Scaling Data Management Through Apache Gobblin
Software companies can manage big data at a hyper-scale on different infrastructure stacks using Apache Gobblin.
Challenges of Big Data Management
In the modern world, most businesses rely on the power of big data and analytics to fuel their growth, strategic investments, and customer engagement. Big data is the underlying constant in the targeted advertisement, personalized marketing, product recommendations, insights generation, price optimizations, sentiment analysis, predictive analytics, and much more.
Data is often collected from multiple sources, transformed, stored, and processed on data lakes on-prem or on-cloud. While the initial ingest of data is relatively trivial and can be achieved through custom scripts developed in-house or traditional ETL (Extract Transform Load) tools, the problem quickly becomes prohibitively complex and expensive to solve as the companies have to:
- Manage full data lifecycle - for housekeeping and compliance purposes
- Optimize storage - to reduce associated costs
- Simplify Architecture - through the reuse of computing infrastructure
- Incrementally process data - through powerful state management
- Apply the same policies on batch and stream data - without duplication of effort
- Migrate between On-prem and Cloud - with the least effort
It is where Apache Gobblin, an open-source data management, and integration system comes in. Apache Gobblin provides unparalleled capabilities which can be used in whole or parts depending on the needs of the business.
Streamlining Big Data Management with Gobblin
In this section, we will delve into the various capabilities of Apache Gobblin that aid in addressing the challenges outlined previously.
Managing full data lifecycle
Apache Gobblin provides a gamut of capabilities to construct data pipelines that support the full suite of data lifecycle operations on datasets.
- Ingest data - from multiple sources to sinks ranging from Databases, Rest APIs, FTP/SFTP servers, Filers, CRMs like Salesforce and Dynamics, and more.
- Replicate data - between multiple data lakes with specialized capabilities for Hadoop Distributed File System via Distcp-NG.
- Purge Data - using retention policies like Time-based, Newest K, Versioned, or a combination of policies.
