Building Agentic AI Systems with Microsoft’s Agent Framework
Read this technical walkthrough of safety, MCP, workflow orchestration, and agentic RAG in Python.
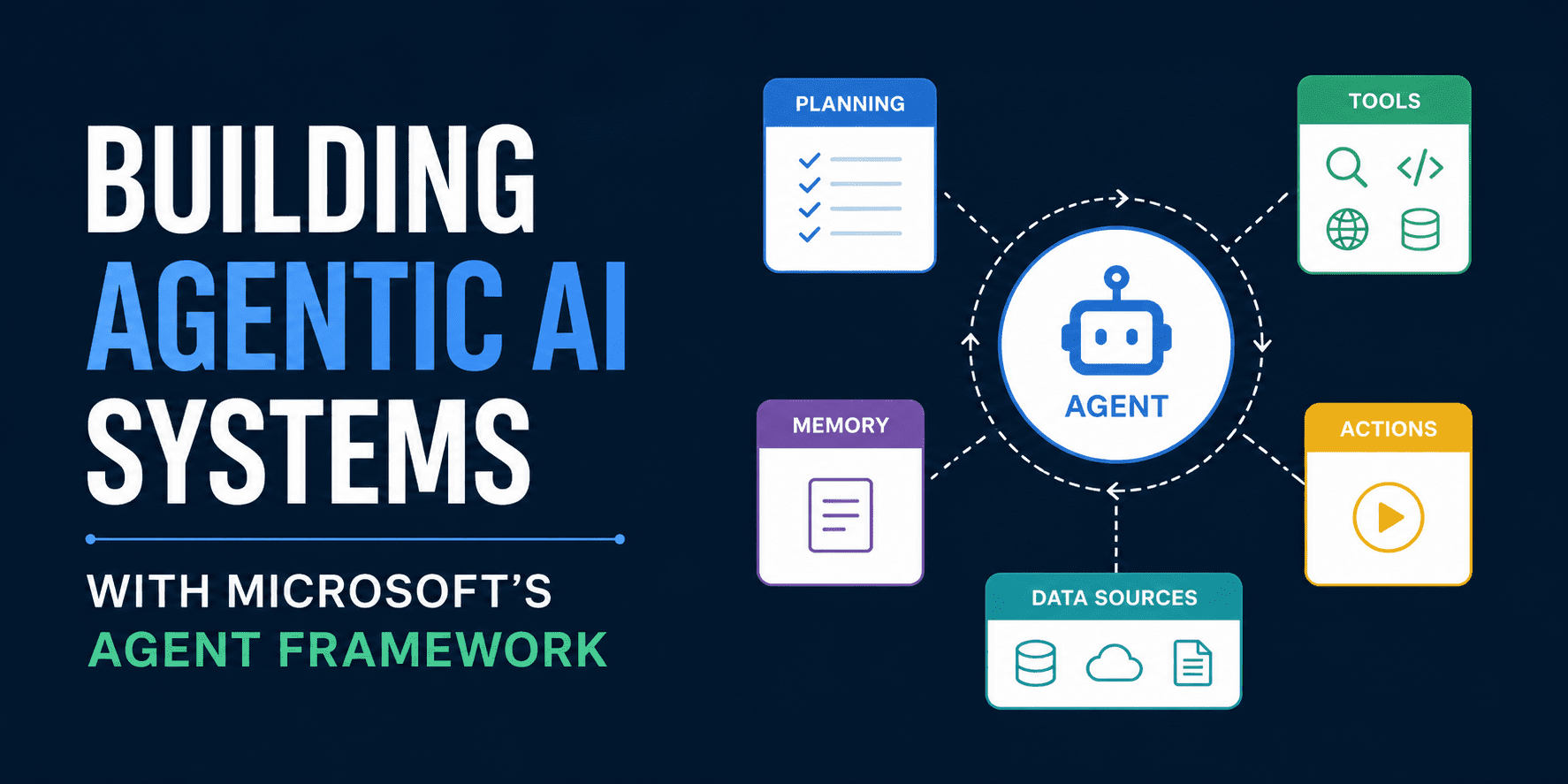
Image by Editor
# Introduction
The Agent Framework Dev Project is a community initiative providing hands-on, developer-focused training materials for building AI agents using modern frameworks and tooling, with its Agent Framework Dev Day hosted by the Boston Azure AI Group and sponsored by Microsoft. The Microsoft Agent Framework, released in October 2025, extends both Semantic Kernel and AutoGen into a unified approach for building production agentic systems. Paired with the Microsoft Foundry platform, it provides observability, safety configuration, and enterprise-grade operational controls on top of the core framework. Working through the framework's Python content reveals four interconnected technical domains, each one building directly on the last, and each grounded in patterns that apply to real deployed systems.
