The Quest for Model Confidence: Can You Trust a Black Box?
This article explores strategies for evaluating the reliability of labels generated by Large Language Models (LLMs). It discusses the effectiveness of different approaches and offers practical insights for various applications.

Image by Author
Large Language Models (LLMs) like GPT-4 and LLaMA2 have entered the [data labeling] chat. LLMs have come a long way and can now label data and take on tasks historically conducted by humans. While obtaining data labels with an LLM is incredibly quick and relatively cheap, there’s still one big issue, these models are the ultimate black boxes. So the burning question is: how much trust should we put in the labels these LLMs generate? In today’s post, we break down this conundrum to establish some fundamental guidelines for gauging the confidence we can have in LLM-labeled data.
Background
The results presented below are from an experiment conducted by Toloka using popular models and a dataset in Turkish. This is not a scientific report but rather a short overview of possible approaches to the problem and some suggestions for how to determine which method works best for your application.
The Big Question
Before we get into the details, here’s the big question: When can we trust a label generated by an LLM, and when should we be skeptical? Knowing this can help us in automated data labeling and can also be useful in other applied tasks like customer support, content generation, and more.
The Current State of Affairs
So, how are people tackling this issue now? Some directly ask the model to spit out a confidence score, some look at the consistency of the model’s answers over multiple runs, while others examine the model’s log probabilities. But are any of these approaches reliable? Let’s find out.
The Rule of Thumb
What makes a “good” confidence measure? One simple rule to follow is that there should be a positive correlation between the confidence score and the accuracy of the label. In other words, a higher confidence score should mean a higher likelihood of being correct. You can visualize this relationship using a calibration plot, where the X and Y axes represent confidence and accuracy, respectively.
Experiments and Their Results
Approach 1: Self-Confidence
The self-confidence approach involves asking the model about its confidence directly. And guess what? The results weren’t half bad! While the LLMs we tested struggled with the non-English dataset, the correlation between self-reported confidence and actual accuracy was pretty solid, meaning models are well aware of their limitations. We got similar results for GPT-3.5 and GPT-4 here.
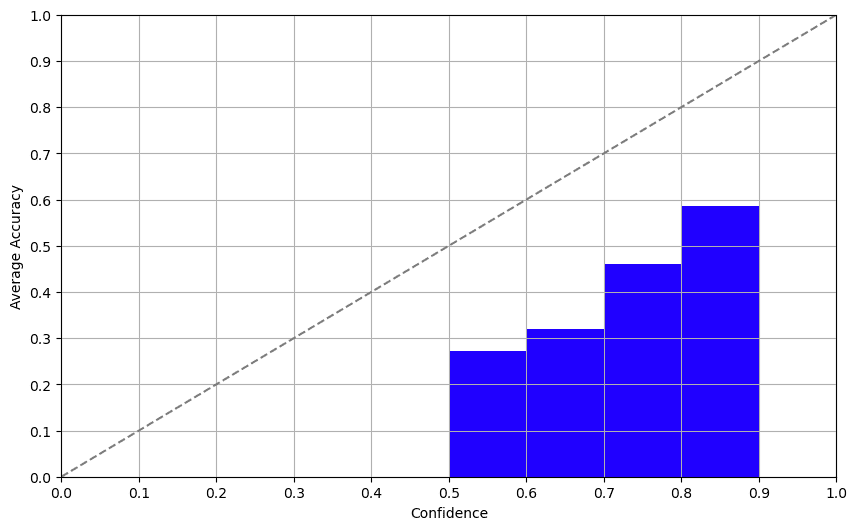
Approach 2: Consistency
Set a high temperature (~0.7–1.0), label the same item several times, and analyze the consistency of the answers, for more details, see this paper. We tried this with GPT-3.5 and it was, to put it lightly, a dumpster fire. We prompted the model to answer the same question multiple times and the results were consistently erratic. This approach is as reliable as asking a Magic 8-Ball for life advice and should not be trusted.
