Parallel Processing in Prompt Engineering: The Skeleton-of-Thought Technique
Explore how the Skeleton-of-Thought prompt engineering technique enhances generative AI by reducing latency, offering structured output, and optimizing projects.

Image created by Author with Midjourney
Key Takeaways
- Skeleton-of-Thought (SoT) is an innovative prompt engineering technique that minimizes generation latency in Large Language Models (LLMs), enhancing their efficiency
- By creating a skeleton of the answer and then parallelly elaborating on each point, SoT emulates human thinking, promoting more reliable and on-target AI responses
- Implementing SoT in projects can significantly expedite problem-solving and answer generation, especially in scenarios demanding structured and efficient output from AI
SoT is an initial attempt at data-centric optimization for efficiency, and reveal the potential of pushing LLMs to think more like a human for answer quality.
Introduction
Prompt engineering is ground zero in the battle for leveraging the potential of generative AI. By devising effective prompts, and prompt-writing methodologies, we can guide AI in understanding the user's intentions and addressing these intentions effectively. One notable technique in this realm is the Chain-of-Thought (CoT) method, which instructs the generative AI model to elucidate its logic step-by-step while approaching a task or responding to a query. Building upon CoT, a new and promising technique called Skeleton-of-Thought (SoT) has emerged, which aims to refine the way AI processes and outputs information, in the hopes of consequently promoting more reliable and on-target responses.
Understanding Skeleton-of-Thought
The genesis of Skeleton-of-Thought arises from the endeavor to minimize the generation latency inherent in large language models (LLMs). Unlike the sequential decoding approach, SoT emulates human thinking by first generating an answer's skeleton, then filling in the details in parallel, speeding up the inference process significantly. When compared to CoT, SoT not only encourages a structured response but also efficiently organizes the generation process for enhanced performance in generative text systems.
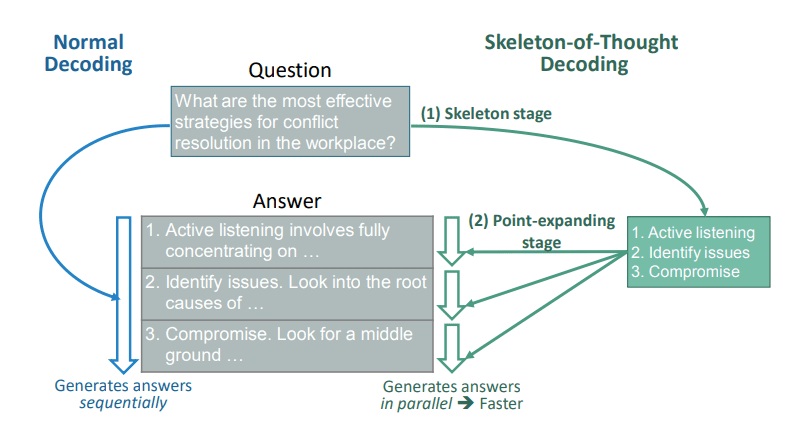
Figure 1: The Skeleton-of-Thought process (from Skeleton-of-Thought: Large Language Models Can Do Parallel Decoding)
Implementing Skeleton-of-Thought
As mentioned above, implementing SoT entails prompting the LLM to create a skeleton of the problem-solving or answer-generating process, followed by parallel elaboration on each point. This method can be particularly useful in scenarios requiring efficient and structured output from AI. For instance, when processing large datasets or answering complex queries, SoT can significantly expedite the response time, providing a streamlined workflow. By integrating SoT into existing prompt engineering strategies, prompt engineers can harness the potential of generative text more effectively, reliably, and quickly.
Perhaps the best way to demonstrate SoT is by example prompts.
Example 1
- Question: Describe the process of photosynthesis.
- Skeleton: Photosynthesis occurs in plants, involves converting light energy to chemical energy, creating glucose and oxygen.
- Point-expansion: Elaborate on light absorption, chlorophyll's role, the Calvin cycle, and oxygen release.
Example 2
- Question: Explain the causes of the Great Depression.
- Skeleton: The Great Depression was caused by stock market crash, bank failures, and reduced consumer spending.
- Point-expansion: Delve into Black Tuesday, the banking crisis of 1933, and the impact of reduced purchasing power.
These examples demonstrate how SoT prompts facilitate a structured, step-by-step approach to answering complex questions. It also shows the workflow: pose a question or define a goal, give the LLM a broad or inclusive answer from which to elaborate supportive reasoning backward from, and then explicitly present those supportive reasoning issues and ask specifically prompt it to do so.
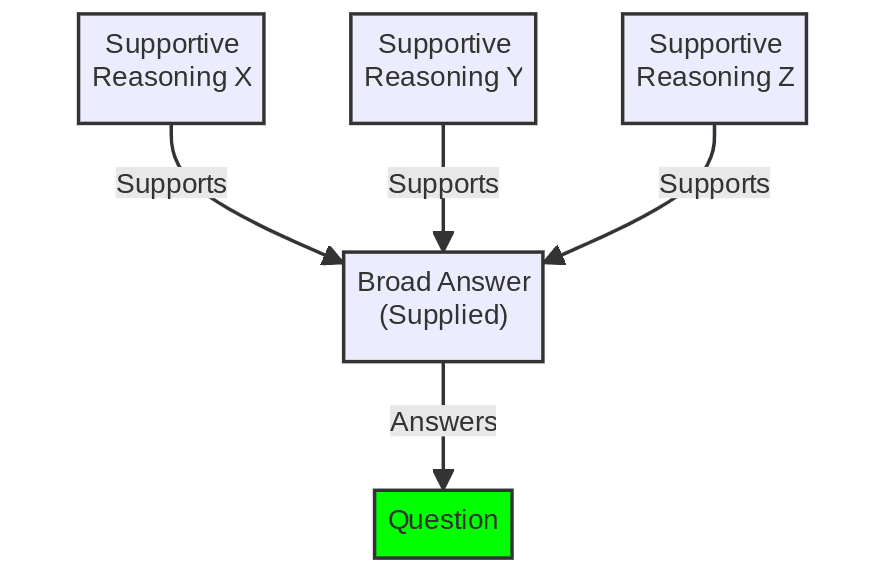
Figure 2: The Skeleton-of-Though simplified process (Image by Author)
While SoT offers a structured approach to problem-solving, it may not be suitable for all scenarios. Identifying the right use cases and understanding its implementation are important. Moreover, the transition from sequential to parallel processing might require a shift in system design or additional resources. However, overcoming these hurdles can unveil the potential of SoT in enhancing the efficiency and reliability of generative text tasks.
Conclusion
The SoT technique, building on the CoT method, offers a new approach in prompt engineering. It not only expedites the generation process but also fosters a structured and reliable output. By exploring and integrating SoT in projects, practitioners can significantly enhance the performance and usability of generative text, driving towards more efficient and insightful solutions.
Matthew Mayo (@mattmayo13) holds a Master's degree in computer science and a graduate diploma in data mining. As Editor-in-Chief of KDnuggets, Matthew aims to make complex data science concepts accessible. His professional interests include natural language processing, machine learning algorithms, and exploring emerging AI. He is driven by a mission to democratize knowledge in the data science community. Matthew has been coding since he was 6 years old.