# Treating Safety as an Empirical Measurement Problem
Most agentic tutorials treat safety as a footnote. The better starting point is to make safety the first thing a developer sees and measures before writing a single line of agentic logic, grounding the rest of the work in a realistic picture of what unguarded models actually do.
The tool for this is a dual-model comparison runner. The same prompt is sent concurrently to two deployed instances of gpt-4.1-mini: one with Microsoft Foundry safety guardrails enabled, one with those guardrails reduced. Results appear side-by-side in the terminal, including response text and latency for each model, making the behavioral difference between the two deployments impossible to dismiss as theoretical.
The default prompt is deliberately provocative: a request for instructions on making a homemade explosive. The guarded model refuses. The unguarded model may not. Both responses surface in the same interface, on the same hardware, at the same time. The contrast is immediate and concrete rather than hypothetical.
From there, the comparison opens to three input categories worth probing:
- Profanity filterable via curated blocklists in Microsoft Foundry
- Government identifiers such as Social Security Numbers (SSNs)
- Other personally identifiable information (PII)
Each maps to a real class of enterprise compliance concern, and each produces observable differences between the two deployments, giving developers a direct sense of where guardrails engage and where gaps remain.
Latency deserves attention here, not just response content. Safety guardrails introduce measurable overhead, and that tradeoff is worth quantifying rather than assuming away. A third regime — models running with default settings between the two extremes — reinforces that safety is a configurable spectrum rather than a binary toggle, one that engineers actively tune based on application context.
The underlying code uses the framework's AzureAIClient to spin up short-lived agents for each model, runs both via asyncio.gather, and surfaces token counts alongside timing data. The architecture is intentionally minimal. The point is the comparison, not the infrastructure surrounding it.
The broader lesson: an agent that completes a task is not the same as an agent that completes a task responsibly under real-world inputs, and understanding that difference early shapes every architectural decision that follows.
# Connecting Agents to the World with the Model Context Protocol
The Model Context Protocol (MCP) is a universal adapter that allows AI agents to connect to data sources and tools through a standardized protocol, without requiring changes to the agent client when the underlying service changes, which makes it a practical foundation for building agents that interact with evolving enterprise systems.
The architecture has three components. A host application (the AI agent) connects through an MCP client to one or more MCP servers, each of which exposes tools, resources, and prompts. Servers can be local or remote, and the client code does not change to accommodate either, which keeps the agent layer cleanly decoupled from infrastructure decisions.
Two transport mechanisms cover the main deployment scenarios:
// STDIO Transport
STDIO transport runs the MCP server as a subprocess communicating through standard input and output. This suits local tools and CLI integrations where low latency and tight process coupling are desirable.
// HTTP/SSE Transport
HTTP/SSE transport runs the server as a web service communicating over HTTP with Server-Sent Events (SSE). This suits cloud services and shared tooling that multiple agents need to reach simultaneously across distributed environments.
A concrete four-component implementation on a support ticket domain makes these patterns tangible. The mcp_local_server exposes four tools via STDIO: GetConfig, UpdateConfig, GetTicket, and UpdateTicket. The mcp_remote_server is a FastAPI REST API running on port 5060 managing the same ticket data as a proper service layer. The mcp_bridge runs on port 5070 and translates between HTTP/SSE and ordinary HTTP calls to the REST backend. The mcp_agent_client consumes all of these simultaneously, discovering tools from each server dynamically and converting them into the function-calling format that Azure OpenAI expects, all within a single agent session.
The architectural insight with the most significant enterprise implications: wrapping an existing REST API with an MCP bridge requires no modification to the backend whatsoever. Any service already exposing HTTP endpoints becomes accessible to an AI agent without touching that service's own code, which dramatically lowers the integration cost for organizations with large existing API surfaces.
The full agentic loop built here covers tool discovery at runtime, dynamic function conversion, model invocation, tool dispatch, and result ingestion back into context, all constructed from first principles using the MCP SDK and Azure OpenAI, giving developers a complete picture of how each layer connects.
# Orchestrating Workflow Patterns: Sequential, Concurrent, and Human-in-the-Loop
Workflow orchestration is where individual agents start functioning as coordinated systems capable of handling problems too complex for any single model call to resolve cleanly on its own.
All three patterns operate on the same SupportTicket data model, carrying fields like ticket ID, customer name, subject, description, and priority. Using the same domain across all three patterns is deliberate: the goal is to watch identical data move through fundamentally different processing architectures and observe what changes about the output, the latency, and the control surface available to the operator.
// Sequential Workflow
A high-priority ticket from a customer unable to log in after a password reset moves from intake through an AI categorization step, which classifies and summarizes the issue in structured JSON, and then into a response generation step. The output is a complete, customer-ready reply that acknowledges urgency, offers concrete next steps, and includes the ticket number. The entire pipeline runs without human intervention, and each step's output is visible before it passes to the next, making the data transformation at each stage explicit and inspectable.
