Maximize Performance in Edge AI Applications
This article provides an overview of the strategies for optimizing AI system performance in edge AI deployments.
As AI migrates from the cloud to the Edge, we see the technology being used in an ever-expanding variety of use cases – ranging from anomaly detection to applications including smart shopping, surveillance, robotics, and factory automation. Hence, there is no one-size-fits-all solution. But with the rapid growth of camera-enabled devices, AI has been most widely adopted for analyzing real-time video data to automate video monitoring to enhance safety, improve operational efficiencies, and provide better customer experiences, ultimately gaining a competitive edge in their industries. To better support video analysis, you must understand the strategies for optimizing system performance in edge AI deployments.
Strategies for Optimizing AI System Performance Include
- Selecting the right-sized compute engines to meet or exceed the required performance levels. For an AI application, these compute engines must perform the functions of the entire vision pipeline (i.e., video pre- and post-processing, neural network inferencing).
A dedicated AI accelerator, whether it be discrete or integrated into an SoC (as opposed to running the AI inferencing on a CPU or GPU) may be required.
- Comprehending the difference between throughput and latency; whereby throughput is the rate that data can be processed in a system and latency measures the data processing delay through the system and is often associated with real-time responsiveness. For example, a system can generate image data at 100 frames per second (throughput) but it takes 100ms (latency) for an image to go through the system.
- Considering the ability to easily scale AI performance in the future to accommodate growing needs, changing requirements, and evolving technologies (e.g., more advanced AI models for increased functionality and accuracy). You can accomplish performance scaling using AI accelerators in module format or with additional AI accelerator chips.
Understanding Variable AI Performance Requirements
The actual performance requirements are application dependent. Typically, one can expect that for video analytics, the system must process data streams coming in from cameras at 30-60 frames per second and with a resolution of 1080p or 4k. An AI-enabled camera would process a single stream; an edge appliance would process multiple streams in parallel. In either case, the edge AI system must support the pre-processing functions to transform the camera’s sensor data into a format that matches the input requirements of the AI inferencing section (Figure 1).
Pre-processing functions take in the raw data and perform tasks such as resize, normalization, and color space conversion, before feeding the input into the model running on the AI accelerator. Pre-processing can use efficient image processing libraries like OpenCV to reduce the preprocessing times. Postprocessing involves analyzing the output of the inference. It uses tasks such as non-maximum suppression (NMS interprets the output of most object detection models) and image display to generate actionable insights, such as bounding boxes, class labels, or confidence scores.

Figure 1. For AI model inferencing, the pre- and post-processing functions are typically performed on an applications processor.
The AI model inferencing can have the additional challenge of processing multiple neural network models per frame, depending on the application’s capabilities. Computer vision applications usually involve multiple AI tasks requiring a pipeline of multiple models. Furthermore, one model’s output is often the next model’s input. In other words, models in an application often depend on each other and must be executed sequentially. The exact set of models to execute may not be static and could vary dynamically, even on a frame-by-frame basis.
The challenge of running multiple models dynamically requires an external AI accelerator with dedicated and sufficiently large memory to store the models. Often the integrated AI accelerator inside an SoC is unable to manage the multi-model workload due to constraints imposed by shared memory subsystem and other resources in the SoC.
For example, motion prediction-based object tracking relies on continuous detections to determine a vector which is used to identify the tracked object at a future position. The effectiveness of this approach is limited because it lacks true reidentification capability. With motion prediction, an object’s track can be lost due to missed detections, occlusions, or the object leaving the field of view, even momentarily. Once lost, there is no way to re-associate the object’s track. Adding reidentification solves this limitation but requires a visual appearance embedding (i.e., an image fingerprint). Appearance embeddings require a second network to generate a feature vector by processing the image contained inside the bounding box of the object detected by the first network. This embedding can be used to reidentify the object again, irrespective of time or space. Since embeddings must be generated for each object detected in the field of view, processing requirements increase as the scene becomes busier. Object tracking with reidentification requires careful consideration between performing high-accuracy / high resolution / high-frame rate detection and reserving sufficient overhead for embeddings scalability. One way to solve the processing requirement is to use a dedicated AI accelerator. As mentioned earlier, the SoC’s AI engine can suffer from the lack of shared memory resources. Model optimization can also be used to lower the processing requirement, but it could impact performance and/or accuracy.
