Machine Learning on the Edge
Edge ML involves putting ML models on consumer devices where they can independently run inferences without an internet connection, in real-time, and at no cost.

Photo by Alessandro Oliverio
Over the past decade, many companies have shifted to the cloud to store, manage, and process data. This seems an even more promising area for machine learning solutions. By deploying ML models on the cloud, you have access to a plethora of powerful servers that are maintained by third parties. You can generate predictions on the latest graphics processing units (GPUs), tensor processing units (TPUs), and vision processing units (VPUs), without worrying about the initial setup cost, scalability, or hardware maintenance. Moreover, cloud solutions offer access to powerful servers which can make inferences (the process of generating predictions) much faster than on-premises servers.
One may be tempted to believe that it’s cheaper to deploy ML models on the cloud. After all, you do not need to build an infrastructure or maintain everything in-house. You pay only for the time the server was utilized. This, however, couldn't be further from the truth. Cloud costs continue to surge year after year, and most organizations are having a hard time keeping these costs under control. A recent report by Gartner forecasts that end-user spending on public cloud services will reach nearly $500 Billion in 2022 [1].
Big companies like Netflix, Snapchat, Tik Tok, and Pinterest are already spending hundreds of millions of dollars on cloud bills annually [2, 3]. Even for small and medium businesses (SMBs), this cost averages around one million. Machine learning workloads require heavy computation that is expensive on the cloud. Though cloud solutions provide an easy way to manage ML applications, the edge ML has taken off recently.
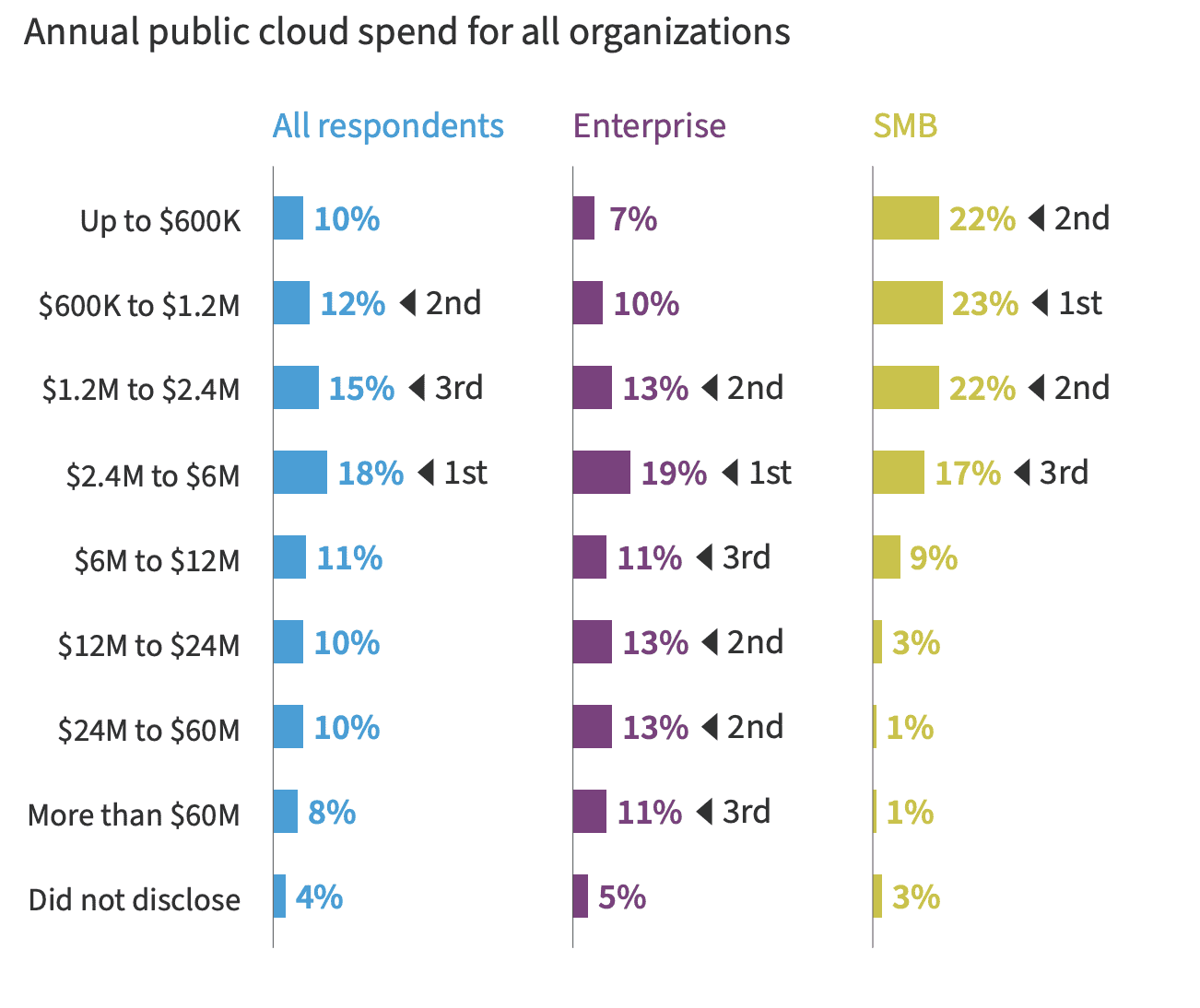
Source: Flexera 2022 State of the Cloud Report
From Cloud ML to Edge ML
To keep their running costs under control, companies have started looking for ways to push as much computation on end-user devices as possible. This means putting ML models on consumer devices where they can independently run inferences without an internet connection, in real-time, and at no cost. Take, for instance, the example of Amazon’s Alexa and Echo, a voice-controlled virtual assistant that uses ML to perform various tasks for you. In September 2020, Amazon released the AZ1 Neural Edge processor that would make Alexa run inferences on the device rather than interacting with the cloud. By moving computation to the edge device, Echo has been able to run twice as faster while also offering privacy benefits since the data is processed locally [4].
