Federated Learning: Collaborative Machine Learning with a Tutorial on How to Get Started
Read on to learn more about the intricacies of federated learning and what it can do for machine learning on sensitive data.
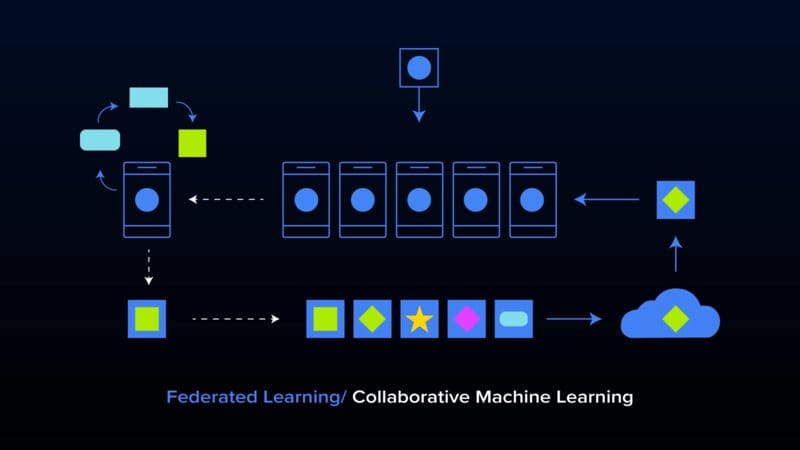
Federated Learning: Privacy, Security, and Data Sovereignty in the Lab and in the Wild (with Tutorial)
Federated learning, also known as collaborative learning, allows training models at scale on data that remains distributed on the devices where they are generated. Sensitive data remains with the owners of said data, where training is conducted, and a centralized training orchestrator of training only sees the contribution of each client through model updates.
Federated learning doesn’t guarantee privacy on its own (we'll touch on breaking and repairing privacy in federated learning systems later on), but it does make privacy possible.
Use cases for federated learning:
- Next word prediction for mobile phone keyboards (e.g. McMahan et al. 2017, Hard et al. 2019)
- Health research (e.g. Kaissis et al. 2020, Sadilek et al. 2021)
- Autonomous vehicles (e.g. Zeng et al. 2021, OpenMined blog post)
- “Smart home” systems (e.g. Matchi et al. 2019, Wu et al. 2020)
- … and anywhere else where machine learning predictions would be useful, but individuals would rather not give up their personal data if given the choice. That covers pretty much every scenario where predictions are made at a resolution of the individual.
With the public and policy-makers becoming more aware of the data economy, demand for privacy-preserving machine learning is on the rise. As a result, data practices have been garnering increased scrutiny, and research on privacy-respecting tools like federated learning is increasingly active. Ideally, federated learning aims to preserve individual and institutional privacy while potentially making collaborations between data stakeholders possible where they would normally be impossible due to trade secrecy, private health information, or the increased risk of data breaches.
Government regulations like the European Union’s General Data Protection Regulation or the California Consumer Privacy Act (among others) make privacy preserving strategies like federated learning become a useful tool for enterprises that want to remain in legal operation. At the same time, attaining a desired degree of privacy and security while maintaining model performance and efficiency presents plenty of technical challenges in their own right.
Finally, from the everyday perspective of the individual data-producer (such as, in all likelihood, yourself, dear reader), it’s nice to know that, at least in theory, there’s something that can be placed between your private health and financial data and the kind of hodgepodge ecosystem of data brokers that track everything else you do online, typically sans both moral backbone and security competency.
If any of these issues strike a chord with you, then read on to learn more about the intricacies of federated learning and what it can do for machine learning on sensitive data.
Federated Learning in a Nutshell
Federated learning aims to train a single model from multiple data sources, under the constraint that data stays at the source and is not exchanged by the data sources (a.k.a. nodes, clients, or workers) nor by the central server orchestrating training, if present.
