Why we will always need humans to train AI — sometimes in real-time
Customizable, real-time data labeling pipelines that can continuously receive and process unlabeled data are necessary to train and perfect the AI that impacts our lives and daily conveniences.
By Shoma Kimura, Senior Director of AI Community Operations at TaskUs.
AI and machine learning are now undeniably part of our everyday lives. We encounter it more often than we may realize. What was once a seemingly advanced technology is even gaining prominence even in places we take for granted, like grocery stores and on our own personal devices.
You’ve probably seen reports of increasingly more popular in-store robots that detect spills and other hazards, check store inventory, and help with gathering online orders. Perhaps you’ve even seen it at your own local grocery store. You may also be aware of a new advertising technique called live shopping that allows viewers to purchase a product as it appears onscreen.
These are just two examples of the ways in which AI is adding safety and convenience to our lives. These tools are powered by machine learning algorithms that automatically identify and fix the things that may cause hiccups in the in-store shopping experience or quickly guide us to the things we’re interested in purchasing or learning more about online.
But below the surface, there’s an infinite amount of data to annotate to train these machines. And sometimes, this data must be labeled at the moment to ensure continuous, accurate service. Deploying AI in real-world production environments requires a streamlined data annotation pipeline to make sure the model runs smoothly (with human intervention as needed), and there is a constant feedback loop to constantly re-train and fine-tune the model.
AI isn’t ready for primetime — why humans are still an important part of the equation
For live video advertising or live shopping to work properly, the people, products, and places in movies, TV shows, and online videos must be correctly identified every time, without fail. For in-store robots to work properly, they must be able to accurately identify hazards and products.
But the fact of the matter is machine learning algorithms alone cannot yet accurately identify these objects without the help of the human eye and human judgment. Thousands of hours of movies and TV shows with endless images must first be reviewed and labeled by data annotators before the model can do its job.

This data annotation piece of the project is often thought of as part of the training phase of the AI before its deployment to production. However, continuously optimizing and improving models in production is necessary and ensures the model can adapt to ever-changing data.
Sometimes, it goes a step further than that — it’s not just continuously training the AI. It’s verification in real-time that ensures the AI consistently works properly at the moment. When it’s necessary to escalate an issue, a fast response is often necessary.
What is real-time data labeling, and why is it necessary?
Customizable, real-time data labeling pipelines that can continuously receive and process unlabeled data are necessary to train and perfect the AI that impacts our lives and daily conveniences. AI that seemingly works in real-time still needs a human to verify data, and we have cases where we have to support the AI in a very short amount of time, even as low as 4 seconds for mission-critical operations.
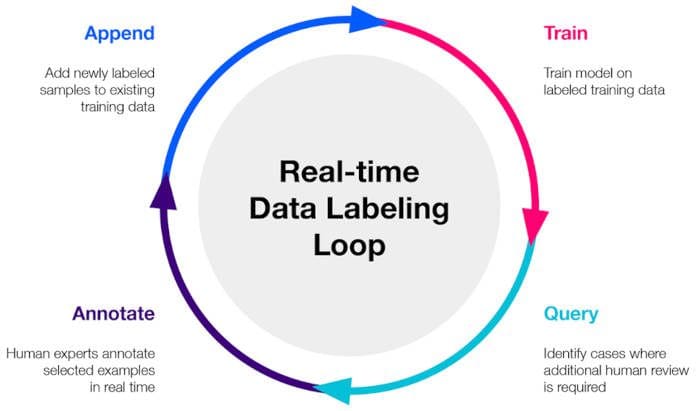
This practice is also called real-time machine learning and has also been called continual learning or active learning. You can think of real-time data labelers as the “man behind the curtain” of AI technologies.
There are two different types of this practice:
- You can deploy the new model in an environment that is NOT critical and observe the KPI and pivot as needed. For example, a small group of users can try out a feature so we can observe the results, and it will not result in any security issue or severe impact.
- Or, for operations that are critical in production and you are not sure of the AI results yet,
you will want the AI to escalate to humans to make sure that the right decision is made. An instance of this would be confirming what an AI model “thinks” might be sensitive or dangerous content online. In that kind of case, the accuracy that humans bring and speed are both crucial.
Not only is real-time data labeling or active learning necessary today, but it will remain necessary for as long as AI models have new data to assess and act on appropriately. In other words, real-time data labeling will always be needed, and humans will always be a critical component of operable AI.
We often think of AI as a tool to support humans, but in these cases, humans must support AI. This will be the AI model of the future.
Bio: Shoma Kimura is the Senior Director of AI Community Operations at TaskUs, where he and his team of AI experts power the world’s most disruptive companies with high-quality data labeling services, enabling them to develop cutting-edge AI systems.