A Playbook to Scale MLOps
MLOps teams are pressured to advance their capabilities to scale AI. We teamed up with Ford Motors to explore how to scale MLOps within an organization and how to get started.
By Mike Caravetta & Brendan Kelly
Scaling MLOps for Your Teams
MLOps teams are pressured to advance their capabilities to scale AI. In 2022, we saw an explosion of buzz around AI and MLOps inside and outside of organizations. 2023 promises more hype with the success of ChatGPT and the traction of models inside enterprises.
MLOps teams look to expand their capabilities while meeting the pressing needs of the business. These teams start 2023 with a long list of resolutions and initiatives to improve how they industrialize AI. How are we going to scale the components of MLOps (deployment, monitoring, and governance)? What are the top priorities for our team?
AlignAI teamed up with Ford Motors to write this playbook to guide MLOps teams based on what we have seen be successful to scale.
What Does MLOps Mean?
To start, we need a working definition of MLOps. MLOps is an organization’s transition from delivering a few AI models to delivering algorithms reliably at scale. This transition requires a repeatable and predictable process. MLOps means more AI and the associated return on investment. Teams win at MLOps when they focus on orchestrating the process, the team, and the tools.
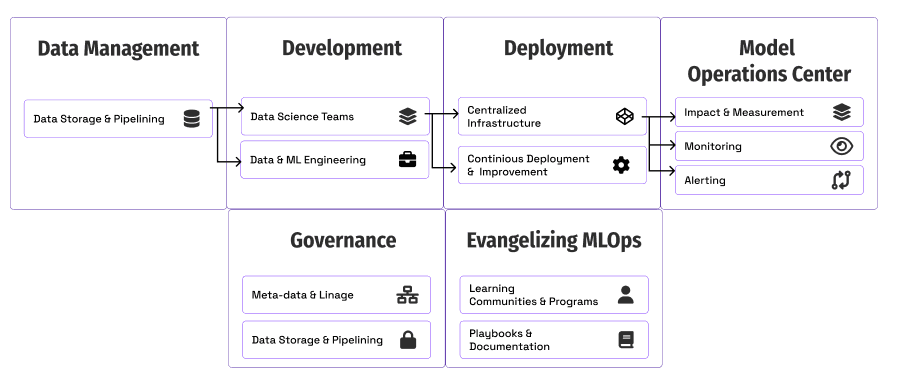
Foundational components of MLOps to scale
Let’s walk through each area with examples from Ford Motors and ideas to help get you started.
- Measurement and Impact: how teams track and measure progress.
- Deployment & Infrastructure: how teams scale model deployments.
- Monitoring: maintaining the quality and performance of models in production.
- Governance: creating controls and visibility around models.
- Evangelizing MLOps: educating the business and other technical teams on why and how to utilize MLOps methods.
Measurement and Impact
One day, a business executive walked into Ford’s MLOps command center. We reviewed the usage metrics of a model and had a productive conversation about why usage had dropped. This visibility of the impact and adoption of models is crucial to building trust and reacting to the needs of the business.
A fundamental question for teams leveraging AI and investing in MLOps capabilities is how do we know if we are progressing?
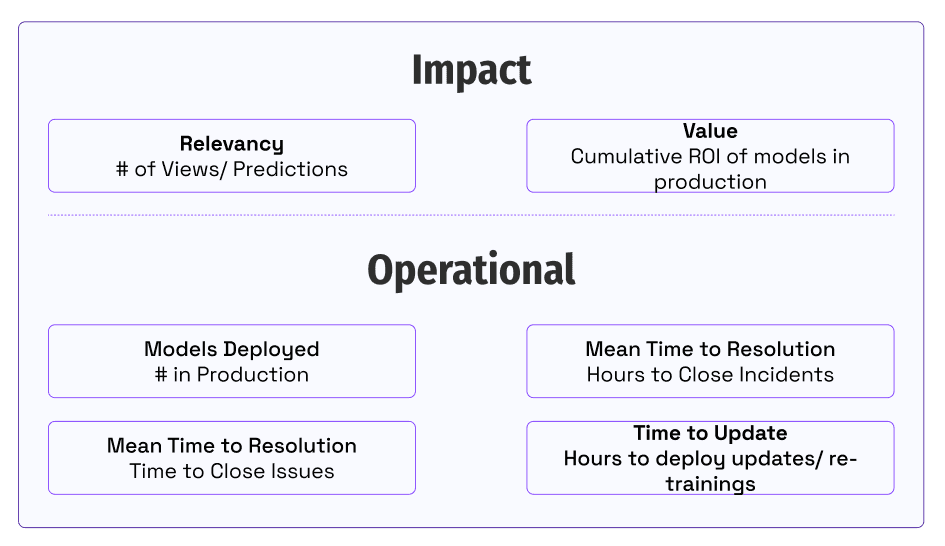
The key is to align our team on how we provide value to our customers and business stakeholders. Teams focus on quantifying performance in the business impact they provide and the operational metrics enabling it. Measuring impact captures the picture of how we generate.
