3 Crucial Challenges in Conversational AI Development and How to Avoid Them
Developing a conversational AI chatbot requires substantial effort. However, understanding and addressing key challenges in natural language understanding can streamline the development process.

Image by Freepik
Conversational AI refers to virtual agents and chatbots that mimic human interactions and can engage human beings in conversation. Using conversational AI is fast becoming a way of life - from asking Alexa to “find the nearest restaurant” to asking Siri to “create a reminder,” virtual assistants and chatbots are often used to answer consumers’ questions, resolve complaints, make reservations, and much more.
Developing these virtual assistants requires substantial effort. However, understanding and addressing the key challenges can streamline the development process. I have used my first-hand experience in creating a mature chatbot for a recruitment platform as a reference point to explain key challenges and their corresponding solutions.
To build a conversational AI chatbot, developers can use frameworks like RASA, Amazon’s Lex, or Google’s Dialogflow to build chatbots. Most prefer RASA when they plan custom changes or the bot is in the mature stage as it is an open-source framework. Other frameworks are also suitable as a starting point.
The challenges can be classified as three major components of a chatbot.
Natural Language Understanding (NLU) is the ability of a bot to comprehend human dialogue. It performs intent classification, entity extraction, and retrieving responses.
Dialogue Manager is responsible for a set of actions to be performed based on the current and previous set of user inputs. It takes intent and entities as input (as part of the previous conversation) and identifies the next response.
Natural Language Generation (NLG) is the process of generating written or spoken sentences from given data. It frames the response, which is then presented to the user.
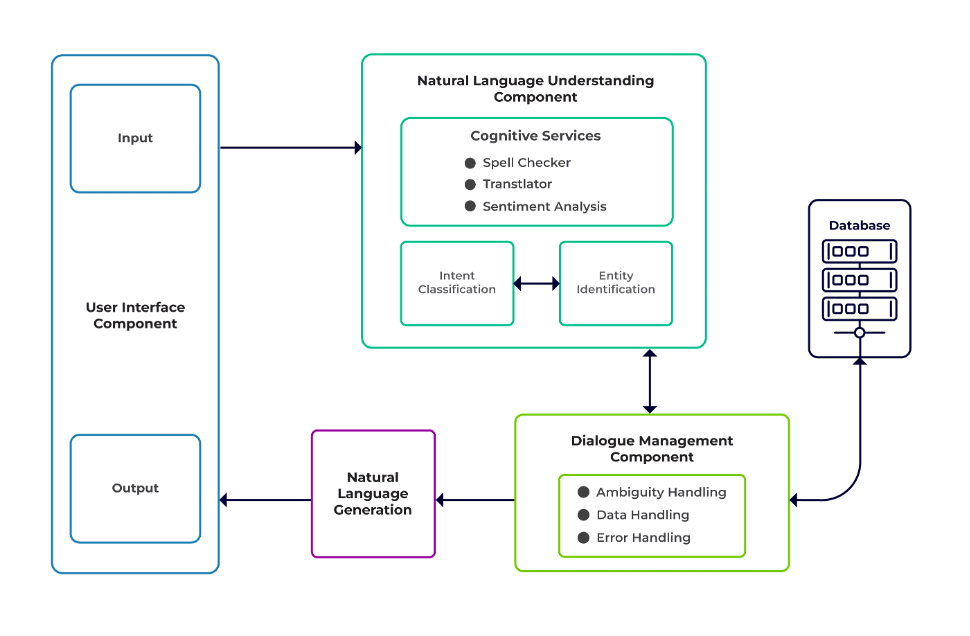
Image from Talentica Software
Challenges in Natural Language Understanding
Insufficient data
When developers replace FAQs or other support systems with a chatbot, they get a decent amount of training data. But the same doesn’t happen when they create the bot from scratch. In such cases, developers generate training data synthetically.
What to do?
A template-based data generator can generate a decent amount of user queries for training. Once the chatbot is ready, project owners can expose it to a limited number of users to enhance training data and upgrade it over a period.
Unfitting model selection
Appropriate model selection and training data are crucial to get the best intent and entity extraction results. Developers usually train chatbots in a specific language and domain, and most of the available pre-trained models are often domain-specific and trained in a single language.
There can be cases of mixed languages as well where people are polyglot. They might enter queries in a mixed language. For instance, in a French-dominated region, people may use a type of English that is a mix of both French and English.
What to do?
Using models trained in multiple languages could reduce the problem. A pre-trained model like LaBSE (Language-agnostic Bert sentence embedding) can be helpful in such cases. LaBSE is trained in more than 109 languages on a sentence similarity task. The model already knows similar words in a different language. In our project, it worked really well.