Don’t limit AI Performance with System-level Overhead
In a smart camera or edge appliance, the integrated SoC (i.e., host processor) acquires the video frames and performs the pre-processing steps we described earlier. These functions can be performed with the SoC’s CPU cores or GPU (if one is available), but they can also be performed by dedicated hardware accelerators in the SoC (e.g., image signal processor). After these pre-processing steps are completed, the AI accelerator that is integrated into the SoC can then directly access this quantized input from system memory, or in the case of a discrete AI accelerator, the input is then delivered for inference, typically over the USB or PCIe interface.
An integrated SoC can contain a range of computation units, including CPUs, GPUs, AI accelerator, vision processors, video encoders/decoders, image signal processor (ISP), and more. These computation units all share the same memory bus and consequently access to the same memory. Furthermore, the CPU and GPU might also have to play a role in the inference and these units will be busy running other tasks in a deployed system. This is what we mean by system-level overhead (Figure 2).
Many developers mistakenly evaluate the performance of the built-in AI accelerator in the SoC without considering the effect of system-level overhead on total performance. As an example, consider running a YOLO benchmark on a 50 TOPS AI accelerator integrated in an SoC, which mightobtain a benchmark result of 100 inferences/second (IPS). But in a deployed system with all its other computational units active, those 50 TOPS could reduce to something like 12 TOPS and the overall performance would only yield 25 IPS, assuming a generous 25% utilization factor. System overhead is always a factor if the platform is continuously processing video streams. Alternatively, with a discrete AI accelerator (e.g., Kinara Ara-1, Hailo-8, Intel Myriad X), the system-level utilization could be greater than 90% because once the host SoC initiates the inferencing function and transfers the AI model’s input data, the accelerator runs autonomously utilizing its dedicated memory for accessing model weights and parameters.
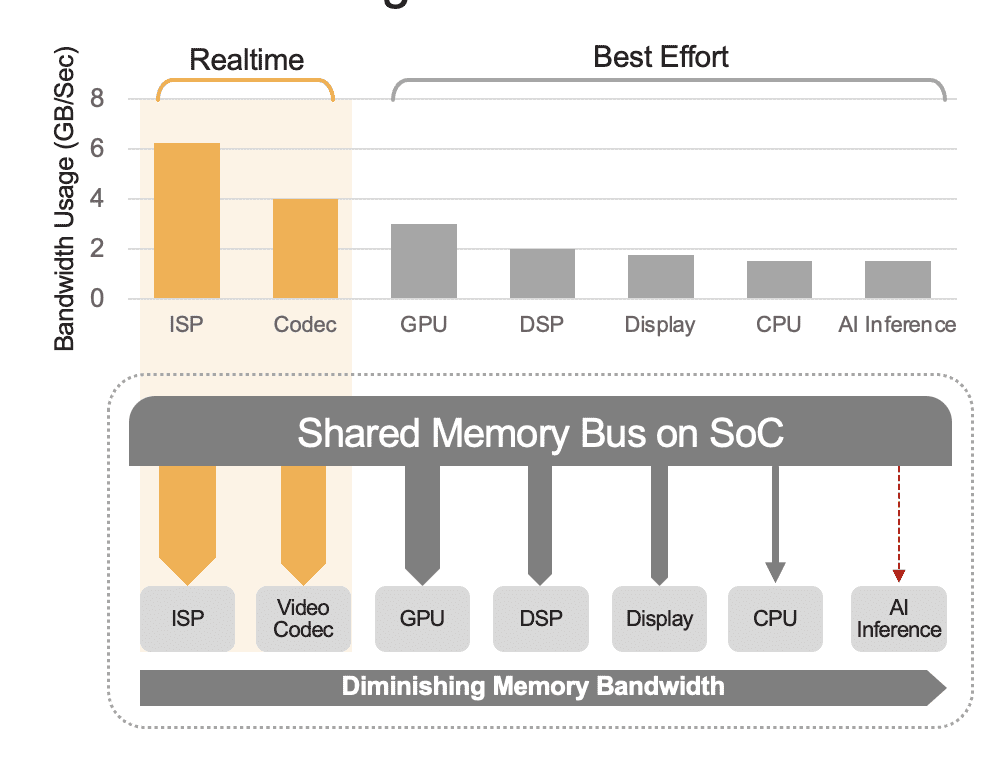
Figure 2. The shared memory bus will govern the system-level performance, shown here with estimated values. Real values will vary based on your application usage model and the SoC’s compute unit configuration.