Performance
You could build a state-of-the-art ML model with the highest accuracy, but if it takes even a few more milliseconds long to respond, users will go away. Even though deploying ML models to the cloud gives access to high performance hardware, it does not necessarily mean that your application’s latency decreases. Transferring data over the network is usually a bigger overhead than accelerating a model’s performance with special hardware. You could increase the performance of a deep learning model by a few milliseconds, but the data transfer over the network can go up to seconds.
Offline Inference
Cloud computing requires that your application has a stable internet connection for constant data transfer. With edge computing, your application can run where there is no internet connection. This is especially beneficial in areas where the network connection is unreliable, but the application heavily relies on computation. For instance, a heart monitoring application may require real-time inference to predict the health of a patient’s heart. Even if the internet connection breaks down, the model should generate inferences on the edge device.
Data Privacy
Edge computing provides the benefit of data privacy. Users’ personal data is processed in close proximity to the user rather than accumulating in a corporate data center. This also makes it less susceptible to being intercepted over the network. In fact, for many use cases, edge computing is the only way to abide by privacy compliance. Smartphone manufacturers are increasingly incorporating face detection systems to unlock users’ phones. Users wouldn’t want their deeply personal data to be transferred or stored on the cloud.
Cost
Probably the most appealing reason to move towards edge ML is that you do need to pay for the recurring cost of computation on the cloud. If your model stays on the user’s device, all computation is incurred by that device. The model makes use of the processing power of the consumer’s device rather than paying for computation of the cloud.
The Current Limitations of Edge ML
By now you’ve seen how edge ML gives you the competitive edge. However, the current landscape of machine learning infrastructure hints that a lot of work is needed to effectively utilize this edge. State-of-the-art deep learning models are notoriously huge, and deploying these models at edge devices is a whole other challenge. Edge devices encompass all sorts of arbitrary hardware ranging from smartphones to embedded processors and IoT devices. The real challenge is how to compile ML models to run on heterogeneous hardware platforms in an optimized manner. This is a growing area of research where companies are pouring billions of dollars to lead the ML hardware race [5]. Big companies including NVIDIA, Apple, and Tesla are already making their own AI chips optimized to run specific ML models.
Reference
- “Gartner Forecasts Worldwide Public Cloud End-User Spending to Reach Nearly $500 Billion in 2022,” April 19, 2022, Gartner, https://www.gartner.com/en/newsroom/press-releases/2022-04-19-gartner-forecasts-wordwide-public-cloud-end-user-spending-to-reach-nearly-500-billion-in-2022
- Matthew Gooding, “A third of cloud computing spend goes to waste,” March 21, 2022, Tech Monitor https://techmonitor.ai/technology/cloud/cloud-spending-wasted-oracle-computing-aws-azure
- Amir Efrati, Kevin McLaughlin, “As AWS Use Soars, Companies Surprised by Cloud Bills,” February 25, 2019, The Information https://www.theinformation.com/articles/as-aws-use-soars-companies-surprised-by-cloud-bills
- Larry Dignan, “Amazon's Alexa gets a new brain on Echo, becomes smarter via AI and aims for ambience,” September 25, 2020, ZDNet, https://www.zdnet.com/article/amazons-alexa-gets-a-new-brain-on-echo-becomes-smarter-via-ai-and-aims-for-ambience/
- Chip Huyen, “A friendly introduction to machine learning compilers and optimizers,” September 7, 2021, https://huyenchip.com/2021/09/07/a-friendly-introduction-to-machine-learning-compilers-and-optimizers.html
Najia Gul is a Data Scientist at IBM working on building, modelling, deploying, and maintaining ML models. She is also a developer advocate for Data and AI companies, helping them produce content that speaks to the technical audience. Find her personal website here.