Gobblin's logical pipeline consists of a 'Source' that determines the distribution of work and creates 'Workunits.' These 'Workunits' are then picked up for execution as 'Tasks,' which include extraction, conversion, quality checking, and writing of data to the destination. The final step, 'Data Publish,' validates the successful execution of the pipeline and atomically commits the output data, if the destination supports it.
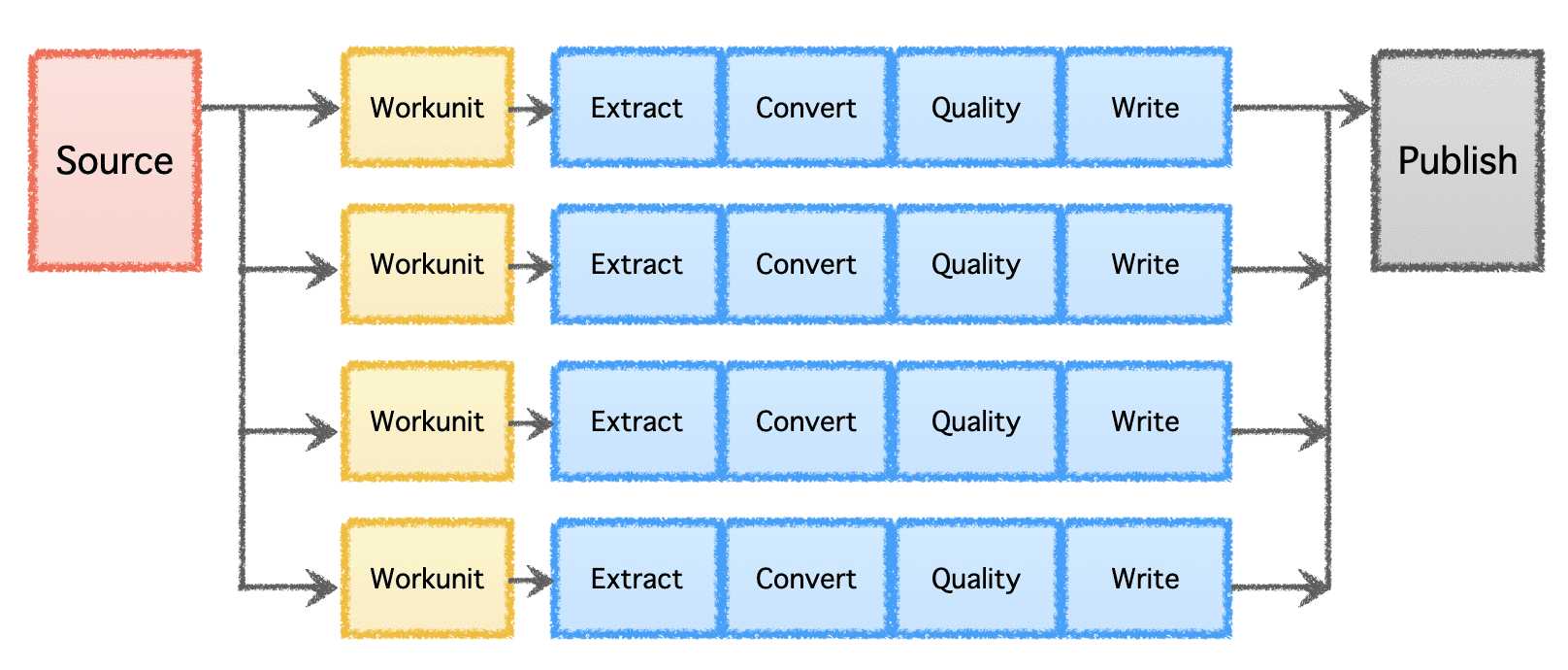
Image by Author
Optimize Storage
Apache Gobblin can help reduce the amount of storage needed for data through post-processing data after ingestion or replication through compaction or format conversion.
- Compaction - post-processing data to deduplicate based on all the fields or key fields of the records, trimming the data to keep only one record with the latest timestamp with the same key.
- Avro to ORC - as a specialized format conversion mechanism to convert the popular row-based Avro format to a hyper-optimized column-based ORC format.
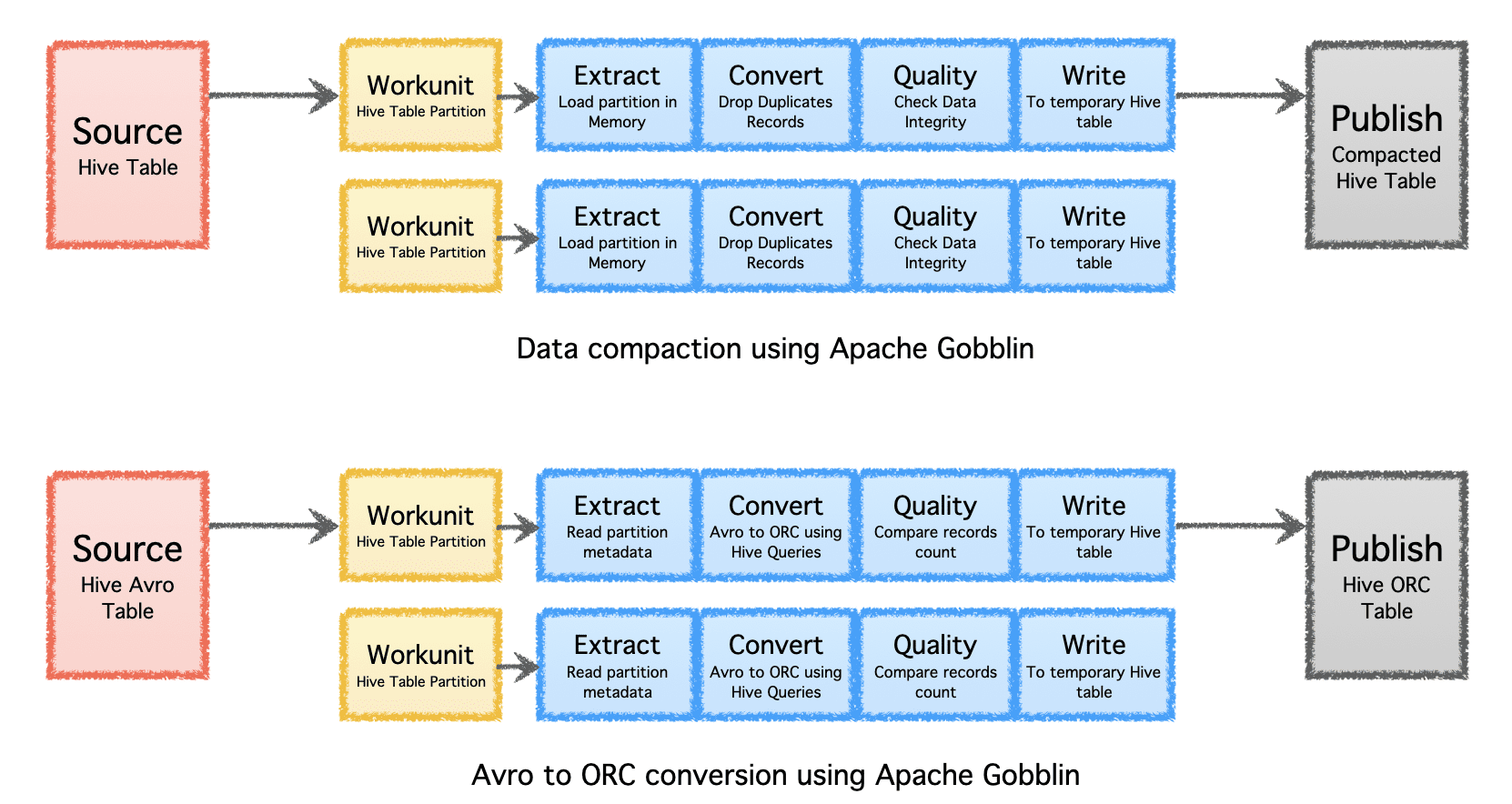
Image by Author
Simplify Architecture
Depending on the stage of the company (startup to enterprise), scale requirements, and their respective architecture, companies prefer to set up or evolve their data infrastructure. Apache Gobblin is very flexible and supports multiple execution models.
