
Image by author
TF-IDF. You’re probably read blogs and seen this word being thrown here and there. Or you’re probably currently learning about it in Machine Learning. This article is an overview of what TF-IDF is.
What Does TF-IDF Mean?
TF-IDF stands for term frequency-inverse document frequency.
TF-IDF is typically used in the machine learning world and information retrieval.
TF-IDF is a numerical statistic that measures the importance of string representations such as words, phrases and more in a corpus (document).
Let’s break the abbreviation up and go into further understanding.
What is a Corpus?
When it comes to the art of language or Natural Language Processing in machine learning, a corpus is a collection of text or audio which has been organized into a dataset.

Sarah Mae via Unsplash
Let’s take this picture of this poem on a piece of paper for example. The corpus of this poem in a code format would look like this:
corpus = [
"Little feet.",
"A tempered foot,",
"found new ground.",
"A future unravled,",
"in the gypsy's palm.",
"A blade of grass",
"reflected in a crystal ball,",
"somehow fit the mold.",
"This daughter was leaving home.",
"A dark hair twitched, upon the mole.",
"From maiden to mother to crone",
"the moon takes us,",
"each month",
"a new spell.",
"an untold dimension.",
"Flattery fell in the folding of wings,",
"an angel over a city,",
"an orb, over the sea.",
"somehow, Seattle spoke to me."
]
Mathematical Definition
This is the mathematical equation to define TF IDF:
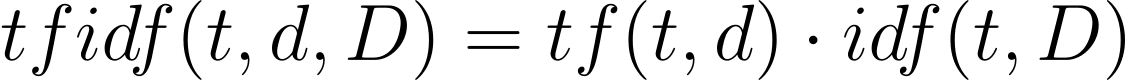
- t stands for term
- d stands for document
- D stands for set of documents
Term Frequency (TF)
TF is term frequency. It measures exactly what it says - the frequency of a particular term. The number of times a particular term is available in a corpus can help us to measure the importance of that string.
You can measure the frequency in the following ways:
- Raw count - You could do a raw count by counting manually how many times a word appears in the corpus.
- Boolean frequency - a Boolean data type is when there are two possible values - true/false, yes/no, 0/1. You can use 1 if the term occurs or 0 if the term does not occur
- Logarithmic scale - by using and displaying numerical data over a range of values.
Mathematical equation for TF:
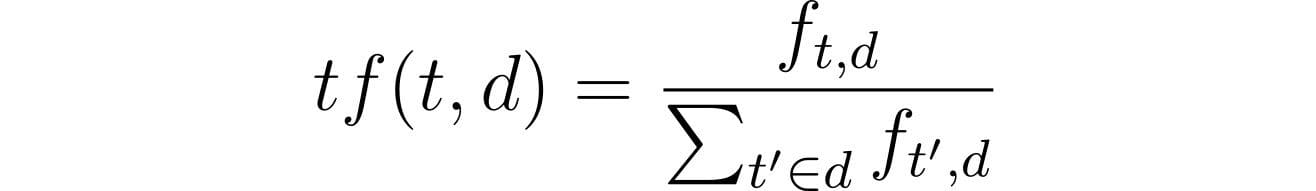
- t stands for term
- f stands for frequency
- d stands for document
Inverse Document Frequency (IDF)
IDF is inverse document frequency. This goes further into looking at how common a word is found in a corpus - or how uncommon a word is found in a corpus.
IDF is important. Let’s take the English language for example, words such as “the”, “it”, “as”, “or” which appear frequently in many types of documents. Inverse document frequency essentially minimizes the weight of frequency terms such as those and puts terms which are not as frequent at the forefront to have a higher impact.
Mathematical equation for IDF:
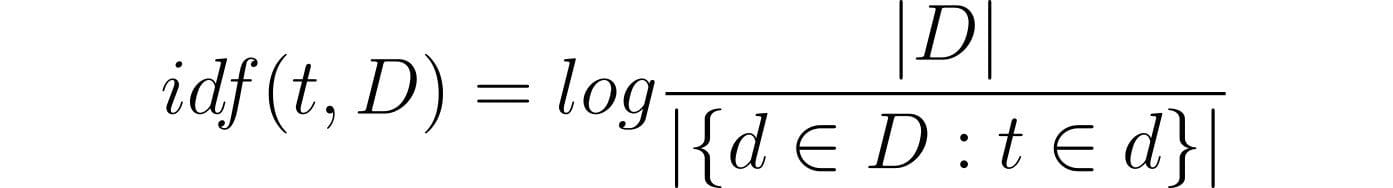
- t stands for term
- d stands for document
- D stands for set of documents
For IDF, you’re probably asking these questions:
1. Why do we take the inverse?
This is because we want to give the words that are uncommon a higher value in comparison to the words that are much more common.. If we did not take the inverses, common words such as “the” would have a higher value and we would never really find which terms in the corpus hold importance.
2. Why do we use logarithmic scale?
It is important to note that we are not focusing on the occurrence of a term in a corpus, it is the relevance and/or importance of that term in the corpus. Adding to the term frequency is essentially a sub-linear function, therefore using the logarithmic scale allows us to put these terms in the same scale or sub-linear function as the term frequency.
The Importance of TF-IDF
Techniques in the Natural Language Processing world have been developing, and although TF IDF was first recognized in the 1970’s - it still holds relevance in 2022.
TF-IDF sounds simple in comparison to NLP techniques and tools that are being used today. But just because it’s simple does not mean that it does not hold value and does what it needs to do. TD-IDF can be used to better understand and interpret the outputs of algorithms that have been used on top of TF-IDF. There’s no harm in using more than one measure.
TF-IDF has also been known to solve major drawbacks from popular language processing techniques such as of Bag of words
Oh, and another reason: it’s quick, easy, and accessible.
Conclusion
TF-IDF is a great starting point when it comes to language processing tasks, from building search engines to information retrieval. Although it is a simple measure, it still holds its intuitive approach to measuring the weight and relevance of words in a corpus.
Nisha Arya is a Data Scientist and Freelance Technical Writer. She is particularly interested in providing Data Science career advice or tutorials and theory based knowledge around Data Science. She also wishes to explore the different ways Artificial Intelligence is/can benefit the longevity of human life. A keen learner, seeking to broaden her tech knowledge and writing skills, whilst helping guide others.