An MLOps Mindset: Always Production-Ready
A lack of an ML production mindset from the beginning of a project can lead to surprises later on, especially during production time, resulting in re-modeling and delayed time-to-market.
The success of machine learning (ML) across many domains has brought with it a new set of challenges – specifically the need to continuously train and evaluate models and continuously check for drift in training data. Continuous integration and deployment (CI/CD) is at the core of any successful software engineering project and is often referred as DevOps. DevOps helps streamline code evolution, enables various testing frameworks, and provides flexibility for enabling selective deployment to various deployment servers (dev, staging, prod, etc.).
The new challenges associated with ML have expanded the traditional scope of CI/CD to also include what is now commonly referred as Continuous Training (CT), a term first introduced by Google. Continuous training requires ML models to be continuously trained on new datasets and evaluated for expectations before being deployed to production, as well as enabling many more ML specific features. Today, within a machine learning context, DevOps is becoming known as MLOps and includes CI, CT & CD.
MLOps Principles
All product development is based on certain principles and MLOps is no different. Here are the three most important MLOps principles.
- Continuous X: The focus of MLOps should be in evolution, whether it is continuous training, continuous development, continuous integration or anything that is continuously evolving/changing.
- Track Everything: Given the exploratory nature of ML, one needs to track and collect whatever happens, similar to the processes in a science experiment.
- Jigsaw Approach: Any MLOps framework should support pluggable components. However, it’s important to strike the right balance: too much pluggability causes compatibility issues, whereas too little restricts the usage.
With these principles in mind, let’s identify the key requirements that govern a good MLOps framework.
MLOps Requirements
As previously mentioned, Machine learning has driven a new unique set of requirements for Ops.
- Reproducibility: Enable ML experiments to reproduce the same results repeatedly to validate the performance.
- Versioning: Maintain versioning from all directions, including: data, code, models and configs. One way to perform ‘data-model-code’ versioning is to using version control tools like GitHub.
- Pipelining: Although Directed Acyclic Graph (DAG) based pipelines are often used in non-ML scenarios (ex -Airflow), ML brings its own pipelining requirements to enable continuous training. Reusability of pipeline components for train and predict ensures consistency in feature extraction and reduces data processing errors.
- Orchestration & Deployment: ML model training requires a distributed framework of machines involving GPUs and therefore, executing a pipeline in the cloud is an inherent part of the ML training cycle. Model deployment based on various conditions (metric, environment etc.) brings unique challenges in machine learning.
- Flexibility: Enable flexibility for choosing data sources, selecting a cloud provider and deciding upon different tools (data analysis, monitoring, ML frameworks, etc.) Flexibility can be achieved by providing an option for plugins to external tools and/or offering the capability to define custom components. A flexible orchestration & deployment component ensures cloud agnostic pipeline execution and ML service.
- Experiment Tracking: Unique to ML, experimentation is an implicit part of any project. After multiple rounds of experimentation (i.e. experimentation with architecture or hyper-parameters in the architecture), an ML model gets matured. Keeping a log of each experiment for future reference is essential to ML. Experiment tracking tools can be used to ensure code and model versioning and DVC like tools ensure code-data versioning.
Practical Considerations
In the excitement of creating ML models, some specific ML hygiene is often missed: such as initial data analysis or hyperparameter tuning or pre-/post- processing. In many cases, there is a lack of an ML production mindset from the beginning of the project, which leads to surprises (memory issues, budget overflow etc.) at later stages of the project, especially during production time, resulting in re-modeling and delayed time-to-market. But using an MLOps framework from the beginning of a ML project addresses production considerations early on and enforces a systematic approach to solving machine learning problems such as data analysis, experiment tracking etc.
An MLOps also makes it possible to be production-ready at any given point of time. This is often crucial for startups when there is a requirement for shorter time-to-market. With MLOps providing flexibility in terms of orchestration & deployment, production readiness can be achieved by pre-defining orchestrators (ex- github action) or deployers (ex- MLflow, KServe etc.) which are part of MLOps pipelining.
Existing Frameworks for MLOps
Cloud service providers like Google, Amazon, Azure provide their own MLOps frameworks that can be used in their own platform or as part of existing machine learning frameworks (TFX pipelining as part of Tensorflow framework). These MLOps frameworks are easy to use and exhaustive in their functionality.
