
What is Chebychev’s Theorem and How Does it Apply to Data Science?
Chebyshev’s Theorem applies to every data set and is heavily used by Statisticians, Data Scientists, and Machine Learning Engineers.

Image by Author
What is the Empirical Rule?
Before we start to learn about Chebychev’s theorem, it will be useful to have a good understanding of the Empirical rule.
The Empirical rule tells you where most of the values lie in a normal distribution. It states that:
- around 68% of the data lie within 1 standard deviation of the mean
- around 95% of the data lie within 2 standard deviations of the mean
- around 99.7% of the data lie within 3 standard deviations of the mean
However, you can never be 100% sure that the distribution of data will follow a normal bell curve. When you’re working with datasets, you should always ask if your data is skewed. This is where Chebychev’s theorem comes into play.
What is Chebychev's Theorem?
Chebyshev’s Theorem was proven by Russian mathematician Pafnuty Chebyshev and typically referred to as Chebyshev’s Inequality. It can be applied to any dataset, specifically ones that have a wide range of probability distributions that do not follow the normal distribution we all want.
In Layman’s terms, it states that only a certain percentage of observations can be more than a certain distance from the mean.
For Chebychev’s Theorem, it states that when using any numerical dataset:
- A minimum of 3/4 of the data lie within 2 standard deviations of the mean
- A minimum of 8/9 of the data lie within 3 standard deviations of the mean
- 1−1 ∕ k2 of the data lies within k standard deviations of the mean
The word ‘a minimum’ is used because the theorem gives the minimum proportion of data that lies within a given number of standard deviations of the mean.
The image below visually shows you the difference between the Empirical Rule and Chebyshev’s Theorem:
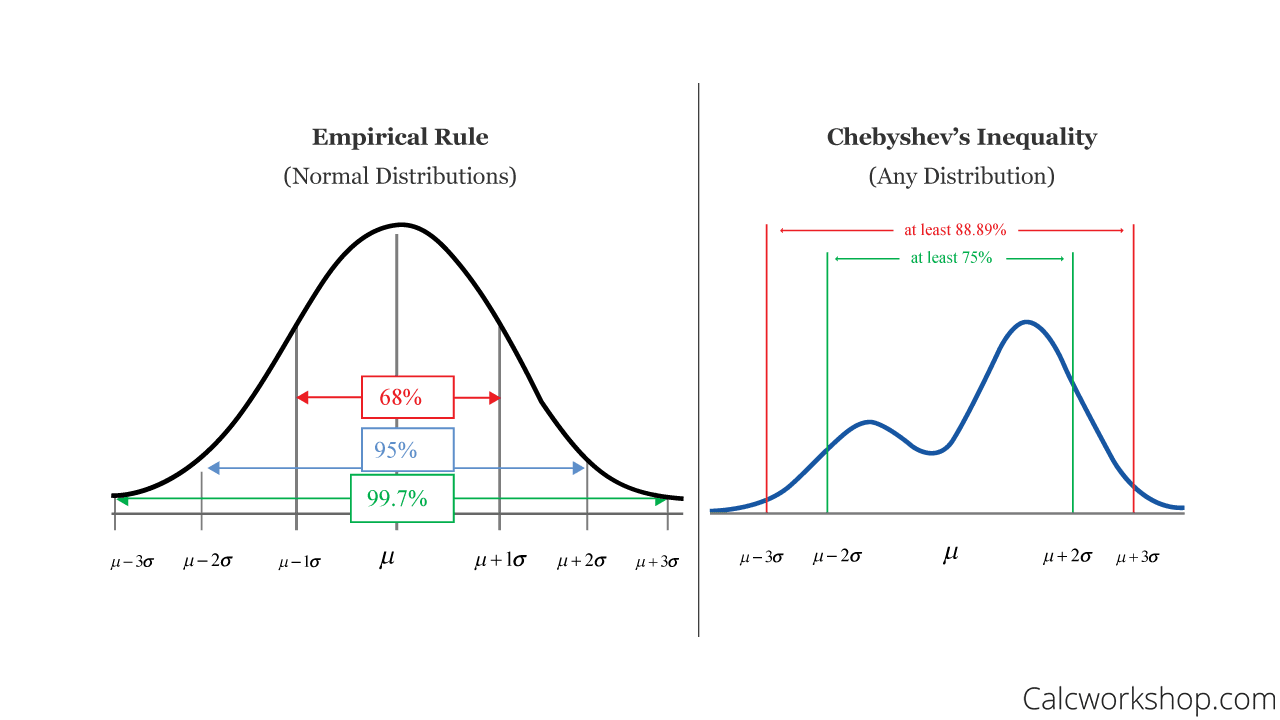
Source: calcworkshop
The equation for Chebyshev’s Theorem:
There are two ways of presenting Chebyshev’s theorem:
X is a random variable
μ is the mean
σ is the standard deviation
k>0 is a positive number
- P(|X - μ| ≥ kσ) ≤ 1 / k2
The equation states that the probability that X falls more than k standard deviations away from the mean is at most 1/k2. This can also be written like this:
- P(|X - μ| ≤ kσ) ≥ 1 - 1 / k2
Chebyshev’s Theorem implies that it is very unlikely that a random variable will be far from the mean. Therefore, the k-value we use is the limit we set for the number of standard deviations away from the mean.
Chebyshev’s theorem can be used when k >1
So How Does it Apply to Data Science?