- Standalone Mode - to run as a standalone process on a bare metal box, i.e., single host for simple use cases and low-demanding situations.
- MapReduce Mode - to run as a MapReduce job on Hadoop infrastructure for big data cases to handle datasets ranging in Petabytes scale.
- Cluster Mode: Standalone - to run as a cluster backed by Apache Helix and Apache Zookeeper on a set of bare metal machines or hosts to handle large scale independent of the Hadoop MR framework.
- Cluster Mode: Yarn - to run as a cluster on native Yarn without the Hadoop MR framework.
- Cluster Mode: AWS - to run as a cluster on Amazon’s public cloud offering, ie. AWS for infrastructures hosted on AWS.
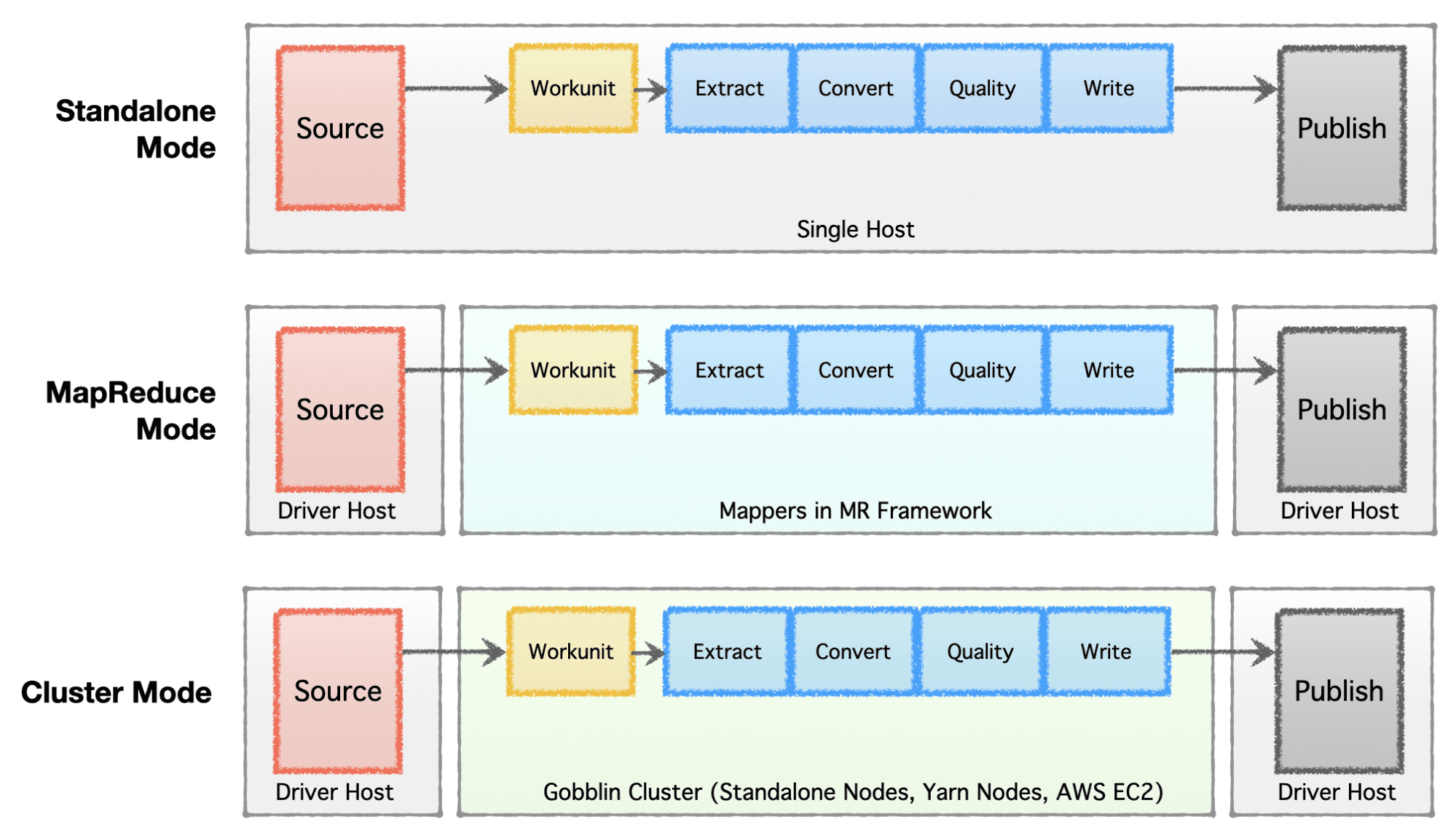
Image by Author
Incrementally process data
At a significant scale with multiple data pipelines and high volume, data needs to be processed in batches and over time. Therefore, it necessitates checkpointing so the data pipelines can resume from where they left off last time and continue onwards. Apache Gobblin supports low and high watermarks and supports robust state management semantics via State Store on HDFS, AWS S3, MySQL and more transparently.