Using an MLOps framework from a cloud service provider restricts an organization to use MLOps in their environment. For many organizations this becomes a big restriction as usage of cloud service depends on what their customer wants. In many cases, one needs an MLOps framework that provides flexibility in terms of choosing a cloud provider and at the same time, has most of the functionalities of MLOps.
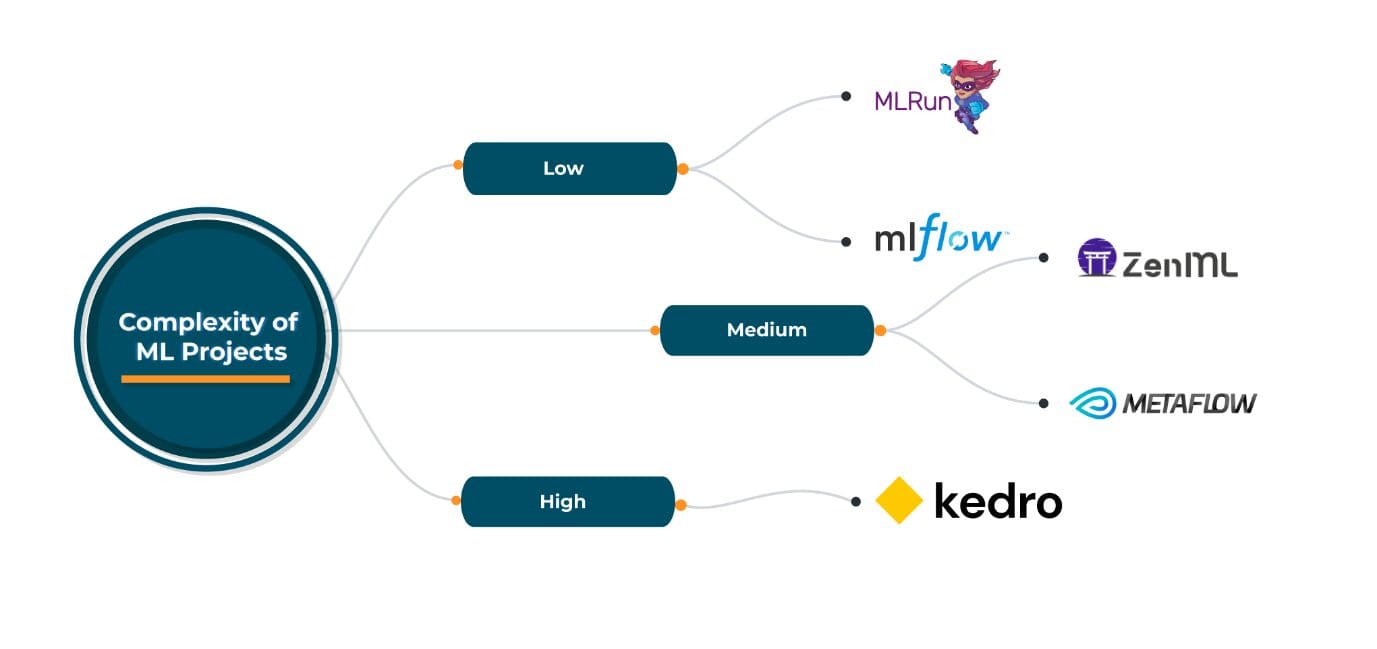
Open-source MLOps frameworks come in handy for such scenarios. ZenML, MLRun, Kedro, Metaflow are some of well-known open-source MLOps frameworks widely used with their own pros and cons. They all provide good flexibility in terms of choosing cloud providers, orchestration/deployment and ML tools as part of their pipeline. Selecting of any of these open source frameworks depends on the specific MLOps requirements. However, all these frameworks are generic enough to cater to wide range of requirements.
Based on experience with these open-source MLOps frameworks in their current state, I recommend the following:
Adopt MLOps Early On
MLOps is the next evolution in DevOps and is bringing together people from different domains: data engineers, machine learning engineers, infrastructure engineers as well as others. In the future we can expect MLOps to become low-code, similar to what we’ve seen within DevOps today. Startups in particular should adopt MLOps in their early stages of development to ensure faster time-to-market in addition to the other benefits it brings to the table.
Abhishek Gupta is the Principal Data Scientist at Talentica Software. In his current role, he works closely with a number of companies to help them with AI/ML for their product lineups. Abhishek is an IISc Bangalore alumnus who has been working in the area of AI/ML and big data for more than 7 years. He has a number of patents and papers in various areas like communication networks and machine learning.