In Data Science, you use a lot of statistical measures to learn more about the dataset you are working with. The mean calculates the central tendency of a data set, however, this does not tell us enough about the dataset.
As a Data Scientist, you will be wondering to learn more about the dispersion of the data. And in order to figure this out will need to measure the standard deviation, which represents the difference between each value and the mean. When you have the mean and the standard deviation, you can learn a lot about a dataset.
The more variance we have, the more spread the distribution of data points is away from the mean, and the lower the variance, the less spread the distribution of data points is away from the mean.
If a random variable has low variance, then the observed values will be grouped close to the mean. As shown in the image below, this results in a smaller standard deviation. However, if your distribution of data has a large variance, then your observations will naturally be more spread out and further away from the mean. As shown in the image below, this results in a larger standard deviation.
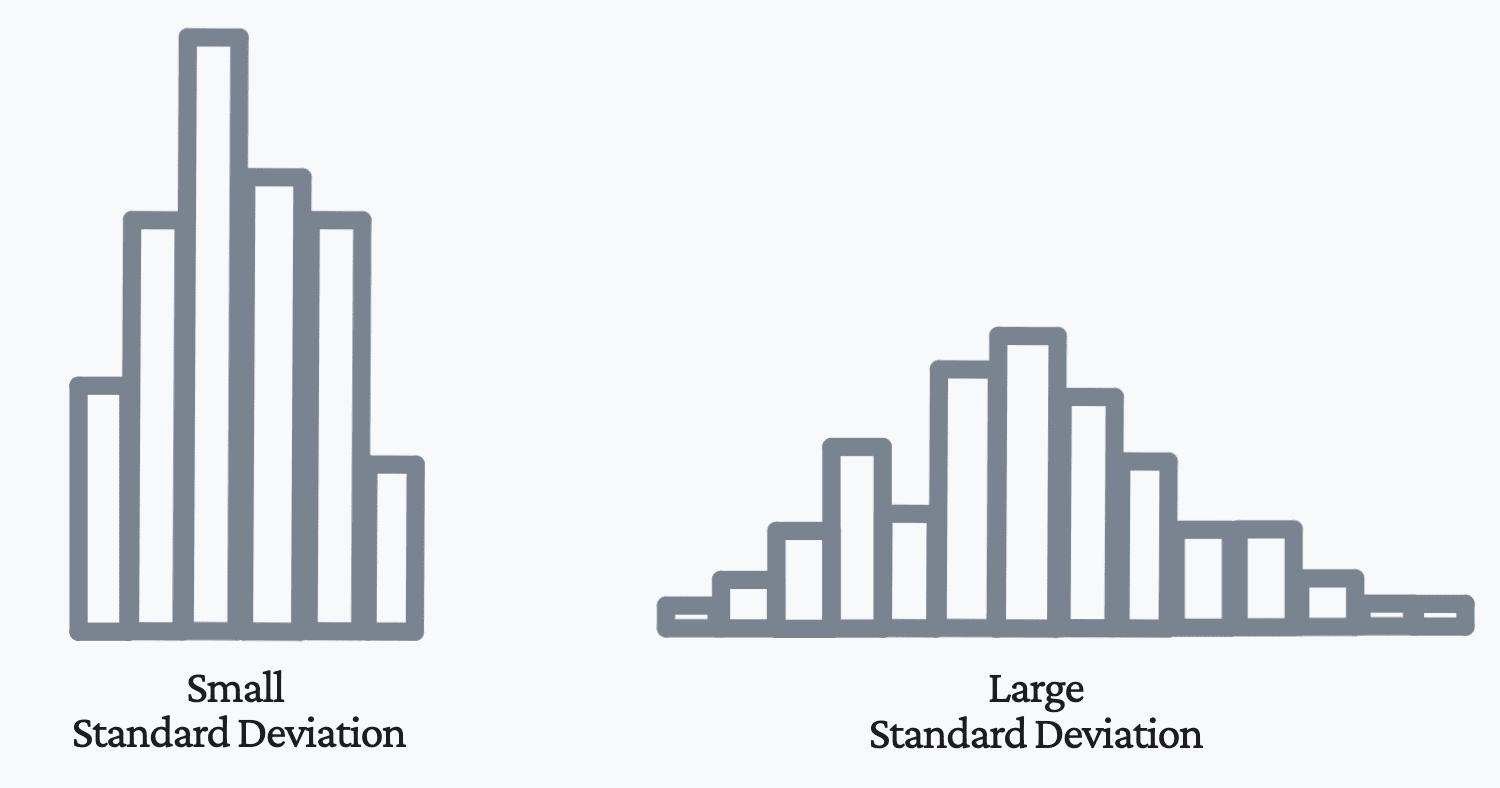
Image by Author
Data Scientists and other tech experts will come across datasets that have a large variance. Therefore, their usual go-to Empirical rule won’t help them and they will have to use Chebyshev’s theorem.
Wrapping Up
If you want to learn more about the dispersion of your data points, as long as you have calculated the mean and standard deviation and it does not follow a normal distribution, Chebyshev’s theorem can be applied. It will be able to determine the proportion of data falling within a specific range of the mean.
Nisha Arya is a Data Scientist and Freelance Technical Writer. She is particularly interested in providing Data Science career advice or tutorials and theory based knowledge around Data Science. She also wishes to explore the different ways Artificial Intelligence is/can benefit the longevity of human life. A keen learner, seeking to broaden her tech knowledge and writing skills, whilst helping guide others.