Semantic Layer: The Backbone of AI-powered Data Experiences
Looking to understand the semantic layer and how it can improve the AI-powered data experience? Read more to learn why a semantic layer can be the backbone of LLMs and reduce hallucinations.
This guide, "Five Essentials of Every Semantic Layer", can help you understand the breadth of the modern semantic layer.
The AI-powered data experience
The evolution of front-end technologies made it possible to embed quality analytics experiences directly into many software products, further accelerating the proliferation of data products and experiences.
And now, with the arrival of large language models, we are living through another step change in technology that will enable many new features and even in the advent of an entirely new class of products across multiple use cases and domains—including data.
LLMs are taking the data consumption layer to the next level with AI-powered data experiences ranging from chatbots answering questions about your business data to AI agents making actions based on the signals and anomalies in data.
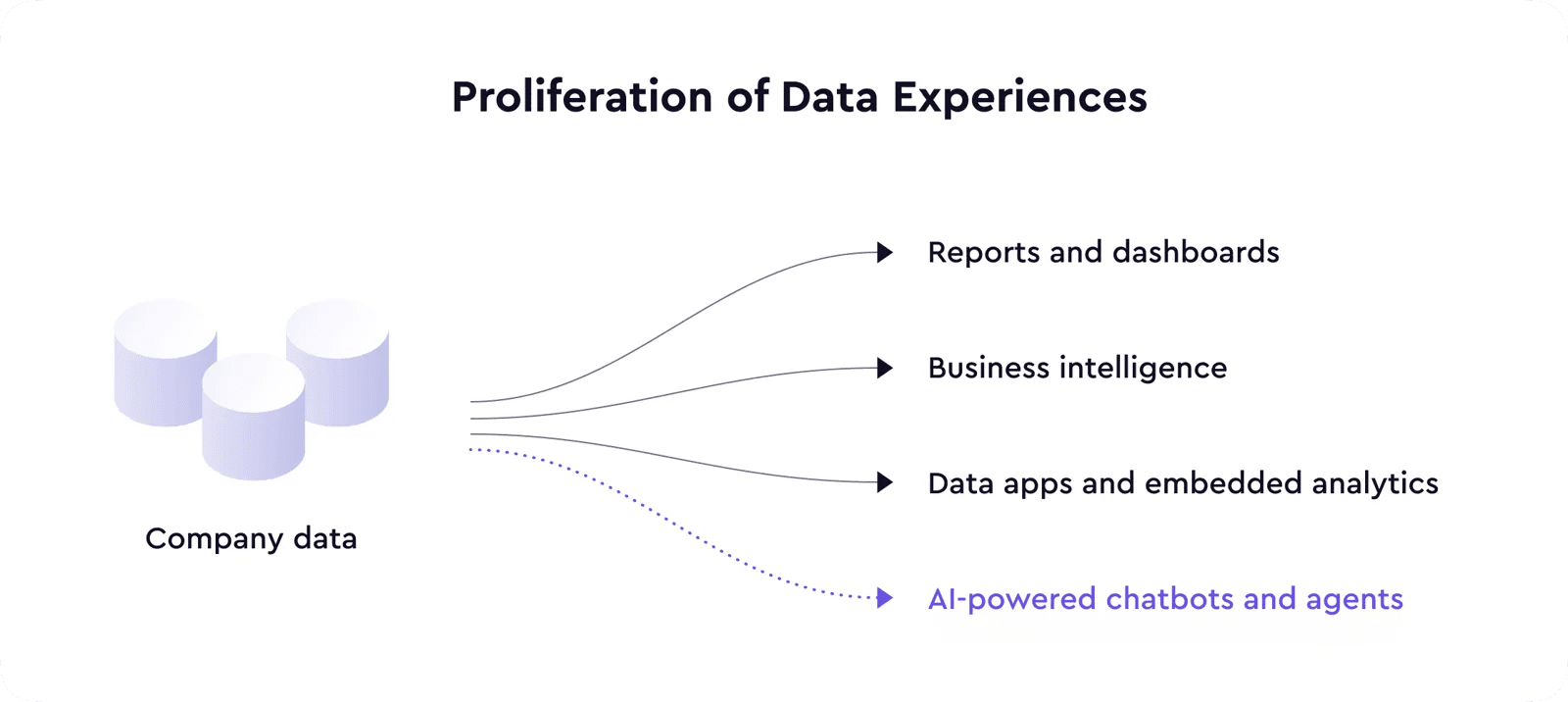
Semantic layer gives context to LLMs
LLMs are indeed a step change, but inevitably, as with every technology, it comes with its limitations. LLMs hallucinate; the garbage in, garbage out problem has never been more of a problem. Let’s think about it like this: when it’s hard for humans to comprehend inconsistent and disorganized data, LLM will simply compound that confusion to produce wrong answers.