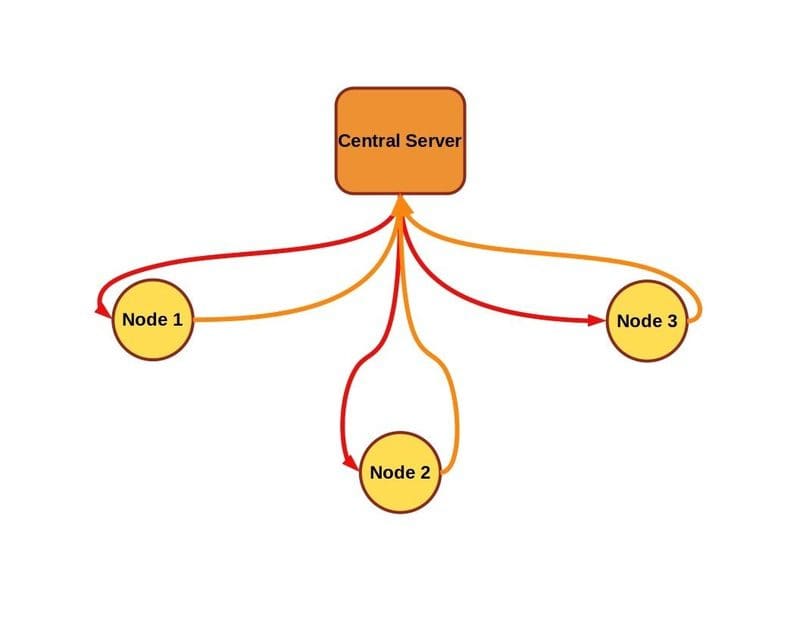
In a typical federated learning scheme, a central server sends model parameters to a population of nodes (also known as clients or workers). The nodes train the initial model for some number of updates on local data and send the newly trained weights back to the central server, which averages the new model parameters (often with respect to the amount of training performed on each node). In this scenario the data at any one node is never directly seen by the central server or the other nodes, and additional techniques, such as secure aggregation, can further enhance privacy.
There are many variations within this framework. For example, we’re mainly concerned in this article with federated learning schemes managed by a central server that orchestrates training on multiple devices of the same type, each training on their own local data and uploading the results to the central server. This is the basic scheme described by McMahan et al. in 2017. However, it’s possible to do away with centralized control of training, and in some situations it may be desirable to do so. When individual nodes distribute the role of the central manager it becomes decentralized federated learning, an attractive approach for training collaborative models on privileged medical data.
While a typical federated learning scenario might involve a population of mobile phones, for example, all with roughly similar computational capabilities and training the same model architecture, some schemes, such as a HeteroFL by Diao et al. 2021, allow for training a single inference model on a variety of devices with vastly different communication and computation capabilities, even going so far as to train local models with different architectures and numbers of parameters, before aggregating the trained parameters to a global inference model.
The primary advantages of federated learning stem from the fact that data stays on the device where it’s generated, and includes, for example, the fact that a training dataset is usually substantially larger than the model being trained, and sending the latter instead of the former can save on bandwidth. Paramount among these advantages is the possibility of privacy, yet it is still possible to infer something about the contents of a private dataset from a model parameter update alone.
The simple example used in McMahan et al. 2017 to explain the vulnerability is a language model trained with a “bag-of-words” input vector, where each input vector corresponds specifically to a single word in a large vocabulary. Each non-zero gradient update for a corresponding word would give eavesdroppers a clue to the presence (and conversely the absence) of the word in the private dataset. More sophisticated attacks have also been demonstrated. As a result there is a wide spectrum of privacy-enhancing techniques that can be incorporated into federated learning, ranging from secure aggregation of updates to training with fully homomorphic encryption. We’ll briefly touch on the most prominent threats to privacy in federated learning and their mitigation in the next section.
The Ongoing Origin Story of Federated Learning
State regulation of data privacy is an emergent area of policy, gaining momentum about 10 to 20 years after it would have matched the development of large segments of the global economy based on personal data collection and analysis. The most prominent regulation of personal data belonging to members of the public is the European General Data Protection Regulation enacted in 2016, more commonly known as GDPR.
It may come as some surprise, given that similar protections limiting corporate surveillance and data collection in the USA are nascent or lacking, but the US White House published an extensive report outlining similar principles in 2012 (pdf), including focused collection, data security and transparency, control over which data are collected, and an expectation that data collected for one purpose would not be used for wildly unrelated purposes.
The California Consumer Privacy Act followed the EU’s GDPR into law two years later in 2018. As a state law, the CCPA is significantly limited in geographic scope by comparison to GDPR, while the act itself has similar aims but a somewhat narrower definition of personal information. Federated learning is one machine learning tool that can be used to give privacy a chance.
The term federated learning was introduced in a 2017 paper by McMahan et al. to describe the training of a model on decentralized data. The authors framed the design strategy for their system under the 2012 White House report on consumer data privacy described above. They suggested two primary use cases for federated learning: image classification, and language models for voice recognition or next word/phrase prediction.
