The Role of Resampling Techniques in Data Science
Resampling and how you can use it to improve the overall performance of your models.
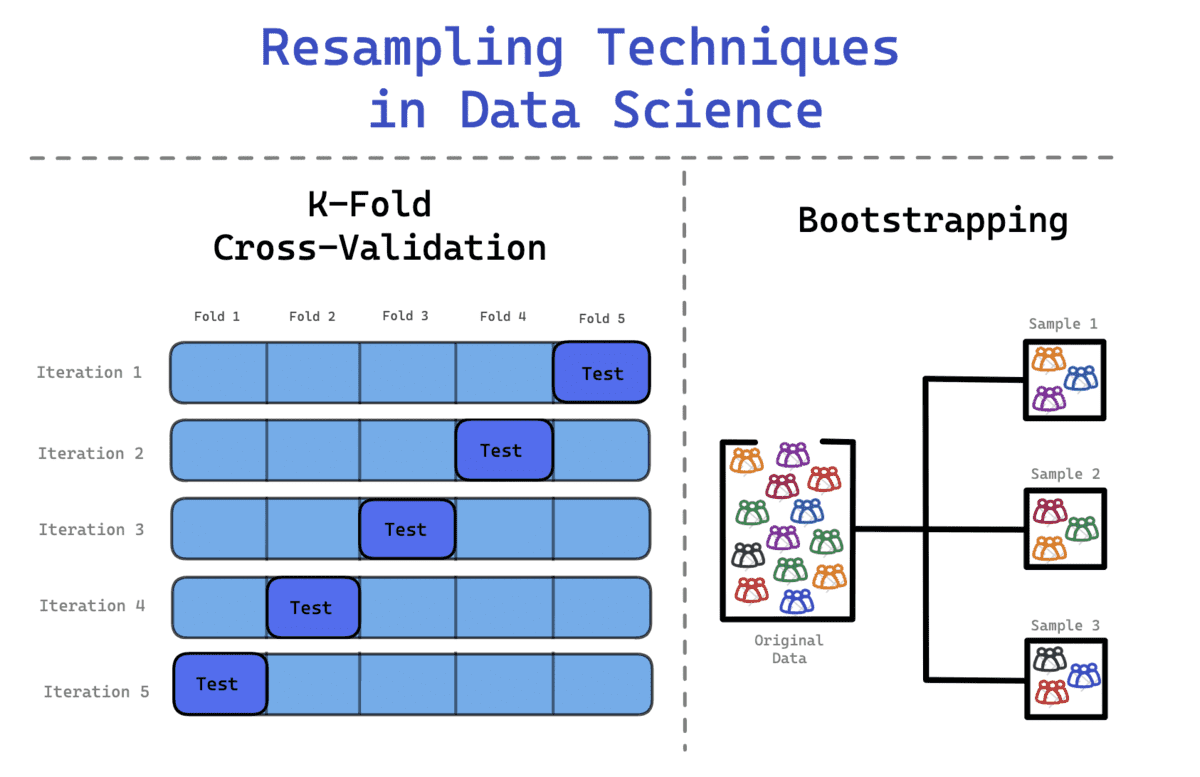
Image by Author
When working with models, you need to remember that different algorithms have different learning patterns when taking in data. It is a form of intuitive learning, to help the model learn the patterns in the given dataset, known as training the model.
The model will then be tested on the testing dataset, a dataset the model has not seen before. You want to achieve an optimum performance level where the model can produce accurate outputs on both the training and testing dataset.
You may have also heard of the validation set. This is the method of splitting your dataset into two: the training dataset and the testing dataset. The first split of the data will be used to train the model, whilst the second split of the data will be used to test the model.
However, the validation set method comes with drawbacks.
The model will have learnt all the patterns in the training dataset, but it may have missed out on relevant information in the testing dataset. This has caused the model to be deprived of important information that can improve its overall performance.
Another drawback is that the training dataset may face outliers or errors in the data, which the model will learn. This becomes part of the model's knowledge base and will be applied when testing in the second phase.
So what can we do to improve this? Resampling.
What is Resampling?
Resampling is a method that involves repeatedly drawing samples from the training dataset. These samples are then used to refit a specific model to retrieve more information about the fitted model. The aim is to gather more information about a sample and improve the accuracy and estimate the uncertainty.
For example, if you’re looking at linear regression fits and want to examine the variability. You will repeatedly use different samples from the training data and fit a linear regression to each of the samples. This will allow you to examine how the results differ based on the different samples, as well as obtain new information.
The significant advantage of resampling is that you can repeatedly draw small samples from the same population till your model achieves its optimum performance. You will save a lot of time and money by being able to recycle the same dataset, and not having to find new data.
Under-sampling and Oversampling
If you are working with highly unbalanced datasets, resampling is a technique you can use to help with it.
- Under-sampling is when you remove samples from the majority class, to provide more balance.
- Over-sampling is when you duplicate random samples from the minority class due to insufficient data collected.
However, these come with drawbacks. Removing samples in under-sampling can lead to a loss of information. Duplicating random samples from the minority class can lead to overfitting.
Two resampling methods are frequently used in data science:
- The Bootstrap Method
- Cross-Validation
Bootstrap Method
You will come across datasets that don’t follow the typical normal distribution. Therefore, the Bootstrap method can be applied to examine the hidden information and distribution of the data set.
When using the bootstrapping method, the samples that are drawn are replaced and the data that are not included in the samples are used to test the model. It is a flexible statistical method that can help data scientists and machine learning engineers quantify uncertainty.
The process includes
- Repeatedly drawing sample observations from the dataset
- Replacing these samples to ensure the original data set stays at the same size.
- An observation can either appear more than once or not at all.
You may have heard of Bagging, the ensemble technique. It is short for Bootstrap Aggregation, which combines bootstrapping and aggregation to form one ensemble model. It creates multiple sets of the original training data, which is then aggregated to conclude a final prediction. Each model learns the previous model's errors.
An advantage of Bootstrapping is that they have lower variance in comparison to the train-test split method mentioned above.
Cross-Validation
When you repeatedly split the dataset randomly, it can lead to the sample ending up in either the training or test sets. This can unfortunately have an unbalanced influence on your model from making accurate predictions.
In order to avoid this, you can use K-Fold Cross Validation to split the data more effectively. In this process, the data is divided into k equal sets, where one set is defined as the test set whilst the rest of the sets are used in training the model. The process will continue till each set has acted as the test set and all the sets have gone through the training phase.
The process includes:
- The data is split in k-folds. For example, a dataset is split into 10 folds - 10 equal sets.
- During the first iteration, the model is trained on (k-1) and tested on the one remaining set. For example, the model is trained on (10-1 = 9) and tested on the remaining 1 set.
- This process is repeated till all the folds have acted as the remaining 1 set in the testing phase.
This allows for a balanced representation of each sample, ensuring that all the data has been used to improve the model’s learning as well as test the model's performance.
Conclusion
In this article, you will have understood what resampling is and how you can sample your dataset in 3 different ways: train-test split, bootstrap, and cross-validation.
The overall aim for all of these methods is to help the model take in as much information as possible, in an effective way. The only way to ensure that the model has successfully learned is to train the model on a variety of data points in the dataset.
Resampling is an important element of the predictive modeling phase; ensuring accurate outputs, high-performance models, and effective workflows.
Nisha Arya is a Data Scientist and Freelance Technical Writer. She is particularly interested in providing Data Science career advice or tutorials and theory based knowledge around Data Science. She also wishes to explore the different ways Artificial Intelligence is/can benefit the longevity of human life. A keen learner, seeking to broaden her tech knowledge and writing skills, whilst helping guide others.