Web LLM: Bring LLM Chatbots to the Browser
Wouldn't it be cool if you can run LLMs and LLM chatbots natively in your browser? Let's learn more about the Web LLM project, an interesting step in this direction.

Image by Author
LLM-based chatbots are accessible through a front end, and they involve a large number of expensive API calls to the server side. But what if we could get LLMs to run entirely in the browser—using the computing power of the underlying system.
This way, the full functionality of the LLM is available at the client side—without having to worry about server availability, infrastructure, and the like. Web LLM is a project that aims to achieve this.
Let's learn more about what drives Web LLM and the challenges of building such a project. We'll also look at the advantages and limitations of Web LLM.
What is Web LLM?
Web LLM is a project that uses WebGPU and WebAssembly and much more to enable the running of LLMs and LLM apps completely in the browser. With Web LLM, you can run LLM chatbots in the browser by leveraging the underlying system’s GPU through WebGPU.
It uses the compiler stack of the Apache TVM project and uses WebGPU that was recently released. In addition to 3D graphics rendering and the like, the WebGPU API also supports general purpose GPU computations (GPGPU computations).
Challenges of Building Web LLM
Since Web LLM runs entirely on the client side without any inference server, the following challenges are associated with the project:
- Large language models use Python frameworks for deep learning that also natively support leveraging the GPU for operations on tensors.
- When building Web LLM to run completely in the browser, we will not be able to use the same Python frameworks. And alternative tech stacks that enable running LLMs on the web while still using Python for development had to be explored.
- Running LLM apps typically requires large inference servers, but when everything runs on the client side—in the browser—we cannot have large inference servers any longer.
- Requires a smart compression of the model’s weights to make it fit in the available memory.
How Does Web LLM Work?
The Web LLM project uses the underlying system’s GPU and hardware capabilities to run large language models in the browser. The process of machine learning compilation helps bake the functionality of LLMs into the browser side by leveraging TVM Unity and a set of optimizations.

How Web LLM Works | Image Source
The system is developed in Python and runs on the web using the TVM runtime. This porting to the web browser is achieved by running a series of optimizations.
The LLM’s functionality is first baked into an IRModule in TVM. Several transformations are run on the functions in the IRModule to get an optimized and runnable code. TensorIR is a compiler abstraction for optimizing programs with tensor computations. Further, INT-4 quantization is used to compress the model’s weights. And a TVM runtime is made possible using TypeScript and emscripten, an LLVM compiler that transforms C and C++ code to WebAssembly.
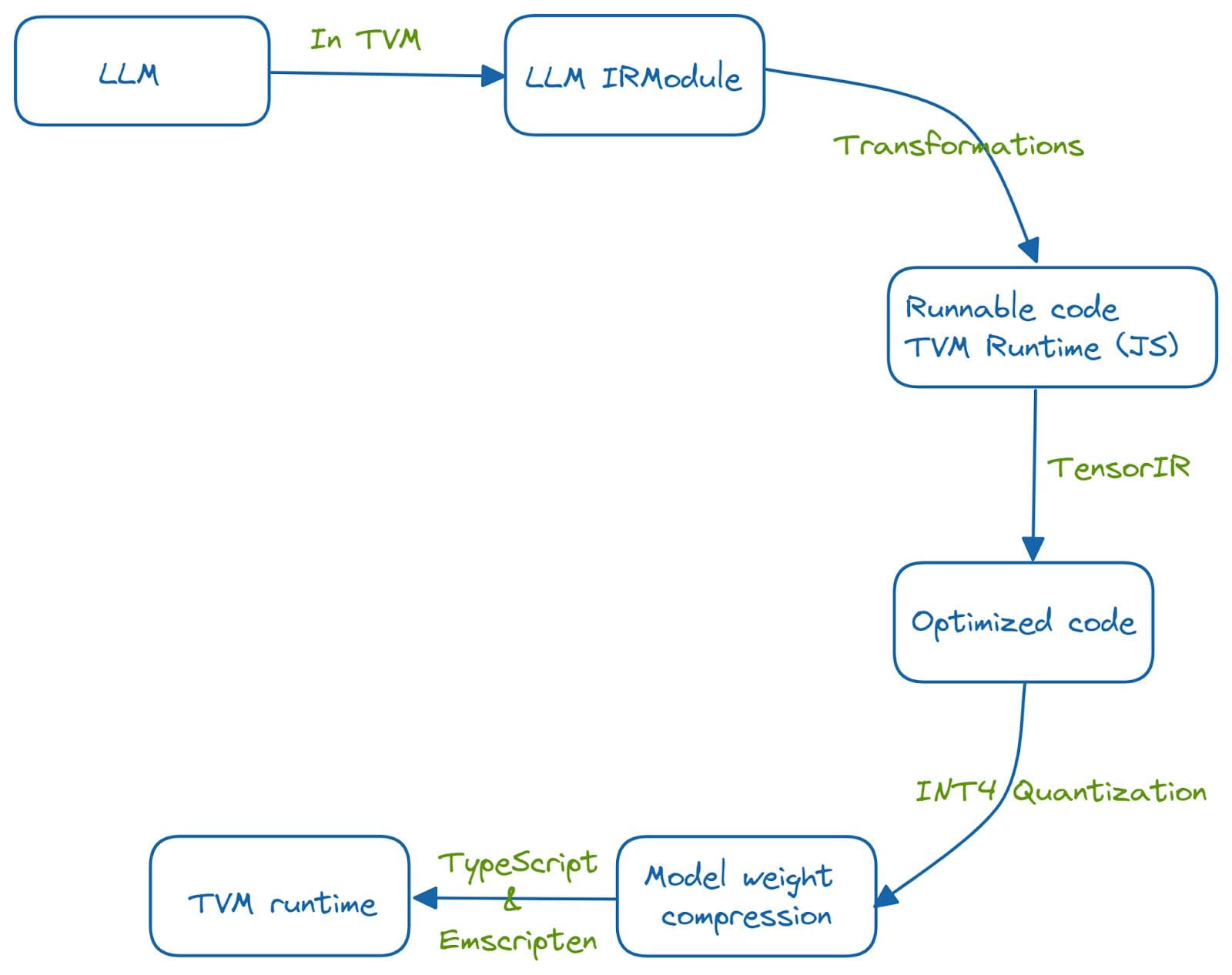
Image by Author
You need to have the latest version of Chrome or Chrome Canary to try out Web LLM. As of writing this article, Web LLM supports the Vicuna and LLaMa LLMs.
Loading the model takes a while the first time you run the model. Because the caching is complete after the first run, subsequent runs are considerably faster and have minimum overhead.