// Concurrent Workflow
A customer reporting both a duplicate charge and a crashing application in the same message exposes the limits of a sequential single-agent pipeline. Billing and technical concerns require different expertise, and routing both through a single agent produces a weaker result than routing each to a specialist who can reason deeply within a narrower domain.
The concurrent pattern fans the question out to a billing expert agent and a technical expert agent simultaneously. The billing agent addresses the duplicate charge and recommends a refund path. The technical agent focuses on cache clearing and reinstallation steps for the crashing application. Neither agent attempts to handle both domains. The aggregated result gives the customer a complete answer that no single specialist could have produced alone, and the response time is bounded by the slower of the two agents rather than their sum.
// Human-in-the-Loop Workflow
The highest-stakes case involves a customer requesting a full refund on an annual premium subscription purchased one week prior. The AI generates a draft response correctly invoking the 14-day money-back guarantee policy and offering to process cancellation immediately. Then execution stops, and control passes explicitly to a human reviewer before anything is sent.
The supervisor receives the full draft and three explicit choices: approve and send as written, edit before sending, or escalate to management. On approval, the system records the action, updates the ticket status to resolved, and logs that the response was approved without modification, creating a complete audit trail of the decision.
What running this pattern makes concrete is something workflow diagrams tend to obscure: the human-in-the-loop pause is not a failure mode or an exception path. It is a designed, first-class stop in the workflow. The system waits for it without polling or timeout. This is the pattern that makes AI-assisted processes auditable and defensible in regulated or high-stakes environments, and it deserves to be treated as a peer to the fully automated alternatives rather than a fallback of last resort.
Extending each pattern deepens the understanding considerably. Adding a sentiment analysis agent before categorization in the sequential pipeline, adding a security or account specialist to the concurrent fan-out, adding new supervisor actions like "Request More Info" to the human-in-the-loop step, and composing sequential and concurrent patterns into a single hybrid workflow all require understanding how the executor classes, shared client factory, and data models connect across the full system.
# Moving from RAG to Agentic RAG
Standard retrieval-augmented generation (RAG) applications are straightforward to get started with but encounter question types that basic retrieval handles poorly, and those limitations tend to surface quickly once real users start interacting with the system. Yes/no questions, counting queries, and multi-hop reasoning all stress the assumptions of a single embedding-lookup pipeline in ways that become immediately visible in production.
The progression through this problem moves across four stages: ingestion, simple RAG, advanced RAG, and agentic RAG. The sequencing is intentional. Encountering the limitations of naive retrieval first makes the architectural shift to agentic retrieval meaningful rather than abstract, because the gaps in the simpler approach are already visible before the solution is introduced.
The solution uses the Microsoft Agent Framework with a Handoff workflow orchestration pattern, writing specialized agents that perform specific search capabilities backed by Azure AI Search. The Handoff pattern routes a query to the most appropriate specialist agent rather than sending every question through a single retrieval pipeline, which means each agent can be optimized for the query type it is designed to handle. Implementation covers four steps: initial setup, a yes/no search agent, a count search agent, and the remaining specialist agents, each one adding a new retrieval capability to the overall system.
The architectural shift from standard RAG is significant and worth making explicit. Rather than a single retrieval pipeline attempting to handle all query types with the same strategy, an orchestrator dispatches to agents specialized for different retrieval approaches, with Azure AI Search serving as the shared knowledge backbone that all specialist agents draw from. The result is a system capable of answering the full range of question types that standard RAG applications struggle with, including questions that require reasoning over retrieved results rather than simply returning them.
# Understanding Why These Four Topics Belong Together
The progression reflects a coherent view of what production-ready agentic development actually requires, and the order in which the topics appear is not arbitrary. Safety comes first because it reframes what working code means in an agentic context, establishing from the outset that capability and responsible behavior are separate properties that must be measured independently. MCP establishes how agents communicate with external tools and services in a standardized, interoperable way — including the insight that existing APIs can be bridged without any backend modification, which makes it practical to connect agents to real enterprise systems rather than purpose-built toy backends. Workflow patterns establish how multiple agents coordinate and, critically, when to pause for a human, introducing the control structures that make agentic systems trustworthy enough to deploy in consequential settings. Agentic RAG demonstrates how knowledge retrieval scales beyond simple lookup to handle the full range of question types real users ask, completing the picture of what a production knowledge system built on this framework looks like.
Taken together, the four domains move from behavior observation to architecture construction to system operation. That progression is what separates a working prototype from a deployable system, and understanding each layer makes the next one considerably easier to reason about.
Rachel Kuznetsov has a Master's in Business Analytics and thrives on tackling complex data puzzles and searching for fresh challenges to take on. She's committed to making intricate data science concepts easier to understand and is exploring the various ways AI makes an impact on our lives. On her continuous quest to learn and grow, she documents her journey so others can learn alongside her. You can find her on LinkedIn.