It wasn’t long before the potential attack surfaces associated with distributed training were demonstrated. Work by Phong et al. 2017 and Bhowmick et al. 2018 among others demonstrated that even with access only to the gradient updates or partially trained models returned from a federated learning client to the server, some details describing private data can be inferred. A summary of privacy concerns and their mitigation can be had in this blog post at inpher.io.
The balance between privacy, effectiveness, and efficiency in federated learning spans a broad spectrum. Communications between the server and clients (or solely between decentralized clients) can be encrypted in transport and at rest, but there’s an even more robust option where data and models remain encrypted during training as well. Homomorphic encryption can be used to perform computations on encrypted data, so that (ideally) the outputs can only be decrypted by the stakeholder with the key. Libraries like OpenMined’s PySyft, Microsoft’s SEAL, or TensorFlow Encrypted provide tools for encrypted deep learning that can be applied to federated learning systems.
That’s enough discussion about federated learning, next we'll set up a simple federated learning demonstration in the tutorial section.
Federated ML Tutorial: Federated Learning on the Iris Dataset with the Flower Library
If you run into any trouble getting the code to run for this tutorial and would like to see a working example, try running it in from your browser at this mybinder link and follow the instructions in the readme to launch the federated learning demo.
Now that we have an idea of where and why we might want to use federated learning, let’s take a hands-on look at how we might do so.
There are a number of federated learning libraries to choose from, from the more mainstream Tensorflow Federated with over 1700 stars on GitHub to the popular and privacy-focused PySyft to the research oriented FedJAX. Table 1 contains a reference list of popular federated learning repositories.
| Name | Repository | License/Stars | Focus |
| TF Federated | https://github.com/tensorflow/federated | Apache 2.0 / 1.7k | R&D |
| FedJAX | https://github.com/google/fedjax | Apache 2.0 / 130 | Research |
| Flower | https://github.com/adap/flower | Apache 2.0 / 529 | Usability |
| FedML | https://github.com/FedML-AI/FedML | Apache 2.0 / 839 | Research |
| PySyft | https://github.com/openmined/pysyft | Apache 2.0 / 7.7k | Privacy / R&D |
| IBM federated-learning-lib | https://github.com/IBM/federated-learning-lib | Custom / 244 | Enterprise |
For our tutorial we'll use the Flower library. We chose this library in part because it exemplifies basic federated learning concepts in an accessible way and it is framework agnostic, and in part because we will be using the “iris” dataset included in SciKit-Learn (and the names match).
As Flower is agnostic to the deep learning toolkit used to build models (they have examples for TensorFlow, PyTorch, MXNet, and SciKit-Learn in the documentation), we’ll use PyTorch. From a high-level perspective, we need to set up a server and a client, the latter of which we’ll call twice with different training datasets. Setting up the server is by far the simpler of the tasks at hand, so we’ll start there.
To set up our server, all we need to do is define an evaluation strategy and pass it to the default configuration server in Flower. But first let’s make sure we have a virtual environment set up that has all the dependencies we’ll need. On the Unix command line:
virtualenv flower_env python==python3
source flower_env/bin/activate
pip install flwr==0.17.0
# I'm running this example on a laptop (no gpu)
# so I am installing the cpu only version of PyTorch
# follow the instructions at https://pytorch.org/get-started/locally/
# if you want the gpu option
pip install torch==1.9.1+cpu torchvision==0.10.1+cpu \
-f https://download.pytorch.org/whl/torch_stable.html
pip install scikit-learn==0.24.0
With our virtual environment up and running, we can write a module for spinning up a Flower server to handle federated learning. In the code below we've included argparse to make it easier to experiment with different numbers of training rounds when calling the server module from the command line. We also define a function that generates an evaluation function, which is the only other thing we add to the strategy used by the default configuration of the Flower server.
The contents of our server module file:
import argparse
import flwr as fl
import torch
from pt_client import get_data, PTMLPClient
def get_eval_fn(model):
# This `evaluate` function will be called after every round
def evaluate(parameters: fl.common.Weights):
loss, _, accuracy_dict = model.evaluate(parameters)
return loss, accuracy_dict
return evaluate
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("-r", "--rounds", type=int, default=3,\
help="number of rounds to train")
args = parser.parse_args()
torch.random.manual_seed(42)
model = PTMLPClient(split="val")
strategy = fl.server.strategy.FedAvg( \
eval_fn=get_eval_fn(model),\
)
fl.server.start_server("[::]:8080", strategy=strategy, \
config={"num_rounds": args.rounds})
Take notice of the PTMLPClient called in the code above. This is used by the server module to define the evaluation function, and this class is also the model class used for training and doubles as a federated learning client. We'll define the PTMLPClient next, sub-classing from both Flower's NumPyClient class and the torch.nn.Module class that you’ll already be familiar with if you work with PyTorch.