Improper entity extraction
Chatbots require entities to identify what kind of data the user is searching. These entities include time, place, person, item, date, etc. However, bots can fail to identify an entity from natural language:
Same context but different entities. For instance, bots can confuse a place as an entity when a user types “Name of students from IIT Delhi” and then “Name of students from Bengaluru.”
Scenarios where the entities are mispredicted with low confidence. For example, a bot can identify IIT Delhi as a city with low confidence.
Partial entity extraction by machine learning model. If a user types “students from IIT Delhi,” the model can only identify “IIT” only as an entity instead of “IIT Delhi.”
Single-word inputs having no context can confuse the machine learning models. For example, a word like “Rishikesh” can mean both the name of a person as well as a city.
What to do?
Adding more training examples could be a solution. But there is a limit after which adding more would not help. Moreover, it’s an endless process. Another solution could be to define regex patterns using pre-defined words to help extract entities with a known set of possible values, like city, country, etc.
Models share lower confidence whenever they are not sure about entity prediction. Developers can use this as a trigger to call a custom component that can rectify the low-confident entity. Let’s consider the above example. If IIT Delhi is predicted as a city with low confidence, then the user can always search for it in the database. After failing to find the predicted entity in the City table, the model would proceed to other tables and, eventually, find it in the Institute table, resulting in entity correction.
Wrong intent classification
Every user message has some intent associated with it. Since intents derive the next course of actions of a bot, correctly classifying user queries with intent is crucial. However, developers must identify intents with minimal confusion across intents. Otherwise, there can be cases bugged by confusion. For example, “Show me open positions” vs. “Show me open position candidates”.
What to do?
There are two ways to differentiate confusing queries. Firstly, a developer can introduce sub-intent. Secondly, models can handle queries based on entities identified.
A domain-specific chatbot should be a closed system where it should clearly identify what it is capable of and what it is not. Developers must do the development in phases while planning for domain-specific chatbots. In each phase, they can identify the chatbot’s unsupported features (via unsupported intent).
They can also identify what the chatbot cannot handle in “out of scope” intent. But there could be cases where the bot is confused w.r.t unsupported and out-of-scope intent. For such scenarios, a fallback mechanism should be in place where, if the intent confidence is below a threshold, the model can work gracefully with a fallback intent to handle confusion cases.
Challenges with Dialogue Management
Once the bot identifies the intent of a user’s message, it must send a response back. Bot decides the response based on a certain set of defined rules and stories. For example, a rule can be as simple as utter “good morning” when the user greets “Hi”. However, most often, conversations with chatbots comprise follow-up interaction, and their responses depend on the overall context of the conversation.
What to do?
To handle this, chatbots are fed with real conversation examples called Stories. However, users don’t always interact as intended. A mature chatbot should handle all such deviations gracefully. Designers and developers can guarantee this if they don’t just focus on a happy path while writing stories but also work on unhappy paths.
Challenges in Natural Language Generation
User engagement with chatbots rely heavily on the chatbot responses. Users might lose interest if the responses are too robotic or too familiar. For instance, a user may not like an answer like “You have typed a wrong query” for a wrong input even though the response is correct. The answer here doesn’t match the persona of an assistant.
What to do?
The chatbot serves as an assistant and should possess a specific persona and tone of voice. They should be welcoming and humble, and developers should design conversations and utterances accordingly. The responses should not sound robotic or mechanical. For instance, the bot could say, “Sorry, it seems like I don’t have any details. Could you please re-type your query?” to address a wrong input.
Adding LLMs to a Chatbot System
LLM (Large Language Model) based chatbots like ChatGPT and Bard are game-changing innovations and have improved the capabilities of conversational AIs. They are not only good at making open-ended human-like conversations but can perform different tasks like text summarization, paragraph writing, etc., which could be earlier achieved only by specific models.
One of the challenges with traditional chatbot systems is categorizing each sentence into intents and deciding the response accordingly. This approach is not practical. Responses like “Sorry, I couldn’t get you” are often irritating. Intentless chatbot systems are the way forward, and LLMs can make this a reality.
LLMs can easily achieve state-of-the-art results in general named entity recognition barring certain domain-specific entity recognition. A mixed approach to using LLMs with any chatbot framework can inspire a more mature and robust chatbot system.
With the latest advancements and continuous research in conversational AI, chatbots are getting better every day. Areas like handling complex tasks with multiple intents, such as “Book a flight to Mumbai and arrange for a cab to Dadar,” are getting much attention.
Soon personalized conversations will take place based on the characteristics of the user to keep the user engaged. For example, if a bot finds the user is unhappy, it redirects the conversation to a real agent. Additionally, with ever-increasing chatbot data, deep learning techniques like ChatGPT can automatically generate responses for queries using a knowledge base.
Suman Saurav is a Data Scientist at Talentica Software, a software product development company. He is an alumnus of NIT Agartala with over 8 years of experience designing and implementing revolutionary AI solutions using NLP, Conversational AI, and Generative AI.