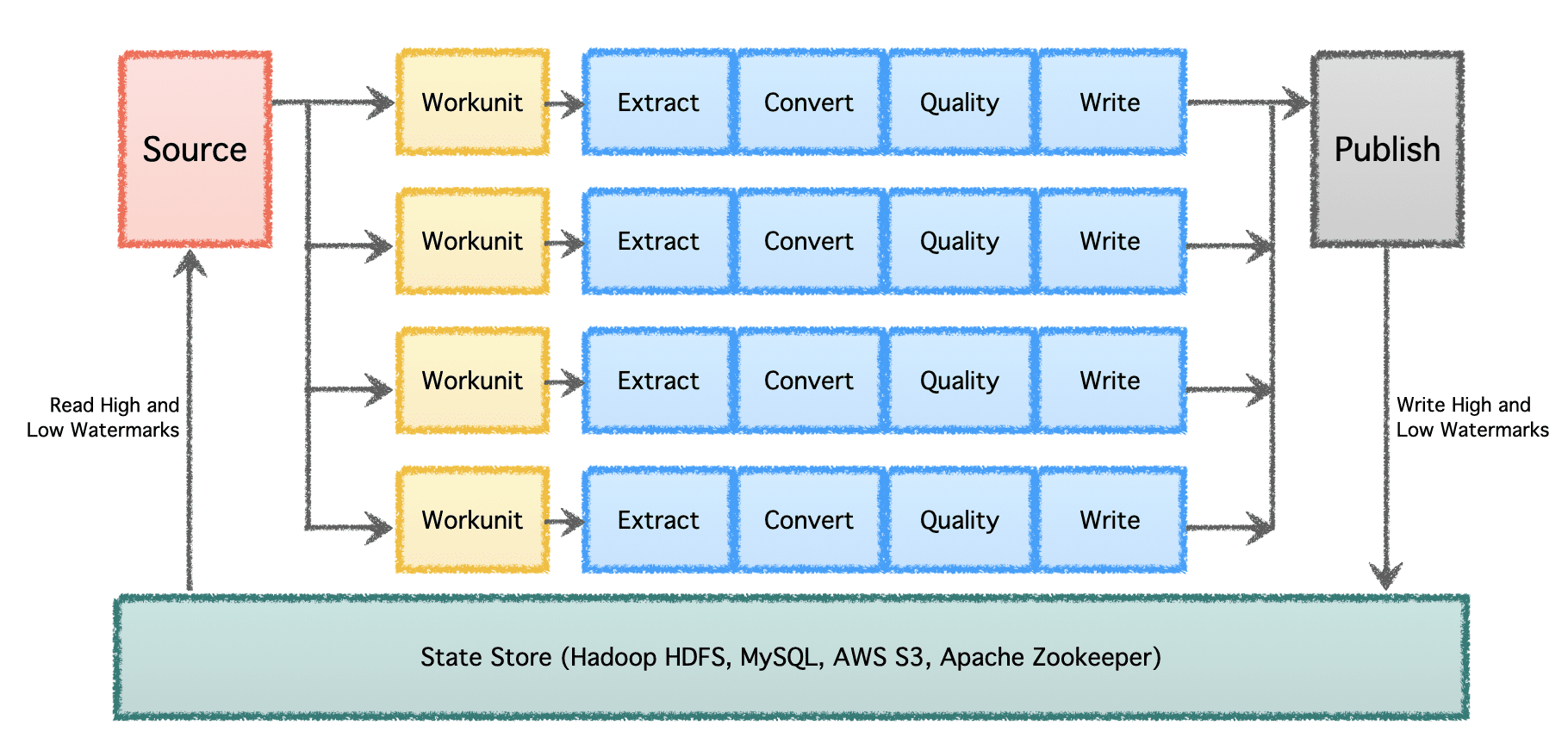
Image by Author
Same policies on batch and stream data
Most data pipelines today have to be written twice, once for batch data and again for near-line or streaming data. It doubles the effort and introduces inconsistencies in policies and algorithms applied to different types of pipelines. Apache Gobblin solves this by allowing users to author a pipeline once and run it on both batch and stream data if used in Gobblin Cluster mode, Gobblin on AWS mode, or Gobblin on Yarn mode.
Migrate between On-prem and Cloud
Due to its versatile modes that can run on-prem on a single box, a cluster of nodes, or the cloud - Apache Gobblin can be deployed and used on-prem and on the cloud. Therefore, allowing users to write their data pipelines once and migrate them along with Gobblin deployments easily between on-prem and cloud, based on specific needs.
Due to its highly flexible architecture, powerful features, and the extreme scale of data volumes that it can support and process, Apache Gobblin is used in the production infrastructure of major technology companies and is a must-have for any big data infrastructure deployment today.
More details on Apache Gobblin and how to use it can be found at https://gobblin.apache.org
Abhishek Tiwari is a Senior Manager at LinkedIn, leading the company's Big Data Pipelines organization. He is also the Vice President of Apache Gobblin at the Apache Software Foundation and a Fellow of the British Computer Society.