The NumPyClient class handles communication with the server and requires use to implement the abstract functions set_parameters, get_parameters, fit, and evaluate. The torch.nn.Module class gives us all the convenient functionality of a PyTorch model, mainly the ability to train with the PyTorch Adam optimizer. Our PTMLPClient class will be just over 100 lines of code, so we’ll go through each class function in turn, starting with __init__.
Notice that we are inheriting from two ancestor classes. Inheriting from nn.Module means that we have to make sure to call __init__ from nn.Module using the super command, but Python will let you know right away if you forget to do so. Other than that we initialize three dense layers as matrices (torch.tensor data types) and store some of the information about the training split and model dimensions as class variables.
class PTMLPClient(fl.client.NumPyClient, nn.Module):
def __init__(self, dim_in=4, dim_h=32, \
num_classes=3, lr=3e-4, split="alice"):
super(PTMLPClient, self).__init__()
self.dim_in = dim_in
self.dim_h = dim_h
self.num_classes = num_classes
self.split = split
self.w_xh = nn.Parameter(torch.tensor(\
torch.randn(self.dim_in, self.dim_h) \
/ np.sqrt(self.dim_in * self.dim_h))\
)
self.w_hh = nn.Parameter(torch.tensor(\
torch.randn(self.dim_h, self.dim_h) \
/ np.sqrt(self.dim_h * self.dim_h))\
)
self.w_hy = nn.Parameter(torch.tensor(\
torch.randn(self.dim_h, self.num_classes) \
/ np.sqrt(self.dim_h * self.num_classes))\
)
self.lr = lr
Next we'll define the get_parameters and set_parameters functions of the PTMLPClient class. These functions concatenate all model parameters as a flattened numpy array, which is the data type that Flower's NumPyClient class is expected to return and receive. This fits into the federated learning scheme as the server will send initial parameters to each client (using set_parameters) and expects a set of partially trained weights to be returned (from get_parameters). This pattern occurs once per round. We also initialize the optimizer and loss function in set_parameters.
def get_parameters(self):
my_parameters = np.append(\
self.w_xh.reshape(-1).detach().numpy(), \
self.w_hh.reshape(-1).detach().numpy() \
)
my_parameters = np.append(\
my_parameters, \
self.w_hy.reshape(-1).detach().numpy() \
)
return my_parameters
def set_parameters(self, parameters):
parameters = np.array(parameters)
total_params = reduce(lambda a,b: a*b,\
np.array(parameters).shape)
expected_params = self.dim_in * self.dim_h \
+ self.dim_h**2 \
+ self.dim_h * self.num_classes
assert total_params == expected_params, \
f"expected {expected_params} params," \
f" got {total_params} params"
start = 0
stop = self.dim_in * self.dim_h
self.w_xh = nn.Parameter(torch.tensor(\
parameters[start:stop])\
.reshape(self.dim_in, self.dim_h).float() \
)
start = stop
stop += self.dim_h**2
self.w_hh = nn.Parameter(torch.tensor(\
parameters[start:stop])\
.reshape(self.dim_h, self.dim_h).float() \
)
start = stop
stop += self.dim_h * self.num_classes
self.w_hy = nn.Parameter(torch.tensor(\
parameters[start:stop])\
.reshape(self.dim_h, self.num_classes).float()\
)
self.act = torch.relu
self.optimizer = torch.optim.Adam(self.parameters())
self.loss_fn = nn.CrossEntropyLoss()
Next we'll define our forward pass and a convenience function for getting a loss scalar.
def forward(self, x):
x = self.act(torch.matmul(x, self.w_xh))
x = self.act(torch.matmul(x, self.w_hh))
x = torch.matmul(x, self.w_hy)
return x
def get_loss(self, x, y):
prediction = self.forward(x)
loss = self.loss_fn(prediction, y)
return loss
The last few functions that our client needs are fit and evaluate. For each round, each client initializes its parameters with those supplied to the fit method before training for a few epochs (default is 10 in this case). The evaluate function also sets its parameters before calculating the loss and accuracy on the validation split of the training data.