Ideas to get started:
- How do you measure the value of models in development or production today? How do you track the usage and engagement of your business stakeholders?
- What are the operational or engineering metrics for your models in production today? Who owns the improvement of these metrics? How do you give people access to see these metrics?
- How do people know if there is a change in user behavior or solution usage? Who responds to these issues?
Deployment & Infrastructure
The first hurdle the team faces in MLOps is deploying models into production. As the number of models grows, teams must create a standardized process and shared platform to handle the increased volume. Managing 20 models deployed using 20 different patterns can make things cumbersome. Enterprise teams typically create centralized infrastructure resources around X models. Choosing the right architecture and infrastructure across models and teams can be an uphill battle. However, once it is established, it provides a strong foundation to build the capabilities around monitoring and governance.
At Ford, we created a standard deployment function using Kubernetes, Google Cloud Platform, and a team to support them.
Ideas for your team:
- How will you centralize the deployment of models? Can you create or designate a centralized team and resources to manage the deployments?
- What deployment patterns (REST, batch, streaming, etc.)?
- How are you going to define and share those with other teams?
- What are the most time-consuming or difficult aspects for your modeling teams to overcome to get a model in production? How can the centralized deployment system be designed to mitigate these issues?
Monitoring
A unique and challenging aspect of machine learning is the ability of models to drift and change in production. Monitoring is critical in creating trust with stakeholders to use the models. Google’s Rules of Machine Learning says to “practice good alerting hygiene, such as making alerts actionable.” This requires teams to define the areas to monitor and how to generate these alerts. A challenging piece becomes making these alerts actionable. There needs to be a process established to investigate and mitigate issues in production.

At Ford, the Model Operations Center is the centralized location with screens full of information and data to understand if the models are getting what we expect in near real-time.
Here is a simplified example of a dashboard looking for usage or record counts dropping below a set threshold.
Monitoring Metrics
Here are monitoring metrics to consider for your models:
- Latency: Time to return predictions (e.g., batch processing time for 100 records).
- Statistical Performance: the ability of a model to make correct or close predictions given a test data set (e.g., Mean Squared Error, F2, etc.).
- Data Quality: quantification of the completeness, accuracy, validity, and timeliness of the prediction or training data. (e.g., % of prediction records missing a feature).
- Data Drift: changes to the distribution of data over time (e.g., lighting changes for a computer vision model).
- Model Usage:how often the model predictions are used to solve business or user problems (e.g., # of predictions for model deployed as a REST endpoint).
Ideas for your team:
- How should all models be monitored?
- What metrics need to be included with each model?
- Is there a standard tool or framework to generate the metrics?
- How are we going to manage the monitoring alerts and issues?
Governance
Innovation inherently creates risk, especially in the enterprise environment. Therefore, successfully leading innovation requires designing controls into the systems to mitigate risk. Being proactive can save a lot of headaches and time. MLOps teams should proactively anticipate and educate stakeholders on the risks and how to mitigate them.
Developing a proactive approach to governance helps avoid reacting to the needs of the business. Two key pieces of the strategy are controlling access to sensitive data and capturing lineage and metadata for visibility and audit.