Video Analytics at the Edge Require Low-latency
Until this point, we’ve discussed AI performance in terms of frames per second and TOPS. But low latency is another important requirement to deliver a system’s real-time responsiveness. For example, in gaming, low latency is critical for a seamless and responsive gaming experience, particularly in motion-controlled games and virtual reality (VR) systems. In autonomous driving systems, low latency is vital for real-time object detection, pedestrian recognition, lane detection, and traffic sign recognition to avoid compromising safety. Autonomous driving systems typically require end-to-end latency of less than 150ms from detection to the actual action. Similarly, in manufacturing, low latency is essential for real-time defect detection, anomaly recognition, and robotic guidance depend on low-latency video analytics to ensure efficient operation and minimize production downtime.
In general, there are three components of latency in a video analytics application (Figure 3):
- Data capture latency is the time from the camera sensor capturing a video frame to the frame’s availability to the analytics system for processing. You can optimize this latency by choosing a camera with a fast sensor and low latency processor, selecting optimal frame rates, and using efficient video compression formats.
- Data transfer latency is the time for captured and compressed video data to travel from the camera to the edge devices or local servers. This includes network processing delays that occur at each end point.
- Data processing latency refers to the time for the edge devices to perform video processing tasks such as frame decompression and analytics algorithms (e.g., motion prediction-based object tracking, face recognition). As pointed out earlier, processing latency is even more important for applications that must run multiple AI models for each video frame.
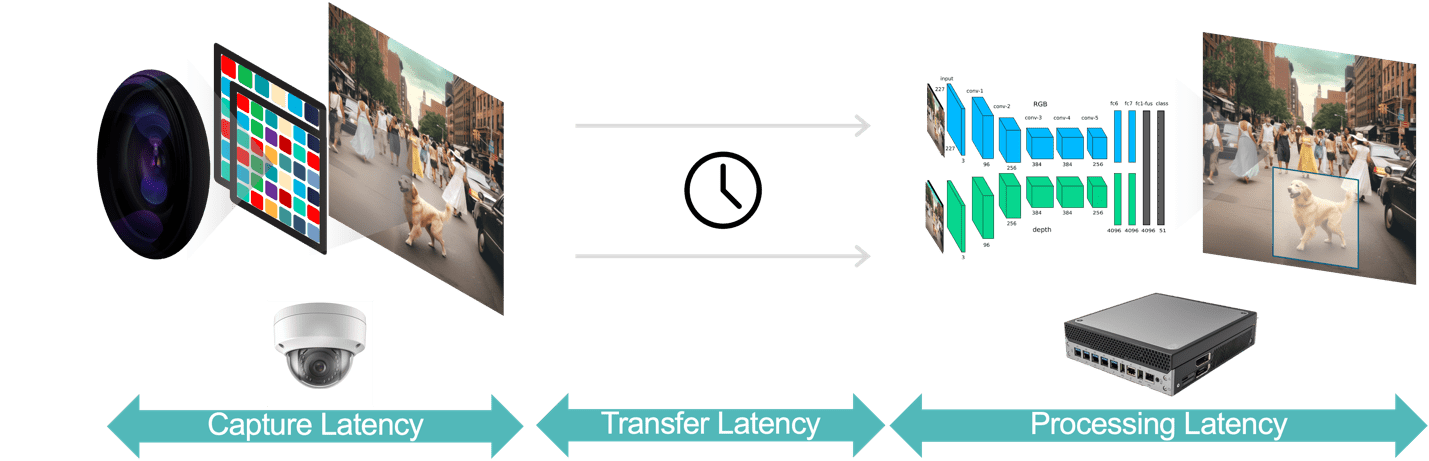
Figure 3. The video analytics pipeline consists of data capture, data transfer and data processing.
The data processing latency can be optimized using an AI accelerator with an architecture designed to minimize data movement across the chip and between compute and various levels of the memory hierarchy. Also, to improve the latency and system-level efficiency, the architecture must support zero (or near zero) switching time between models, to better support the multi-model applications we discussed earlier. Another factor for both improved performance and latency relates to algorithmic flexibility. In other words, some architectures are designed for optimal behavior only on specific AI models, but with the rapidly changing AI environment, new models for higher performance and better accuracy are appearing in what seems like every other day. Therefore, select an edge AI processor with no practical restrictions on model topology, operators, and size.
There are many factors to be considered in maximizing performance in an edge AI appliance including performance and latency requirements and system overhead. A successful strategy should consider an external AI accelerator to overcome the memory and performance limitations in the SoC’s AI engine.
C.H. Chee is an accomplished product marketing and management executive, Chee has extensive experience in promoting products and solutions in the semiconductor industry, focusing on vision-based AI, connectivity and video interfaces for multiple markets including enterprise and consumer. As an entrepreneur, Chee co-founded two video semiconductor start-ups that were acquired by a public semiconductor company. Chee led product marketing teams and enjoys working with a small team that focuses on achieving great results.