def fit(self, parameters, config=None, epochs=10):
self.set_parameters(parameters)
x, y = get_data(split=self.split)
x, y = torch.tensor(x).float(), torch.tensor(y).long()
self.train()
for ii in range(epochs):
self.optimizer.zero_grad()
loss = self.get_loss(x, y)
loss.backward()
self.optimizer.step()
loss, _, accuracy_dict = self.evaluate(self.get_parameters())
return self.get_parameters(), len(y), \
{"loss": loss, "accuracy": \
accuracy_dict["accuracy"]}
def evaluate(self, parameters, config=None):
self.set_parameters(parameters)
val_x, val_y = get_data(split="val")
val_x = torch.tensor(val_x).float()
val_y = torch.tensor(val_y).long()
self.eval()
prediction = self.forward(val_x)
loss = self.loss_fn(prediction, val_y).detach().numpy()
prediction_class = np.argmax(\
prediction.detach().numpy(), axis=-1)
accuracy = sklearn.metrics.accuracy_score(\
val_y.numpy(), prediction_class)
return float(loss), len(val_y), \
{"accuracy":float(accuracy)}
Both fit and evaluate in our client class call a function get_data which is just a wrapper for the SciKit-Learn iris dataset. It also splits the data into training and validation sets, and further splits the training dataset in twain (which we call ‘alice’ and ‘bob’) to simulate federated learning with clients that each have their own data.
def get_data(split="all"):
x, y = sklearn.datasets.load_iris(return_X_y=True)
np.random.seed(42); np.random.shuffle(x)
np.random.seed(42); np.random.shuffle(y)
val_split = int(0.2 * x.shape[0])
train_split = (x.shape[0] - val_split) // 2
eval_x, eval_y = x[:val_split], y[:val_split]
alice_x, alice_y = x[val_split:val_split + train_split], \
y[val_split:val_split + train_split]
bob_x, bob_y = x[val_split + train_split:], \
y[val_split + train_split:]
train_x, train_y = x[val_split:], y[val_split:]
if split == "all":
return train_x, train_y
elif split == "alice":
return alice_x, alice_y
elif split == "bob":
return bob_x, bob_y
elif split == "val":
return eval_x, eval_y
else:
print("error: split not recognized.")
return None
Now we just need to populate an if __name__ == "__main__": method at the bottom of our file so that we can run our client code as a module from the command line.
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("-s", "--split", type=str, default="alice",\
help="The training split to use, options are 'alice', 'bob', or 'all'")
args = parser.parse_args()
torch.random.manual_seed(42)
fl.client.start_numpy_client("localhost:8080", \
client=PTMLPClient(split=args.split))
Finally, make sure to import everything needed at the top of the client module.
import argparse
import numpy as np
import sklearn
import sklearn.datasets
import sklearn.metrics
import torch
import torch.nn as nn
from functools import reduce
import flwr as fl
That's actually all we have to implement to run a federated training demo with Flower!
To start a federated training run, first launch the server in its own command line terminal. We saved our server as pt_server.py and our client module as pt_client.py, both in the root of the directory we're working in, so to launch a server and tell it to train for 40 rounds of federated learning we used the following command.
python -m pt_server -r 40
Next open up a fresh terminal to launch your first client with the “alice” training split:
python -m pt_client -s alice
... and a second terminal for your next client with the “bob” training split.
python -m pt_client -s bob
If everything works you should see training start up and a scroll of info in the terminal running the server process.
In our hands this demo achieved just over 96% accuracy in 20 rounds of training. The loss and accuracy curves for the training run look like:

That’s it! Now you can put “Flower library” on your federated learning resume.
Looking to the Future of Federated Learning
A casual observer of the modern world might be persuaded to believe that there “is no such thing as privacy” anymore. These declarations have been primarily directed at the internet (and such declarations have been made since at least 1999) but with the rapid adoption of smart home devices and nosy home robots the reasonable expectation of privacy, even within your own home, may be in danger of catastrophic erosion.
Pay attention to who is making these declarations and you’ll find that many of them have a vested financial interest in the easy pilfering of your data, or may be beholden to those who do. This sort of “no privacy” defeatist attitude is not only wrong, but can be dangerous: loss of privacy allows individuals and groups to be subtly manipulated in ways they may not notice or admit, and people who know they are being watched behave differently.
Bio: Kevin Vu manages Exxact Corp blog and works with many of its talented authors who write about different aspects of Deep Learning.
Original. Reposted with permission.