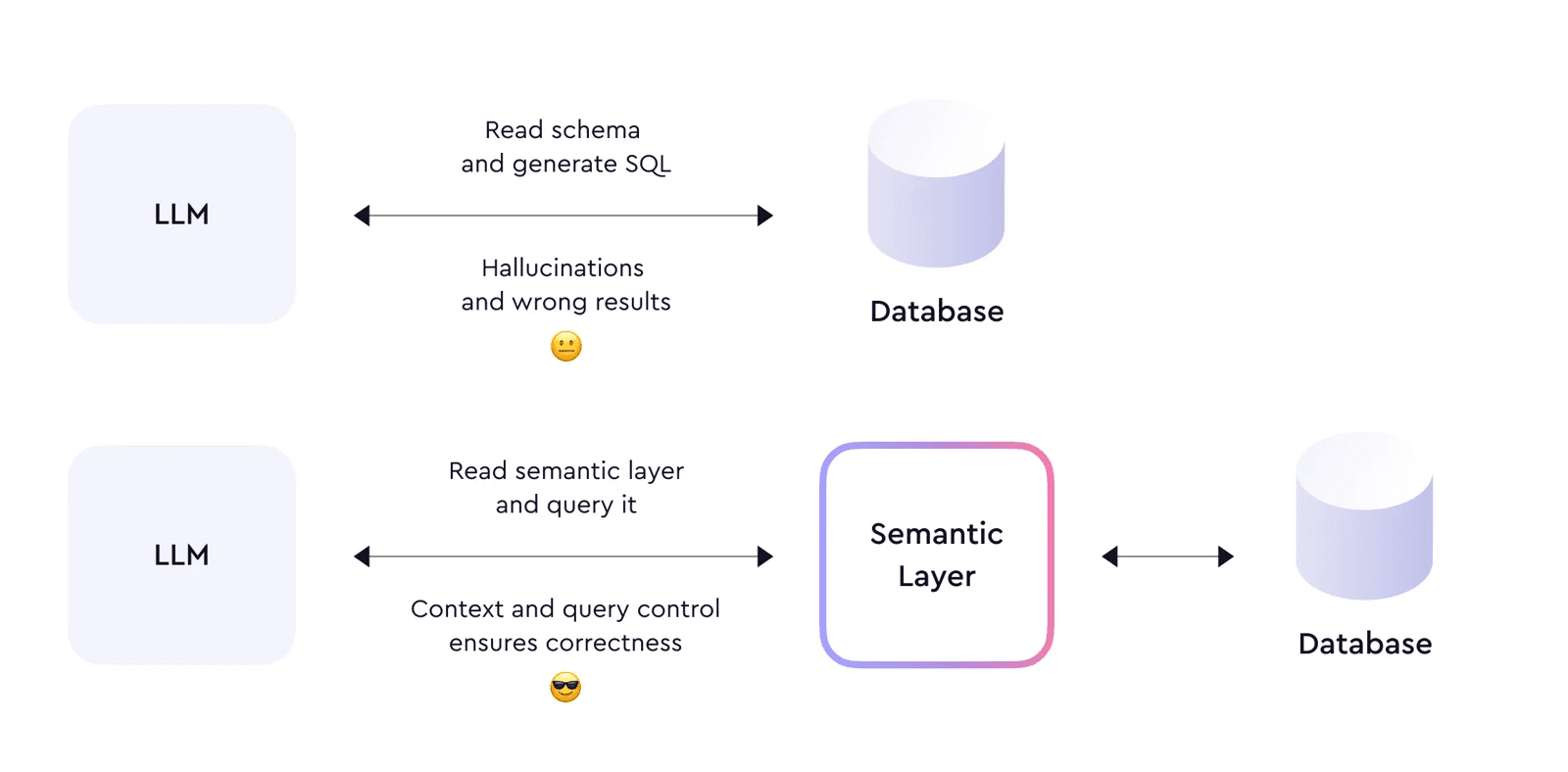
We can’t feed LLM with database schema and expect it to generate the correct SQL. To operate correctly and execute trustworthy actions, it needs to have enough context and semantics about the data it consumes; it must understand the metrics, dimensions, entities, and relational aspects of the data by which it's powered. Basically—LLM needs a semantic layer.
The semantic layer organizes data into meaningful business definitions and then allows for querying these definitions—rather than querying the database directly.
The ‘querying’ application is equally important as that of ‘definitions’ because it enforces LLM to query data through the semantic layer, ensuring the correctness of the queries and returned data. With that, the semantic layer solves the LLM hallucination problem.
Moreover, combining LLMs and semantic layers can enable a new generation of AI-powered data experiences. At Cube, we’ve already witnessed many organizations build custom in-house LLM-powered applications, and startups, like Delphi, build out-of-the-box solutions on top of Cube’s semantic layer (demo here).
On the edge of this developmental forefront, we see Cube being an integral part of the modern AI tech stack as it sits on top of data warehouses, providing context to AI agents and acting as an interface to query data.