Advantages and Limitations of Web LLM
Let’s wrap up our discussion by enumerating the advantages and limitations of Web LLM.
Advantages
In addition to exploring the synergy of Python, WebAssembly and other tech stacks, Web LLM has the following advantages:
- The main advantage of running LLMs in the browser is privacy. Because the server side is completely eliminated in this privacy-first design, we no longer have to worry about the use of our data. Because Web LLM harnesses the computing power of the underlying system’s GPU, we don't have to worry about data reaching malicious entities.
- We can build personal AI assistants for day-to-day activities. Therefore, the Web LLM project offers a high degree of personalization.
- Another advantage of Web LLM is the reduced cost. We no longer need expensive API calls and inference servers, and Web LLM uses the underlying system’s GPU and processing capabilities. So running Web LLM is possible at a fraction of the cost.
Limitations
Here are some of the limitations of Web LLM:
- Though Web LLM alleviates the concerns around inputting sensitive information, it is still susceptible to attack on the browser.
- There is further scope for improvement by adding support for multiple language models and choice of browsers. Currently, this feature is available only in Chrome Canary and the latest version of Chrome. Expanding this to a bigger set of supported browsers will be helpful.
- Because of robustness checks run by the browser, Web LLM using WebGPU does not have the native performance of a GPU runtime. You can optionally disable the flag that runs robustness checks in order to improve performance.
Conclusion
We’ve tried to understand how Web LLM works. You can try running it in your browser or even deploy it locally. Consider playing around with the model in your browser and check how effective it is when integrated into your day-to-day workflow. If you are interested you can also check out the MLC-LLM project, which allows you to run LLMs—natively on any device of your choice—including laptops and iPhones.
References and Further Reading
[1] WebGPU API, MDN Web Docs
[2] TensorIR: An Abstraction for Automatic Tensorized Program Optimization
[3] MLC-LLM
Bala Priya C is a developer and technical writer from India. She likes working at the intersection of math, programming, data science, and content creation. Her areas of interest and expertise include DevOps, data science, and natural language processing. She enjoys reading, writing, coding, and coffee! Currently, she's working on learning and sharing her knowledge with the developer community by authoring tutorials, how-to guides, opinion pieces, and more.