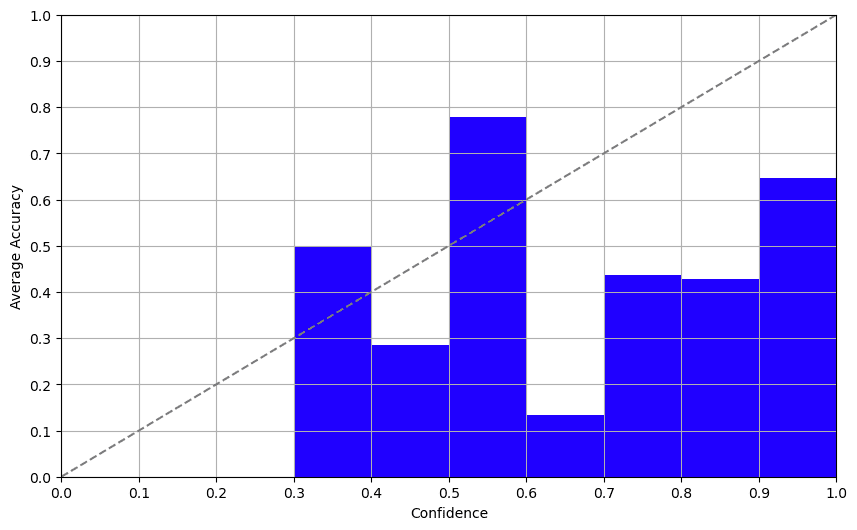
Approach 3: Log Probabilities
Log probabilities offered a pleasant surprise. Davinci-003 returns logprobs of the tokens in the completion mode. Examining this output, we got a surprisingly decent confidence score that correlated well with accuracy. This method offers a promising approach to determining a reliable confidence score.
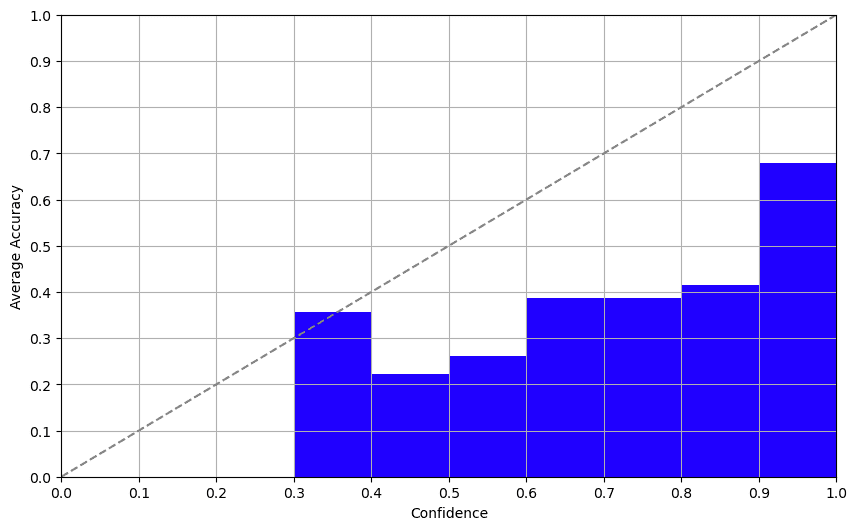
The Takeaway
So, what did we learn? Here it is, no sugar-coating:
- Self-Confidence: Useful, but handle with care. Biases are reported widely.
- Consistency: Just don’t. Unless you enjoy chaos.
- Log Probabilities: A surprisingly good bet for now if the model allows you to access them.
The exciting part? Log probabilities appear to be quite robust even without fine-tuning the model, despite this paper reporting this method to be overconfident. There is room for further exploration.
Future Avenues
A logical next step could be to find a golden formula that combines the best parts of each of these three approaches, or explores new ones. So, if you’re up for a challenge, this could be your next weekend project!
Wrapping Up
Alright, ML aficionados and newbies, that’s a wrap. Remember, whether you’re working on data labeling or building the next big conversational agent - understanding model confidence is key. Don’t take those confidence scores at face value and make sure you do your homework!
Hope you found this insightful. Until next time, keep crunching those numbers and questioning those models.
Ivan Yamshchikov is a professor of Semantic Data Processing and Cognitive Computing at the Center for AI and Robotics, Technical University of Applied Sciences Würzburg-Schweinfurt. He also leads the Data Advocates team at Toloka AI. His research interests include computational creativity, semantic data processing and generative models.