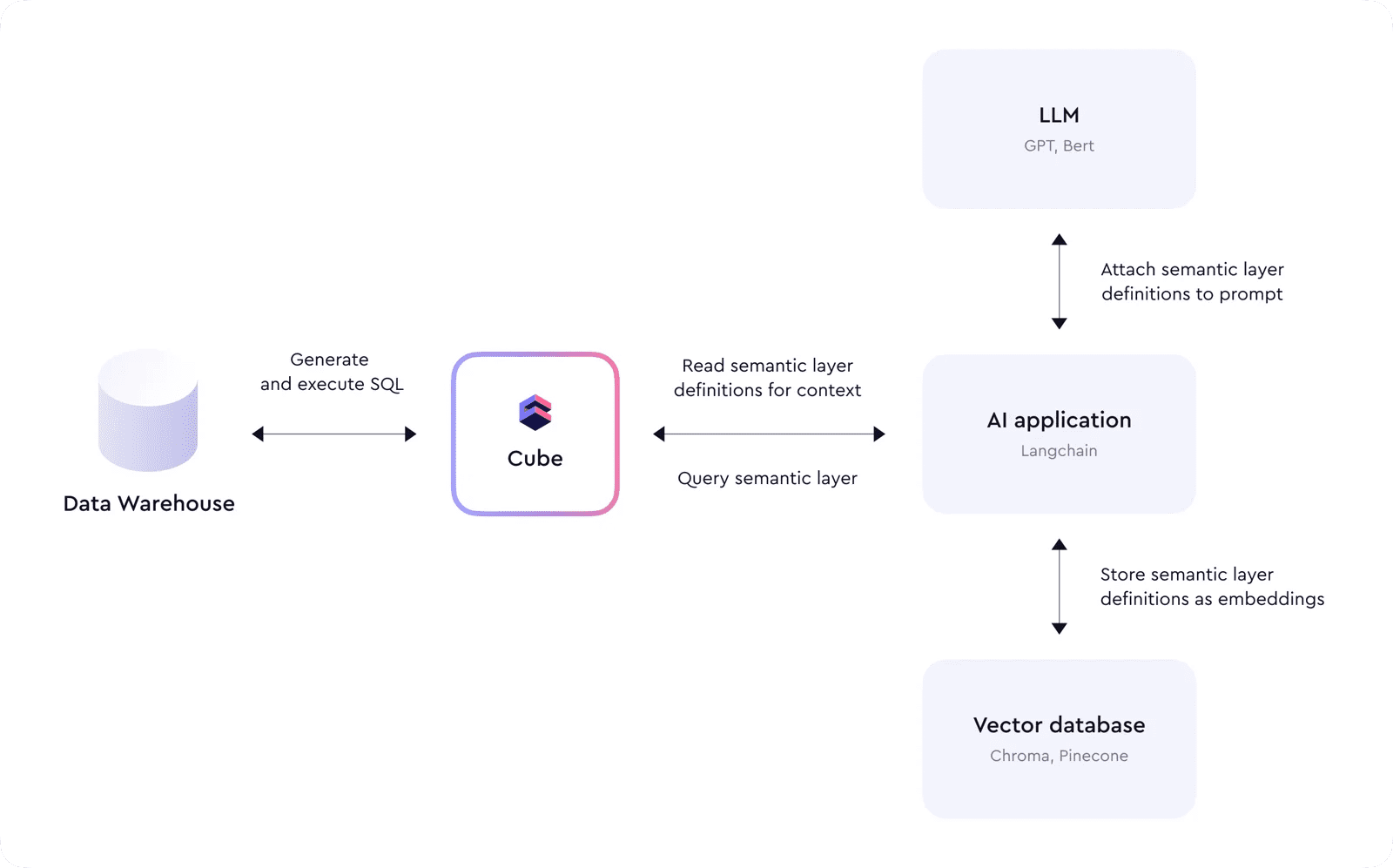
Cube’s data model provides structure and definitions used as a context for LLM to understand data and generate correct queries. LLM doesn’t need to navigate complex joins and metrics calculations because Cube abstracts those and provides a simple interface that operates on the business-level terminology instead of SQL table and column names. This simplification helps LLM to be less error-prone and avoid hallucinations.
For example, an AI-based application would first read Cube’s meta API endpoint, downloading all the definitions of the semantic layer and storing them as embeddings in a vector database. Later, when a user sends a query, these embeddings would be used in the prompt to LLM to provide additional context. LLM would then respond with a generated query to Cube, and the application would execute it. This process can be chained and repeated multiple times to answer complicated questions or create summary reports.
Performance
Regarding response times—when working on complicated queries and tasks, the AI system may need to query the semantic layer multiple times, applying different filters.
So, to ensure reasonable performance, these queries must be cached and not always pushed down to the underlying data warehouses. Cube provides a relational cache engine to build pre-aggregations on top of raw data and implements aggregate awareness to route queries to these aggregates when possible.
Security
And, finally, security and access control should never be an afterthought when building AI-based applications. As mentioned above, generating raw SQL and executing it in a data warehouse may lead to wrong results.
However, AI poses an additional risk: since it cannot be controlled and may generate arbitrary SQL, direct access between AI and raw data stores can also be a significant security vulnerability. Instead, generating SQL through the semantic layer can ensure granular access control policies are in place.
And more...
We have a lot of exciting integrations with the AI ecosystem in store and can’t wait to share them with you. Meanwhile, if you are working on an AI-powered application, consider testing Cube Cloud for free.
Download the guide "Five Essential Features of Every Semantic Layer" to learn more.