands unstructured data, knows how to write complex SQL queries, and writes a little code in R or Python.
In general, a data engineer can be a bit of a data analyst, and vice versa. If the data analyst works only with Excel pivot tables, then he or she has nothing to do with data engineering.
How about Data Engineering vs. BI Engineers?
The focus of a BI engineer is reporting. For large clients, the BI engineer determines which BI tools to use, such as Tableau, Qlik, Power BI, Looker, Sisense, etc., and configures them. Thanks to a BI engineer, the company managers get a visual dashboard showing how things are going in the company in real time: it's clear within 10 seconds where the company's weaknesses are. If the manager wants, they can transform the report into a presentation.
And who will configure delivery of the necessary data to the BI system? That's right, a data engineer.
However, in small companies with a small data set — without a platform or a base platform such as MySQL or Oracle — the BI engineer configures the pipeline independently. In general, from the skills point of view, a BI engineer is a mix between a data engineer and a data analyst: this person understands the basics of data integration, processing, and data analysis, and can apply knowledge in practice.
On the other hand, almost any data engineer will build a dashboard in Tableau, for example, even though he or she does not have enough experience to know all the possibilities of even the most common BI systems. In addition, any system has a life cycle, including BI systems — they are evolving, and they need to be monitored and updated. A data engineer usually doesn't have time for this, but monitoring and updating the system is a priority for a BI engineer.
What do Data Engineers have in Common with Data Scientists?
In short, they have practically nothing in common, except that the data engineer (now you'll get deja vu) sets up a pipeline of data needed by the data scientist. The data scientist needs this data primarily for training models using neural networks and machine learning algorithms.
Models are used in business for forecasting and making automatic responses. For example, they can give an answer to a brokerage company to buy or sell Apple shares.
A data scientist's subject matter includes AI, ML, and DL. Even a senior data engineer rarely touches these things in his or her work. In addition to programming skills, data scientists must also have strong mathematical skills and knowledge of statistics.
So, a data engineer is a bit of a data administrator, a data analyst and a BI engineer. A data analyst, a BI engineer, and a data administrator can also be a bit of a data engineer. And data scientists are a separate universe: they have a different production cycle, a different theoretical base and qualification requirements.
What Abilities does a Data Engineer Trainee Need? How about a Junior?
I advise novice data engineers not to neglect the theoretical basis — relational algebra and distributed computing.
Beginners need to figure out what ETL and ELT are, and what the differencesare between them, besides a different order of the words Extract, Transform and Load. They need to understand the difference between SQL and NoSQL. They must get acquainted with the classes of data engineering tasks, and disassemble at the basic level at least one mainstream tool from each class:
- data storage;
- distributed data processing;
- orchestration.
It's also useful to know the software development lifecycle: how requirements are collected and documented, and how the software is developed, tested and implemented. Looking ahead, many data engineers write code and write autotests, in other words they get by without testers.
Data engineers communicate quite a lot with customers directly, bypassing business analysts. This is what's happening in my current project: the data engineers are independently translating tasks from the language of business into the language of technology. This means that right from the start there should be a common understanding of what data businesses need, and how banks, medicine, retail, telecom, insurance companies, and the tourism business use them. You can't get by without advanced soft skills and good spoken English. You'll need an English level no lower than Intermediate.
Where can I Find Information about Data Engineering?
To begin with, you can read the English-language blogs of the creators of technologies and tools for data engineering. In this article, most of the links just lead to blogs like MongoDB, Qlik, AWS, etc.
If you have already chosen a platform that you're going to master, it makes sense to look at the vendor's training materials. Such mainstream, self-sufficient platforms as Snowflake and Databricks have plenty of high-quality materials of various levels of complexity for beginners, middles, and architects. They do, of course, emphsize their own products.
Data engineers have their own bible — DMBOK (Data Management Body of Knowledge). Standardized data management methods and best practices are described here.
This serious and, perhaps, boring book is designed for the senior level and above. It is useful for beginners to use as a reference. DMBOK will highlight areas that are worth exploring — then you can go to the vendor blogs, where everything is described in a more fun and accessible way.
Does a Data Engineer need to be able to Program?
Many data engineers know how to write code. The vast majority of customers expect that the data engineer knows SQL and one of these languages perfectly, at least at the script level: Python, Scala, Java, JavaScript, C#.
Some of us use low-code platforms to assemble a data pipeline from ready-made tools (data integration tools). In this case, they are sometimes called ETL developers, Data Integration Engineers, or something else. Basically these people are also data engineers, just with a specialization in data integration.
They may not know some of the nuances of the profession. For example, if you need to increase productivity by 10 times, there will certainly be difficulties if you don't give a specific tool for scaling and say: "Do this."
In a word, you can be a data engineer even if you are only able to program at a minimum level. At the same time, a data engineer who knows only C# scripts can still reach a senior level and higher — just like a QA engineer who doesn't know how to program (unlike a QAA).
Where do People come from before they go into Data Engineering? Which Fields have it easiest when Becoming a Data Engineer?
I can only talk here about the experiences of my personal friends and colleagues, which doesn't necessarily reflect the situation in general. I've only rarely met people who entered the profession completely "from scratch" — most were developers or data specialists. Furthermore, I don't know of any cases where DevOps engineers migrated to data engineering. Perhaps they love their work more than other professions in IT on average, and are incredibly in demand at the same time.
Many data engineers started out as database administrators or data analysts. They already knew SQL, BI, and understood how to handle data. You can fully solve the tasks of a data engineer in a number of areas in just six months with a background like that.