Governance provides great opportunities for automation as teams scale. Waiting for data is a constant momentum killer on data science projects. At Ford, a model automatically determines if there is personally identifiable information in a data set with 97% accuracy. Machine learning models also help with access requests and have reduced the processing time from weeks to minutes in 90% of the cases.
The other piece is tracking meta-data throughout the model’s life cycle. Scaling machine learning requires scaling trust in the models themselves. MLOps at scale require built-in quality, security, and control to avoid issues and bias in production.
Teams can get caught up in the theory and opinions around governance. The best course of action is to start with clear access and controls around user access.
From there, meta-data capture and automation are key. The table below outlines the areas to collect meta-data. Wherever possible, leverage pipelines or other automation systems to capture this information automatically to avoid manual processing and inconsistencies.
Meta-data to Collect
Here are the items to collect for each model:
- Version/ Trained Model Artifact:Unique identifier of the trained model artifact.
- Training Data- Data used to create the trained model artifact
- Training Code- Git hash or link to the source code for inference.
- Dependencies- Libraries used in training.
- Prediction Code- Git hash or link to the source code for inference.
- Historical Predictions- Store inferences for audit purposes.
Ideas for your team:
- What issues have we encountered across projects?
- What problems are our business stakeholders experiencing or concerned about?
- How do we manage access requests for data?
- Who approves them?
- Are there automation opportunities?
- What vulnerabilities do our model pipelines or deployments create?
- What pieces of meta-data do we need to capture?
- How is it stored and made available?
Evangelizing MLOps
Many technical teams fall into the pitfall of thinking: “if we build it, they will come.” There’s more to solving the problem. It also involves sharing and advocating for the solution to increase organizational impact. MLOps teams need to share the best practices and how to solve the unique problems of your organization’s tools, data, models, and stakeholders.
Anybody in the MLOps team can be an evangelist by partnering with the business stakeholders to showcase their success stories. Showcasing examples from your organization can illustrate the benefits and opportunities clearly.
People across the organization looking to industrialize AI need education, documentation, and other support. Lunch and Learns, onboarding, and mentorship programs are great places to start. As your organization scales, more formalized learning and onboarding programs with supporting documentation can accelerate your organization’s transformation.
Ideas for your team:
- How can you create a community or recurring learnings and best practices for MLOps?
- What are the new roles and capabilities we need to establish and share?
- What problems have we solved that can be shared?
- How are you providing training or documentation to share best practices and success stories with other teams?
- How can we create learning programs or checklists for data scientists, data engineers, and business stakeholders to learn how to work with AI models?
Getting Started
MLOps teams and leaders face a mountain of opportunities while balancing the pressing needs of industrializing models. Each organization faces different challenges, given its data, models, and technologies. If MLOps were easy, we probably would not like working on the problem.
The challenge is always prioritization.
We hope this playbook helped generate new ideas and areas for your team to explore. The first step is to generate a big list of opportunities for your team in 2023. Then prioritize them ruthlessly based on what will have the largest impact on your customers. Teams can also define and measure their maturity progress against emerging benchmarks. This guide from Google can provide a framework and maturity milestones for your team.
Ideas for your team:
- What are the largest opportunities to advance our maturity or sophistication with MLOps?
- How do we capture and track our progress on the projects that advance maturity?
- Generate a list of tasks for this guide and your team. Prioritize based on the time to implement and the expected benefit. Create a roadmap.
References
- https://www2.deloitte.com/content/dam/insights/articles/7022_TT-MLOps-industrialized-AI/DI_2021-TT-MLOps-industrialized-AI.pdf
- https://proceedings.neurips.cc/paper/2015/file/86df7dcfd896fcaf2674f757a2463eba-Paper.pdf
- https://developers.google.com/machine-learning/guides/rules-of-ml
- https://cloud.google.com/architecture/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning
Mike Caravetta has delivered hundreds of millions of dollars in business value using analytics.He currently leads the charge to scale MLOps in manufacturing and complexity reduction at Ford.
Brendan Kelly, Co-Founder of AlignAI, has helped dozens of organizations accelerate MLOps across the banking, financial services, manufacturing, and insurance industries.