I can assume that it's easier and faster to become a data engineer for a backend developer who knows Java and/or Python. If you know Scala, Airflow, or Spark then you're really in a good spot.
What's an Example of Working with the Customer? But a Simple One.
Almost all companies have databases that they work with from time to time: they upload something there, unload something else, and somehow use the database, depending on their needs. For example, a Python developer writes a platform, a business analyst and a marketer analyze data, and sometimes connect a system administrator. When it becomes clear that a systematic approach is needed and there's enough work for one whole person, then a data engineer is called for help.
They come to us and say: "We have our own database, but it can't withstand this load. We want a storage solution where we can put everything, and make big, heavy requests" (by the way, there are also reverse cases: there's not enough load on the storage space, and you need to figure out what to do with it).
Alright, we understand that the data needs to be transferred to internal storage and made available. To make the permissible load higher, you need to scale. We clarify the nuances: do we need to validate the data, or do they come to us clean? How often do we need to update/process data — is it enough to do so once a day, or is the process continuous? There may be dozens of similar requirements.
After collecting the requirements, we proceed to system design. We show how we will solve the problem technologically, with which stack. Sometimes the customer isn't sure about their decision — in this case we show alternative options, and describe the pros and cons of each. It happens that the customer is ready to go beyond the designated budget if they see an option that is more useful for business.
We must be understandable to business, and speak its language. If the customer is technologically savvy, and understands perfectly well how Data Warehouse differs from Data Lake, then we give more technical details. If not, we focus on fundamental things: how much it costs, how secure the storage is, and how easy it is to switch to another vendor's solution.
We'll definitely talk about how we'll act in emergency situations, and how long such a response will take.
What does a Data Engineer's the Career Track Look Like? Where can one Grow?
As in almost any profession, growth can be either expansive (growing out), or within (greater depth). You can master one stack so much that you will be perceived as a demigod, go on a bow and ask to set something up, when no one else can figure it out. You can also pump up your managerial skills, become a team leader, etc.
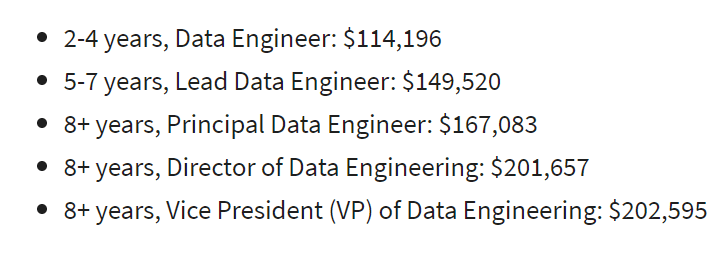
Career track of a data engineer in the USA, according to Glassdoor
The ways in which a data engineer develops, along with the list of requirements made of tthe data engineer, varies from company to company. In my company the career ladder looks like this: Data Engineer ? Team Lead Data Engineer ? Data Technical Architect ? Data Solutions Architect (DSA).
Data Engineer. Knows the basics of data management: data modeling, ELT/ETL, data quality, data warehouse/lake models, distributed systems. Confidently works with at least one stack: AWS, Azure, Snowflake, Apache Hadoop, etc. SQL is required, plus at least one language: Scala, Python, Java, C#.
Team Lead Data Engineer. This person knows the basics of data management and engineering at a high level. Strong communication and problem-solving skills. Knows how to manage projects, deliveries and changes.
Data Technical Architect. As a rule, this is a person who aspires to a DSA position, but lacks experience and technological erudition. He or she knows at least one stack well, and can work out the technical details of the solution implementation under the guidance of the DSA.
Data Solutions Architect. An expert in data management and data engineering. This person knows the current technologies of working with data at the architect level, and can quickly master new technologies. This person has leadership, project and change management skills, plus engineering management,such as team and technical department management.
Large IT companies often create competence centers for the development of hard and soft skills. For example, there are now almost 200 data specialists in DataArt, of which several people are in the Center of Excellence (including me). Our main goal is to help colleagues choose the direction in which they want to grow professionally, and help them master new technologies. We give data specialists the opportunity to reach full potential as a mentor, speaker, technical expert, and customer service specialist.
How is the Profession Changing? What are the Trends?
It seems to me that more and more attention is being paid to data management, or Data Governance. Previously, a company could dump data into Data Lakes, which eventually turned into "swamps of data": some incomprehensible data, where it's difficult to figure out who put what, and why. Now, at the architecture level, this company considers data management from different points of view, and describes how to ensure Data Quality, and how to deal with metadata, master data, and reference data, etc. This is much more difficult than building, say, an ETL pipeline.
One of the trends is the transition to cloud managed systems. That is, we do not deploy a system at home, but buy a ready-made one, assembled in the cloud. We can have a pool of requests for at least 10 thousand machines, but we don't need to think at all about how everything is distributed and scaled there.
Such a serverless trend is a very significant thing for data engineering. Due to that, Big Data loses its magical charm because Big Data is primarily about horizontal scaling. Thanks to the clouds, the focus of data engineers is shifting from scaling to data management. Conceptually, the more correct query now is not how to work with big data, but how to manage data in general.
The number of technologies is inflated, and there are more and more analogues of different tools. It is almost impossible to find a specialist with a 100% match on the technical stack. This means, for example, that a data engineer of any level has to acquire the necessary knowledge in practice, and this is normal.
Ilya Moshkov is a Senior Data Engineer and a member of DataArt's Data Center of Excellence